[Python] Pandasで欠損値(NaN)をカウントする方法
PandasはPythonのデータ操作ライブラリで、データフレーム内の欠損値(NaN)を簡単にカウントすることができます。
欠損値をカウントするには、データフレームのメソッドであるisna()やisnull()を使用し、これにsum()を組み合わせます。
例えば、df.isna().sum()を使用すると、各列ごとの欠損値の数を取得できます。
また、df.isna().sum().sum()を使うと、データフレーム全体の欠損値の総数を得ることができます。
欠損値(NaN)のカウント方法
Pandasを使用してデータを扱う際、欠損値(NaN)は避けて通れない問題です。
ここでは、Pandasを用いて欠損値をカウントする方法を詳しく解説します。
DataFrame全体の欠損値をカウントする
DataFrame全体の欠損値をカウントする方法を見ていきましょう。
isnull()メソッドの使い方
isnull()メソッドは、DataFrame内の欠損値をTrueで示すブール値のDataFrameを返します。
以下はその基本的な使い方です。
import pandas as pd
# サンプルデータの作成
data = {'A': [1, 2, None], 'B': [None, 2, 3], 'C': [1, None, 3]}
df = pd.DataFrame(data)
# 欠損値をTrueで示す
null_df = df.isnull()
print(null_df) A B C
0 False True False
1 False False True
2 True False Falseこの例では、isnull()メソッドを使用して、DataFrame内の欠損値をTrueで示す新しいDataFrameを作成しています。
sum()メソッドとの組み合わせ
sum()メソッドを組み合わせることで、欠損値の数を簡単にカウントできます。
# 列ごとの欠損値の数をカウント
null_count = df.isnull().sum()
print(null_count)A 1
B 1
C 1
dtype: int64この例では、各列における欠損値の数をカウントしています。
特定の列や行の欠損値をカウントする
特定の列や行に絞って欠損値をカウントする方法を紹介します。
列ごとの欠損値カウント
特定の列における欠損値をカウントするには、以下のようにします。
# 列 'A' の欠損値の数をカウント
null_count_A = df['A'].isnull().sum()
print(f"Column 'A' の欠損値の数: {null_count_A}")Column 'A' の欠損値の数: 1この例では、列 ‘A’ における欠損値の数をカウントしています。
行ごとの欠損値カウント
行ごとの欠損値をカウントするには、以下のようにします。
# 行ごとの欠損値の数をカウント
null_count_rows = df.isnull().sum(axis=1)
print(null_count_rows)0 1
1 1
2 1
dtype: int64この例では、各行における欠損値の数をカウントしています。
欠損値の割合を計算する
データセット全体に対する欠損値の割合を計算する方法を見ていきます。
欠損値の割合を求める方法
欠損値の割合を求めるには、欠損値の数をデータの総数で割ります。
# 列ごとの欠損値の割合を計算
null_ratio = df.isnull().mean()
print(null_ratio)A 0.333333
B 0.333333
C 0.333333
dtype: float64この例では、各列における欠損値の割合を計算しています。
欠損値の割合を可視化する
欠損値の割合を可視化することで、データの状態を直感的に理解できます。
import matplotlib.pyplot as plt
# 欠損値の割合を棒グラフで可視化
null_ratio.plot(kind='bar')
plt.title('欠損値の割合')
plt.xlabel('列')
plt.ylabel('割合')
plt.show()このコードを実行すると、各列における欠損値の割合を示す棒グラフが表示されます。
可視化することで、どの列に欠損値が多いかを一目で確認できます。
欠損値のカウントにおける応用例
欠損値のカウントは、データの品質を評価し、適切な前処理を行うための重要なステップです。
