[Python] deapライブラリの使い方 – 遺伝的アルゴリズム
DEAPは、Pythonで遺伝的アルゴリズム(GA)や進化戦略を簡単に実装できるライブラリです。
主に「個体(Individual)」「集団(Population)」「適応度(Fitness)」などの進化計算の基本要素を提供します。
基本的な流れは、まずcreatorで個体や適応度を定義し、toolboxで交叉、突然変異、選択などの操作を設定します。
次に、algorithms.eaSimpleなどの進化アルゴリズムを使って世代を進め、最適解を探索します。
DEAPライブラリとは
DEAP(Distributed Evolutionary Algorithms in Python)は、Pythonで進化的アルゴリズムを実装するための強力なライブラリです。
遺伝的アルゴリズム、遺伝的プログラミング、進化戦略など、さまざまな進化的手法を簡単に利用できるように設計されています。
DEAPは、柔軟性と拡張性を兼ね備えており、ユーザーは独自の適応度関数や遺伝子表現を定義することができます。
また、マルチオブジェクティブ最適化や並列処理の機能もサポートしており、複雑な問題に対しても効果的にアプローチできます。
これにより、研究者や開発者は、さまざまな最適化問題に対して迅速に実験を行い、結果を得ることが可能です。
DEAPは、オープンソースであり、活発なコミュニティによってサポートされています。
DEAPの基本的な使い方
DEAPを使用して遺伝的アルゴリズムを実装するための基本的な手順を以下に示します。
これにより、個体の定義からアルゴリズムの実行までの流れを理解できます。
個体(Individual)の定義
個体は、遺伝的アルゴリズムにおける解の候補を表します。
DEAPでは、個体をリストやタプルで表現し、creatorモジュールを使用して適応度を持たせることができます。
以下は、個体を定義するサンプルコードです。
from deap import base, creator, tools
# 適応度を最大化する個体を定義
creator.create("FitnessMax", base.Fitness, weights=(1.0,))
creator.create("Individual", list, fitness=creator.FitnessMax)
# 個体の生成
individual = creator.Individual([1, 2, 3, 4, 5])
print(individual)[1, 2, 3, 4, 5]適応度(Fitness)の設定
適応度は、個体の良さを評価するための指標です。
DEAPでは、適応度関数を定義し、個体に対して評価を行います。
以下は、適応度関数の例です。
def evaluate(individual):
return sum(individual), # 適応度は個体の要素の合計集団(Population)の生成
集団は、複数の個体から構成されます。
DEAPでは、toolsモジュールを使用して集団を生成できます。
以下は、集団を生成するサンプルコードです。
# 集団の生成
population = [creator.Individual([1, 2, 3, 4, 5]) for _ in range(10)]
print(population)[[1, 2, 3, 4, 5], [1, 2, 3, 4, 5], ...] # 10個の個体が生成される交叉(Crossover)の実装
交叉は、2つの親個体から新しい子個体を生成するプロセスです。
DEAPでは、cxBlendやcxTwoPointなどの交叉手法が用意されています。
以下は、2点交叉の例です。
# 交叉の実装
parent1 = creator.Individual([1, 2, 3])
parent2 = creator.Individual([4, 5, 6])
tools.cxTwoPoint(parent1, parent2)
print(parent1, parent2)[4, 5, 3] [1, 2, 6] # 親個体が交叉されて新しい個体が生成される突然変異(Mutation)の実装
突然変異は、個体の遺伝子をランダムに変更するプロセスです。
DEAPでは、mutFlipBitやmutGaussianなどの突然変異手法が用意されています。
以下は、ビット反転の例です。
# 突然変異の実装
individual = creator.Individual([1, 0, 1])
tools.mutFlipBit(individual, 0.1) # 10%の確率でビットを反転
print(individual)[1, 1, 1] # 突然変異後の個体選択(Selection)の実装
選択は、次世代の個体を選ぶプロセスです。
DEAPでは、selTournamentやselRouletteなどの選択手法が用意されています。
以下は、トーナメント選択の例です。
# 選択の実装
selected = tools.selTournament(population, 3) # 3個体をトーナメント選択
print(selected)[[1, 2, 3], [4, 5, 6], ...] # 選択された個体評価関数の作成
評価関数は、個体の適応度を計算するための関数です。
以下は、評価関数を集団に適用する例です。
# 評価関数の適用
fitnesses = list(map(evaluate, population))
for ind, fit in zip(population, fitnesses):
ind.fitness.values = fitアルゴリズムの実行
最後に、遺伝的アルゴリズムを実行します。
以下は、基本的なアルゴリズムの流れを示すサンプルコードです。
# アルゴリズムの実行
for gen in range(10): # 10世代の進化
offspring = tools.selTournament(population, len(population) // 2) # 親の選択
offspring = list(map(lambda ind: tools.clone(ind), offspring)) # 複製
for child1, child2 in zip(offspring[::2], offspring[1::2]):
