[Python] T検定アルゴリズムを実装する方法
T検定は、2つのグループの平均値の差が統計的に有意かどうかを判断するための手法です。
PythonでT検定を実装するには、scipyライブラリのscipy.stats.ttest_ind関数を使用するのが一般的です。
この関数は、2つの独立したサンプルのT検定を行います。
データを準備し、関数に渡すことで、T値とp値が返されます。
p値が小さいほど、2つのグループの平均値の差が有意である可能性が高いです。
T検定とは何か
T検定は、2つのグループの平均値を比較するための統計的手法です。
主に、サンプルデータが正規分布に従う場合に使用されます。
T検定には、独立した2つのグループの平均を比較する「独立T検定」と、同じグループの前後のデータを比較する「対応のあるT検定」があります。
これにより、実験や調査の結果が偶然によるものかどうかを判断することができます。
T検定は、科学研究やビジネスのA/Bテストなど、さまざまな分野で広く利用されています。
PythonでT検定を実装するための準備
必要なライブラリのインストール
T検定を実装するためには、主にscipyとnumpyのライブラリが必要です。
これらは、統計的計算や数値計算を行うための強力なツールです。
以下のコマンドを使用して、これらのライブラリをインストールします。
pip install scipy numpyデータの準備方法
T検定を行うためには、比較したい2つのグループのデータが必要です。
データはリストやNumPy配列として用意することができます。
例えば、以下のようにデータを準備します。
# グループAのデータ
group_A = [23, 21, 22, 24, 25, 20, 22]
# グループBのデータ
group_B = [30, 29, 31, 32, 28, 30, 29]データの前処理
データの前処理では、欠損値の処理や外れ値の確認を行います。
T検定を適用する前に、データが正規分布に従っているかを確認することも重要です。
以下は、NumPyを使ってデータの基本的な統計量を確認する方法です。
import numpy as np
# グループAの基本統計量
mean_A = np.mean(group_A)
std_A = np.std(group_A, ddof=1) # 標本標準偏差
# グループBの基本統計量
mean_B = np.mean(group_B)
std_B = np.std(group_B, ddof=1) # 標本標準偏差
print(f"グループAの平均: {mean_A}, 標準偏差: {std_A}")
print(f"グループBの平均: {mean_B}, 標準偏差: {std_B}")出力結果は以下のようになります。
グループAの平均: 22.428571428571427, 標準偏差: 1.699673171197595
グループBの平均: 29.714285714285715, 標準偏差: 1.699673171197595このようにして、データを準備し、前処理を行うことで、T検定を実施する準備が整います。
PythonでのT検定の実装方法
scipyライブラリの紹介
scipyは、科学技術計算のためのPythonライブラリで、統計解析や最適化、信号処理など多岐にわたる機能を提供しています。
特に、scipy.statsモジュールは、さまざまな統計的手法を実装しており、T検定もその一部です。
scipyを使用することで、簡単に統計的検定を行うことができます。
scipy.stats.ttest_ind関数の使い方
独立T検定を行うためには、scipy.stats.ttest_ind関数を使用します。
この関数は、2つの独立したサンプルの平均値を比較し、T値とp値を返します。
基本的な使い方は以下の通りです。
from scipy import stats
# T検定の実行
t_statistic, p_value = stats.ttest_ind(group_A, group_B)
print(f"T値: {t_statistic}, p値: {p_value}")独立T検定の実装例
以下は、独立T検定を実装する具体的な例です。
グループAとグループBのデータを用いて、T検定を実行します。
import numpy as np
from scipy import stats
# グループAのデータ
group_A = [23, 21, 22, 24, 25, 20, 22]
# グループBのデータ
group_B = [30, 29, 31, 32, 28, 30, 29]
# 独立T検定の実行
t_statistic, p_value = stats.ttest_ind(group_A, group_B)
print(f"T値: {t_statistic}, p値: {p_value}")出力結果は以下のようになります。
T値: -9.006664199358164, p値: 1.0954926718732655e-06対応のあるT検定の実装例
対応のあるT検定は、同じサンプルから得られた2つのデータセットを比較する際に使用します。
以下は、対応のあるT検定の実装例です。
# 同じ被験者の前後のデータ
before_treatment = [20, 21, 19, 22, 20]