ここでは、欠損値のカウントを応用した具体的な例を紹介します。
欠損値の多い列を特定する
データセット内で欠損値の多い列を特定することは、データの品質を評価する上で重要です。
以下の方法で、欠損値の割合が一定以上の列を特定できます。
import pandas as pd
# サンプルデータの作成
data = {'A': [1, None, None], 'B': [None, 2, 3], 'C': [1, None, None]}
df = pd.DataFrame(data)
# 欠損値の割合を計算
null_ratio = df.isnull().mean()
# 欠損値の割合が50%以上の列を特定
high_null_columns = null_ratio[null_ratio > 0.5].index
print(f"欠損値の多い列: {list(high_null_columns)}")欠損値の多い列: ['A', 'C']この例では、欠損値の割合が50%以上の列を特定しています。
これにより、データの品質が低い列を見つけ出し、適切な処理を行うことができます。
欠損値の多い行を削除する
データ分析の前に、欠損値の多い行を削除することで、データの品質を向上させることができます。
以下の方法で、欠損値の割合が一定以上の行を削除します。
import pandas as pd
# サンプルデータの作成
data = {'A': [1, None, None], 'B': [None, 2, 3], 'C': [1, None, None]}
df = pd.DataFrame(data)
# 欠損値の割合が50%以上の行を削除
df_cleaned = df.dropna(thresh=int(df.shape[1] * 0.5))
print(df_cleaned) A B C
1 NaN 2.0 NaN
2 NaN 3.0 NaNこの例では、欠損値の割合が50%以上の行を削除しています。
これにより、データの品質を保ちながら、分析に適したデータセットを作成できます。
欠損値の多いデータセットの分析
欠損値が多いデータセットを分析する際には、欠損値のパターンを理解し、適切な処理を行うことが重要です。
以下の方法で、欠損値のパターンを可視化し、分析を行います。
import seaborn as sns
import matplotlib.pyplot as plt
# サンプルデータの作成
data = {'A': [1, None, None], 'B': [None, 2, 3], 'C': [1, None, None]}
df = pd.DataFrame(data)
# 欠損値のヒートマップを作成
sns.heatmap(df.isnull(), cbar=False, cmap='viridis')
plt.title('欠損値のヒートマップ')
plt.show()このコードを実行すると、欠損値のパターンを示すヒートマップが表示されます。
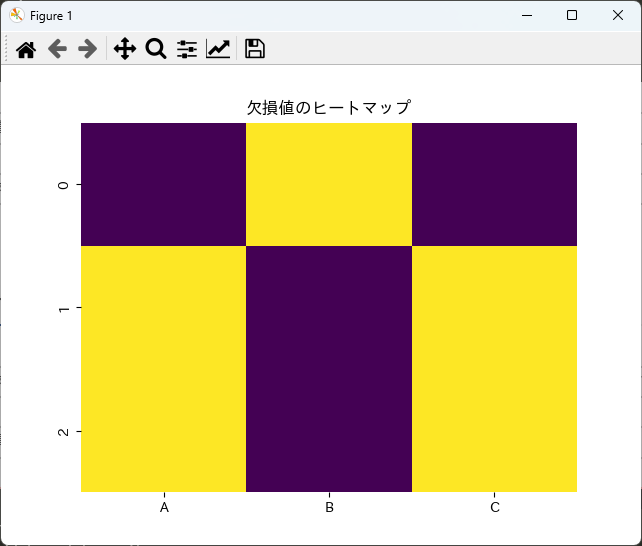
ヒートマップを使用することで、どの部分に欠損値が集中しているかを視覚的に把握でき、データの前処理に役立てることができます。
欠損値のカウントに関する注意点
欠損値のカウントはデータ分析において重要なステップですが、いくつかの注意点があります。
ここでは、欠損値のカウントに関連するデータ型や前処理について解説します。
欠損値のカウントとデータ型の関係
欠損値のカウントを行う際には、データ型に注意が必要です。
特に、数値型と文字列型では欠損値の扱いが異なる場合があります。
- 数値型の欠損値: Pandasでは、数値型の欠損値は通常
NaNとして扱われます。
isnull()メソッドを使用することで、これらの欠損値を正確にカウントできます。
- 文字列型の欠損値: 文字列型のデータでは、空文字列や特定の文字列(例:’N/A’, ‘null’)が欠損値として扱われることがあります。
これらはisnull()メソッドでは自動的に欠損値と認識されないため、事前に適切な置換処理が必要です。
import pandas as pd
# サンプルデータの作成
data = {'A': [1, 2, None], 'B': ['N/A', 'valid', 'null']}
df = pd.DataFrame(data)
# 文字列型の欠損値をNaNに置換
df['B'] = df['B'].replace(['N/A', 'null'], [None, None])