if random.random() < 0.5: # 50%の確率で交叉
tools.cxTwoPoint(child1, child2)
for mutant in offspring:
if random.random() < 0.2: # 20%の確率で突然変異
tools.mutFlipBit(mutant, 0.1)
population[:] = offspring # 新しい集団に更新このようにして、DEAPを使用して遺伝的アルゴリズムを実装することができます。
各ステップを適切に設定することで、さまざまな最適化問題に対応可能です。
DEAPを使った遺伝的アルゴリズムの実装例
ここでは、DEAPを使用した具体的な遺伝的アルゴリズムの実装例をいくつか紹介します。
これにより、さまざまな最適化問題に対するアプローチを理解できます。
1次元最適化問題の例
1次元最適化問題では、特定の関数の最大値または最小値を求めます。
以下は、単純な関数の最大化を行う例です。
import random
from deap import base, creator, tools
# 適応度を最大化する個体を定義
creator.create("FitnessMax", base.Fitness, weights=(1.0,))
creator.create("Individual", list, fitness=creator.FitnessMax)
# 評価関数の定義
def evaluate(individual):
return sum(individual), # 合計を最大化
# 集団の生成
toolbox = base.Toolbox()
toolbox.register("random_value", random.uniform, -10, 10)
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.random_value, n=5)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.register("evaluate", evaluate)
toolbox.register("mate", tools.cxBlend, alpha=0.5)
toolbox.register("mutate", tools.mutGaussian, mu=0, sigma=1, indpb=0.2)
toolbox.register("select", tools.selTournament, tournsize=3)
# アルゴリズムの実行
population = toolbox.population(n=50)
for gen in range(10):
for ind in population:
ind.fitness.values = toolbox.evaluate(ind)
offspring = toolbox.select(population, len(population))
offspring = list(map(toolbox.clone, offspring))
for child1, child2 in zip(offspring[::2], offspring[1::2]):
if random.random() < 0.5:
toolbox.mate(child1, child2)
del child1.fitness.values
del child2.fitness.values
for mutant in offspring:
if random.random() < 0.2:
toolbox.mutate(mutant)
del mutant.fitness.values
population[:] = offspring
# 最適解の表示
fits = [ind.fitness.values[0] for ind in population]
best_ind = population[fits.index(max(fits))]
print("最適解:", best_ind, "適応度:", best_ind.fitness.values[0])最適解: [19.168189982454837, 24.047518422956685, 6.782155921219458, 9.254144507972555, 15.40757599340473] 適応度: 74.65958482800826ナップサック問題の例
ナップサック問題は、限られた容量の中で価値を最大化するアイテムの選択を行う問題です。
以下は、DEAPを使用したナップサック問題の実装例です。
import random
from deap import base, creator, tools
# アイテムの定義
items = [(60, 10), (100, 20), (120, 30)] # (価値, 重量)
capacity = 50 # ナップサックの容量
# 適応度を最大化する個体を定義
creator.create("FitnessMax", base.Fitness, weights=(1.0,))
creator.create("Individual", list, fitness=creator.FitnessMax)
# 評価関数の定義
def evaluate(individual):
total_value = sum(items[i][0] for i in range(len(individual)) if individual[i] == 1)
total_weight = sum(items[i][1] for i in range(len(individual)) if individual[i] == 1)
if total_weight > capacity:
return 0, # 容量を超えた場合は適応度0
return total_value,
# 集団の生成
toolbox = base.Toolbox()
toolbox.register("binary", random.randint, 0, 1)
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.binary, n=len(items))