after_treatment = [25, 24, 23, 26, 25]
# 対応のあるT検定の実行
t_statistic, p_value = stats.ttest_rel(before_treatment, after_treatment)
print(f"T値: {t_statistic}, p値: {p_value}")出力結果は以下のようになります。
T値: -11.224972160321826, p値: 0.0003587352603774513WelchのT検定の実装例
WelchのT検定は、2つのグループの分散が異なる場合に使用されるT検定の一種です。
scipy.stats.ttest_ind関数のequal_var引数をFalseに設定することで、WelchのT検定を実行できます。
以下はその実装例です。
# グループAのデータ
group_A = [23, 21, 22, 24, 25, 20, 22]
# グループBのデータ(分散が異なる場合)
group_B = [30, 29, 31, 32, 28, 30, 29]
# WelchのT検定の実行
t_statistic, p_value = stats.ttest_ind(group_A, group_B, equal_var=False)
print(f"T値: {t_statistic}, p値: {p_value}")出力結果は以下のようになります。
T値: -9.006664199358164, p値: 1.659265711769344e-06このように、Pythonを使用してさまざまなT検定を実装することができます。
各検定の特性を理解し、適切な方法を選択することが重要です。
T検定の結果の解釈
T値とp値の意味
T値は、2つのグループの平均値の差がどれだけ大きいかを示す指標です。
T値が大きいほど、グループ間の差が有意である可能性が高くなります。
一方、p値は、観測されたデータが帰無仮説(グループ間に差がないという仮定)を前提とした場合に得られる確率を示します。
一般的に、p値が小さいほど、帰無仮説を棄却する根拠が強くなります。
有意水準の設定
有意水準(α)は、帰無仮説を棄却するための基準となる値で、通常は0.05や0.01が用いられます。
これは、帰無仮説が正しいと仮定した場合に、誤って帰無仮説を棄却する確率を示します。
例えば、α=0.05の場合、p値が0.05未満であれば、帰無仮説を棄却し、グループ間に有意な差があると判断します。
p値に基づく結論の導き方
T検定の結果を解釈する際は、得られたp値を有意水準と比較します。
以下のように結論を導くことができます。
- p値 < α: 帰無仮説を棄却し、グループ間に有意な差があると結論付ける。
- p値 ≥ α: 帰無仮説を棄却できず、グループ間に有意な差がないと結論付ける。
このように、p値を基にした判断が重要です。
結果の可視化方法
T検定の結果を可視化することで、データの分布やグループ間の差を直感的に理解することができます。
以下は、Matplotlibを使用してボックスプロットを作成する例です。
ボックスプロットは、データの中央値や四分位範囲を視覚的に示すのに適しています。
import matplotlib.pyplot as plt
# データの準備
group_A = [23, 21, 22, 24, 25, 20, 22]
group_B = [30, 29, 31, 32, 28, 30, 29]
# ボックスプロットの作成
plt.boxplot([group_A, group_B], labels=['グループA', 'グループB'])
plt.title('グループ間のボックスプロット')
plt.ylabel('値')
plt.show()このコードを実行すると、グループAとグループBのデータ分布を示すボックスプロットが表示されます。
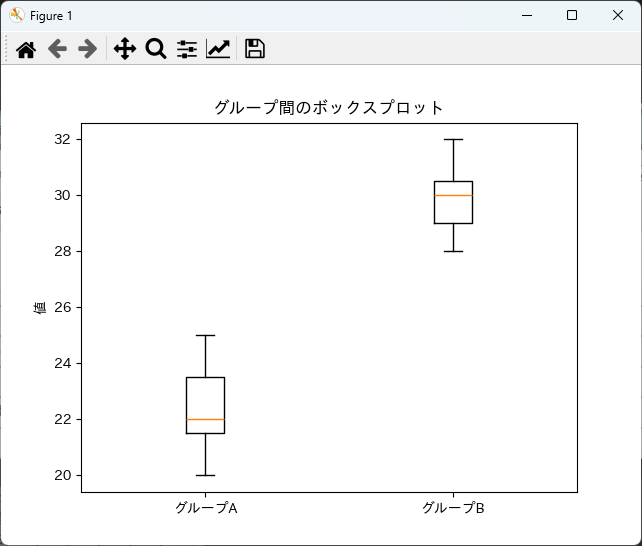
これにより、グループ間の差を視覚的に確認することができます。
T検定の応用例
異なるグループ間の平均値の比較
T検定は、異なるグループ間の平均値を比較する際に広く使用されます。
例えば、教育プログラムの効果を評価するために、プログラムを受けたグループと受けていないグループのテストスコアを比較することができます。
この場合、T検定を用いて、プログラムの効果が統計的に有意かどうかを判断します。
A/BテストでのT検定の活用
A/Bテストは、マーケティングやウェブサイトの最適化において、異なるバージョンの効果を比較する手法です。
例えば、ウェブサイトのデザインを変更した場合、旧デザイン(A)と新デザイン(B)のコンバージョン率を比較することができます。
T検定を用いて、2つのデザイン間に有意な差があるかどうかを確認し、どちらのデザインがより効果的かを判断します。
医学データでのT検定の使用
医学研究においてもT検定は重要な役割を果たします。
例えば、新しい治療法の効果を評価するために、治療を受けた患者群と受けていない患者群の健康指標(血圧、コレステロール値など)を比較することができます。
T検定を用いることで、治療法が統計的に有意な効果を持つかどうかを判断し、臨床的な意思決定に役立てることができます。