# 欠損値のカウント
null_count = df.isnull().sum()
print(null_count)A 1
B 2
dtype: int64この例では、文字列型の欠損値をNoneに置換することで、isnull()メソッドで正確にカウントできるようにしています。
欠損値のカウントとデータの前処理
欠損値のカウントは、データの前処理において重要な役割を果たします。
前処理の段階で欠損値を適切に扱うことで、分析結果の精度を向上させることができます。
- 欠損値の補完: 欠損値を補完する方法として、平均値や中央値での補完、前後の値での補完(前方補完・後方補完)などがあります。
補完方法を選択する際には、データの特性を考慮することが重要です。
- 欠損値の削除: 欠損値が多い場合や、補完が難しい場合には、欠損値を含む行や列を削除することも選択肢の一つです。
ただし、データの損失を最小限に抑えるために、削除の基準を慎重に設定する必要があります。
# 欠損値を平均値で補完
df['A'] = df['A'].fillna(df['A'].mean())
# 欠損値を含む行を削除
df_cleaned = df.dropna()
print(df_cleaned) A B
1 2.0 validこの例では、数値型の欠損値を平均値で補完し、文字列型の欠損値を含む行を削除しています。
データの前処理において、欠損値の扱いを適切に行うことで、分析の精度を高めることができます。
まとめ
欠損値のカウントは、データ分析において重要なステップであり、データの品質を評価するために欠かせません。
この記事では、Pandasを用いた欠損値のカウント方法や応用例、注意点について詳しく解説しました。
これらの知識を活用して、データの前処理を効率的に行い、分析の精度を向上させましょう。
![[Python] fractionの使い方 – 分数(有理数)の計算の効率化](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46597.png)
![[Python] 平方根を計算する方法](https://af-e.net/wp-content/uploads/2024/08/thumbnail-9537.png)
![[Python] 円周率(π)の値を画面に表示する方法](https://af-e.net/wp-content/uploads/2024/08/thumbnail-9536.png)
![[Python] 円周率(π)を使って計算する方法](https://af-e.net/wp-content/uploads/2024/08/thumbnail-9535.png)
![[Python] 累乗根の計算を行う方法](https://af-e.net/wp-content/uploads/2024/08/thumbnail-9534.png)
![[Python] 立方根を計算する方法](https://af-e.net/wp-content/uploads/2024/08/thumbnail-9533.png)
![[Python] 二つの四角形の当たり判定を行う方法](https://af-e.net/wp-content/uploads/2024/08/thumbnail-9532.png)
![[Python] 円同士(2D)・球同士(3D)の当たり判定の作り方](https://af-e.net/wp-content/uploads/2024/08/thumbnail-9531.png)
![[Python] サイコロを降って偶数なら「当たり!」となる当たり判定を作る方法](https://af-e.net/wp-content/uploads/2024/08/thumbnail-9530.png)
![[Python] ゲーム作りで必要な当たり判定アルゴリズムの作り方](https://af-e.net/wp-content/uploads/2024/08/thumbnail-9529.png)
![[Python] pygameで当たり判定を実装する方法](https://af-e.net/wp-content/uploads/2024/08/thumbnail-9528.png)
![[Python] 2D・3D空間における当たり判定の書き方を解説](https://af-e.net/wp-content/uploads/2024/08/thumbnail-9527.png)