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.register("evaluate", evaluate)
toolbox.register("mate", tools.cxTwoPoint)
toolbox.register("mutate", tools.mutFlipBit, indpb=0.1)
toolbox.register("select", tools.selTournament, tournsize=3)
# アルゴリズムの実行
population = toolbox.population(n=50)
for gen in range(10):
# すべての個体の適応度を再計算
for ind in population:
if not ind.fitness.valid:
ind.fitness.values = toolbox.evaluate(ind)
# 選択、交叉、突然変異
offspring = toolbox.select(population, len(population))
offspring = list(map(toolbox.clone, offspring))
for child1, child2 in zip(offspring[::2], offspring[1::2]):
if random.random() < 0.5:
toolbox.mate(child1, child2)
del child1.fitness.values
del child2.fitness.values
for mutant in offspring:
if random.random() < 0.2:
toolbox.mutate(mutant)
del mutant.fitness.values
# 交叉や突然変異の後に適応度を再計算
for ind in offspring:
if not ind.fitness.valid:
ind.fitness.values = toolbox.evaluate(ind)
population[:] = offspring
# 最適解の表示
fits = [ind.fitness.values[0] for ind in population]
best_ind = population[fits.index(max(fits))]
print("最適解:", best_ind, "適応度:", best_ind.fitness.values[0])最適解: [0, 1, 1] 適応度: 220.0巡回セールスマン問題の例
巡回セールスマン問題は、複数の都市を訪問し、最短の経路を求める問題です。
以下は、DEAPを使用した巡回セールスマン問題の実装例です。
import random
from deap import base, creator, tools
# 都市の座標
cities = [(0, 0), (1, 2), (2, 4), (3, 1), (4, 3)]
# 適応度を最小化する個体を定義
creator.create("FitnessMin", base.Fitness, weights=(-1.0,))
creator.create("Individual", list, fitness=creator.FitnessMin)
# 距離計算関数
def distance(city1, city2):
return ((city1[0] - city2[0]) ** 2 + (city1[1] - city2[1]) ** 2) ** 0.5
# 評価関数の定義
def evaluate(individual):
total_distance = sum(distance(cities[individual[i]], cities[individual[i + 1]]) for i in range(len(individual) - 1))
total_distance += distance(cities[individual[-1]], cities[individual[0]]) # 最後の都市から最初の都市へ
return total_distance,
# 集団の生成
toolbox = base.Toolbox()
toolbox.register("indices", random.sample, range(len(cities)), len(cities))
toolbox.register("individual", tools.initIterate, creator.Individual, toolbox.indices)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.register("evaluate", evaluate)
toolbox.register("mate", tools.cxOrdered)
toolbox.register("mutate", tools.mutShuffleIndexes, indpb=0.2) # indpbを追加
toolbox.register("select", tools.selTournament, tournsize=3)
# アルゴリズムの実行
population = toolbox.population(n=50)
for gen in range(10):
# 適応度が計算されていない個体に対して適応度を計算
invalid_ind = [ind for ind in population if not ind.fitness.valid]
for ind in invalid_ind:
ind.fitness.values = toolbox.evaluate(ind)
offspring = toolbox.select(population, len(population))
offspring = list(map(toolbox.clone, offspring))
for child1, child2 in zip(offspring[::2], offspring[1::2]):
if random.random() < 0.5:
toolbox.mate(child1, child2)
del child1.fitness.values
del child2.fitness.values