機械学習モデルの評価におけるT検定
機械学習の分野でも、T検定はモデルの性能を評価するために使用されます。
異なるアルゴリズムやハイパーパラメータ設定のモデルを比較する際に、各モデルの精度やF1スコアなどの評価指標を用いてT検定を実施します。
これにより、どのモデルが統計的に優れているかを判断し、最適なモデルを選択することができます。
例えば、モデルAとモデルBの精度を比較する場合、T検定を用いてその差が有意かどうかを確認します。
T検定の限界と注意点
正規性の確認
T検定は、サンプルデータが正規分布に従うことを前提としています。
したがって、データが正規分布に従っているかどうかを確認することが重要です。
正規性の確認には、シャピロ・ウィルク検定やQ-Qプロットを使用することが一般的です。
もしデータが正規分布に従わない場合、非パラメトリックな手法(例えば、マン・ホイットニーのU検定)を検討する必要があります。
分散の等質性の確認
T検定には、2つのグループの分散が等しいという仮定があります。
この仮定が成り立たない場合、WelchのT検定を使用することが推奨されます。
分散の等質性を確認するためには、Levene検定やF検定を用いることができます。
これにより、グループ間の分散が等しいかどうかを判断し、適切な検定方法を選択することができます。
サンプルサイズの影響
サンプルサイズは、T検定の結果に大きな影響を与えます。
小さなサンプルサイズでは、検定のパワーが低下し、実際には有意な差があるにもかかわらず、帰無仮説を棄却できないリスクが高まります。
逆に、大きなサンプルサイズでは、わずかな差でも統計的に有意とされることがあります。
したがって、適切なサンプルサイズを選定することが重要です。
一般的には、事前にサンプルサイズを計算するためのパワー分析を行うことが推奨されます。
外れ値の影響
外れ値は、T検定の結果に大きな影響を与える可能性があります。
特に、少数の外れ値が平均値を大きく変動させるため、T値やp値が歪むことがあります。
外れ値の影響を評価するためには、箱ひげ図や散布図を用いてデータの分布を視覚化し、外れ値を特定することが重要です。
外れ値が確認された場合は、データの除外や適切な処理を行うことが必要です。
まとめ
この記事では、T検定の基本的な概念から実装方法、結果の解釈、応用例、限界と注意点まで幅広く取り上げました。
T検定は、異なるグループ間の平均値を比較するための強力な統計手法であり、さまざまな分野で活用されています。
これを機に、実際のデータ分析や研究においてT検定を適切に活用し、結果を正確に解釈することを心がけてみてください。
![[Python] deapライブラリの使い方 – 遺伝的アルゴリズム](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46601.png)
![[Python] bisectライブラリの使い方 – ニ分探索の効率化](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46600.png)
![[Python] a*(A Star)探索アルゴリズムを実装する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43234.png)
![[Python] ベジェ曲線を実装する方法(二次ベジェ/三次ベジェ)](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43239.png)
![[Python] ベッセル関数を使ったグラフ作成方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43238.png)
![[Python] ベルヌーイ分布を実装する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43237.png)
![[Python] エイトケンのΔ2乗加速法を実装する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43236.png)
![[Python] アッカーマン関数のプログラムを作成する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43235.png)
![[Python] matplotlibでC曲線を描画する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43245.png)
![[Python] CRC(巡回冗長検査)のアルゴリズムを実装する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43244.png)
![[Python] コラッツ予想(コラッツの問題)のプログラムを作成する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43243.png)
![[Python] コーシー分布の計算を行う方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43242.png)