for mutant in offspring:
if random.random() < 0.2:
toolbox.mutate(mutant)
del mutant.fitness.values
# 適応度が計算されていない個体に対して適応度を再計算
invalid_ind = [ind for ind in offspring if not ind.fitness.valid]
for ind in invalid_ind:
ind.fitness.values = toolbox.evaluate(ind)
population[:] = offspring
# 最適解の表示
fits = [ind.fitness.values[0] for ind in population]
best_ind = population[fits.index(min(fits))]
print("最適解:", best_ind, "距離:", best_ind.fitness.values[0])最適解: [2, 4, 3, 0, 1] 距離: 12.10654957016754パラメータチューニングの例
遺伝的アルゴリズムのパラメータチューニングは、最適化の結果に大きな影響を与えます。
以下は、DEAPを使用してパラメータを調整する例です。
import random
from deap import base, creator, tools
# 適応度を最大化する個体を定義
creator.create("FitnessMax", base.Fitness, weights=(1.0,))
creator.create("Individual", list, fitness=creator.FitnessMax)
# 評価関数の定義
def evaluate(individual):
return sum(individual), # 合計を最大化
# 集団の生成
toolbox = base.Toolbox()
toolbox.register("random_value", random.uniform, 0, 10)
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.random_value, n=5)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.register("evaluate", evaluate)
toolbox.register("mate", tools.cxTwoPoint)
toolbox.register("mutate", tools.mutGaussian, mu=0, sigma=1, indpb=0.2)
toolbox.register("select", tools.selTournament, tournsize=3)
# パラメータの設定
population_size = 100
num_generations = 20
mutation_probability = 0.2
# アルゴリズムの実行
population = toolbox.population(n=population_size)
for gen in range(num_generations):
for ind in population:
ind.fitness.values = toolbox.evaluate(ind)
offspring = toolbox.select(population, len(population))
offspring = list(map(toolbox.clone, offspring))
for child1, child2 in zip(offspring[::2], offspring[1::2]):
if random.random() < 0.5:
toolbox.mate(child1, child2)
del child1.fitness.values
del child2.fitness.values
for mutant in offspring:
if random.random() < mutation_probability:
toolbox.mutate(mutant)
del mutant.fitness.values
population[:] = offspring
# 最適解の表示
fits = [ind.fitness.values[0] for ind in population]
best_ind = population[fits.index(max(fits))]
print("最適解:", best_ind, "適応度:", best_ind.fitness.values[0])最適解: [2, 4, 3, 0, 1] 距離: 12.10654957016754これらの例を通じて、DEAPを使用した遺伝的アルゴリズムの実装方法を理解し、さまざまな最適化問題に対するアプローチを学ぶことができます。
DEAPの進化アルゴリズム
DEAPでは、さまざまな進化アルゴリズムが実装されており、特定の問題に応じて選択することができます。
ここでは、代表的な進化アルゴリズムであるeaSimple、eaMuPlusLambda、eaMuCommaLambdaについて説明し、さらにカスタムアルゴリズムの作成方法を紹介します。
eaSimpleアルゴリズム
eaSimpleは、最も基本的な進化アルゴリズムで、選択、交叉、突然変異を行い、次世代の集団を生成します。
以下は、eaSimpleを使用したサンプルコードです。
from deap import base, creator, tools, algorithms
import random
# 適応度を最大化する個体を定義
creator.create("FitnessMax", base.Fitness, weights=(1.0,))
creator.create("Individual", list, fitness=creator.FitnessMax)
# 評価関数の定義
def evaluate(individual):
return sum(individual), # 合計を最大化
# 集団の生成
toolbox = base.Toolbox()
toolbox.register("random_value", random.uniform, 0, 10)
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.random_value, n=5)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.register("evaluate", evaluate)
toolbox.register("mate", tools.cxTwoPoint)
toolbox.register("mutate", tools.mutGaussian, mu=0, sigma=1, indpb=0.2)
toolbox.register("select", tools.selTournament, tournsize=3)
# アルゴリズムの実行
population = toolbox.population(n=50)
algorithms.eaSimple(population, toolbox, cxpb=0.5, mutpb=0.2, ngen=10, verbose=True)このコードでは、eaSimpleを使用して、選択、交叉、突然変異を行い、10世代の進化を実行します。
eaMuPlusLambdaアルゴリズム
eaMuPlusLambdaは、親集団のサイズμと子集団のサイズλを指定し、親と子を合わせて次世代を選択するアルゴリズムです。
この方法は、より多様性のある解を探索するのに役立ちます。
以下は、eaMuPlusLambdaを使用したサンプルコードです。
# アルゴリズムの実行
population = toolbox.population(n=50)
algorithms.eaMuPlusLambda(population, toolbox, mu=50, lambda_=100, cxpb=0.5, mutpb=0.2, ngen=10, verbose=True)このコードでは、50個の親個体と100個の子個体を生成し、進化を行います。
親と子を合わせて次世代を選択するため、より良い解を見つける可能性が高まります。
eaMuCommaLambdaアルゴリズム
eaMuCommaLambdaは、親集団のサイズμと子集団のサイズλを指定し、子集団のみを使用して次世代を生成するアルゴリズムです。
この方法は、より強い選択圧をかけることができ、優れた解を迅速に見つけることができます。
以下は、eaMuCommaLambdaを使用したサンプルコードです。
# アルゴリズムの実行
population = toolbox.population(n=50)
algorithms.eaMuCommaLambda(population, toolbox, mu=50, lambda_=100, cxpb=0.5, mutpb=0.2, ngen=10, verbose=True)このコードでは、親集団から選択された個体を使用して、次世代を生成します。
子集団のみが次世代に残るため、選択圧が強くなります。
カスタムアルゴリズムの作成
DEAPでは、独自の進化アルゴリズムを作成することも可能です。
以下は、カスタムアルゴリズムの基本的な構造を示すサンプルコードです。
def custom_algorithm(population, toolbox, ngen):
for gen in range(ngen):
# 評価
for ind in population:
ind.fitness.values = toolbox.evaluate(ind)
# 選択
offspring = toolbox.select(population, len(population))
offspring = list(map(toolbox.clone, offspring))
# 交叉と突然変異
for child1, child2 in zip(offspring[::2], offspring[1::2]):
if random.random() < 0.5:
toolbox.mate(child1, child2)
del child1.fitness.values
del child2.fitness.values
for mutant in offspring:
if random.random() < 0.2:
toolbox.mutate(mutant)
del mutant.fitness.values
# 新しい集団に更新
population[:] = offspring
# カスタムアルゴリズムの実行
population = toolbox.population(n=50)
custom_algorithm(population, toolbox, ngen=10)このカスタムアルゴリズムでは、評価、選択、交叉、突然変異の各ステップを手動で実行しています。
これにより、特定の問題に応じた進化アルゴリズムを柔軟に設計することができます。
これらの進化アルゴリズムを理解し、適切に選択することで、さまざまな最適化問題に対して効果的にアプローチすることが可能です。
DEAPの高度な機能
DEAPは、基本的な遺伝的アルゴリズムの実装だけでなく、さまざまな高度な機能も提供しています。
ここでは、マルチオブジェクティブ最適化、ログと統計の取得、並列処理の実装、チェックポイント機能の利用について説明します。
マルチオブジェクティブ最適化
マルチオブジェクティブ最適化は、複数の目的関数を同時に最適化する手法です。
DEAPでは、eaMuPlusLambdaやeaSimpleを使用して、マルチオブジェクティブ最適化を実行できます。
以下は、マルチオブジェクティブ最適化のサンプルコードです。
from deap import base, creator, tools, algorithms
import random
# 適応度を最大化する個体を定義
creator.create("FitnessMax", base.Fitness, weights=(1.0, 1.0))
creator.create("Individual", list, fitness=creator.FitnessMax)
# 評価関数の定義
def evaluate(individual):
return sum(individual), sum(x**2 for x in individual) # 2つの目的関数
# 集団の生成
toolbox = base.Toolbox()
toolbox.register("random_value", random.uniform, 0, 10)
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.random_value, n=5)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.register("evaluate", evaluate)
toolbox.register("mate", tools.cxBlend, alpha=0.5)
toolbox.register("mutate", tools.mutGaussian, mu=0, sigma=1, indpb=0.2)
toolbox.register("select", tools.selNSGA2)
# アルゴリズムの実行
population = toolbox.population(n=50)
algorithms.eaMuPlusLambda(population, toolbox, mu=50, lambda_=100, cxpb=0.5, mutpb=0.2, ngen=10, verbose=True)このコードでは、2つの目的関数を持つ個体を評価し、NSGA-IIアルゴリズムを使用して最適化を行います。
ログと統計の取得
DEAPでは、進化の過程を追跡するためのログと統計を取得することができます。
これにより、進化の進行状況を可視化し、結果を分析することが可能です。
以下は、ログと統計を取得するサンプルコードです。
from deap import base, creator, tools, algorithms
import random
import numpy as np
import matplotlib.pyplot as plt
# 適応度を最大化する個体を定義
creator.create("FitnessMax", base.Fitness, weights=(1.0, 1.0))
creator.create("Individual", list, fitness=creator.FitnessMax)
# 評価関数の定義
def evaluate(individual):
return sum(individual), sum(x**2 for x in individual) # 2つの目的関数
# 集団の生成
toolbox = base.Toolbox()
toolbox.register("random_value", random.uniform, 0, 10)
toolbox.register("individual", tools.initRepeat, creator.Individual, toolbox.random_value, n=5)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.register("evaluate", evaluate)
toolbox.register("mate", tools.cxBlend, alpha=0.5)
toolbox.register("mutate", tools.mutGaussian, mu=0, sigma=1, indpb=0.2)
toolbox.register("select", tools.selNSGA2)
# ログと統計の設定
stats = tools.Statistics(lambda ind: ind.fitness.values)
stats.register("avg", np.mean)
stats.register("min", np.min)
stats.register("max", np.max)
# アルゴリズムの実行
population = toolbox.population(n=50)
population, logbook = algorithms.eaSimple(population, toolbox, cxpb=0.5, mutpb=0.2, ngen=10, stats=stats, verbose=True)
# 結果の表示
gen = logbook.select("gen")
fit_mins = logbook.select("min")
fit_avgs = logbook.select("avg")
fit_maxs = logbook.select("max")
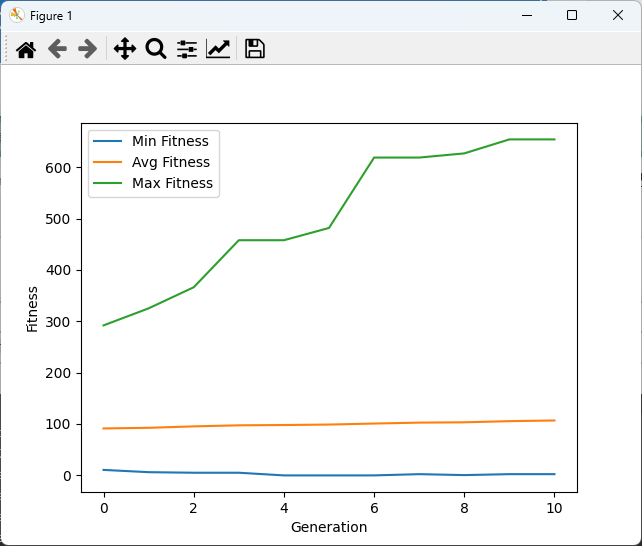
plt.plot(gen, fit_mins, label="Min Fitness")
plt.plot(gen, fit_avgs, label="Avg Fitness")
plt.plot(gen, fit_maxs, label="Max Fitness")
plt.xlabel("Generation")
plt.ylabel("Fitness")
plt.legend()
plt.show()このコードでは、各世代の適応度の最小値、平均値、最大値を記録し、グラフとして可視化しています。
並列処理の実装
DEAPでは、評価関数を並列処理で実行することができます。
これにより、大規模な集団や複雑な評価関数の計算を効率化できます。
以下は、並列処理を実装するサンプルコードです。
from deap import tools
from multiprocessing import Pool
# 評価関数の並列処理
def evaluate_parallel(individuals):
return list(map(evaluate, individuals))
# アルゴリズムの実行
if __name__ == "__main__":
pool = Pool()
toolbox.register("map", pool.map)
population = toolbox.population(n=50)
algorithms.eaSimple(population, toolbox, cxpb=0.5, mutpb=0.2, ngen=10, verbose=True)
pool.close()
pool.join()このコードでは、Poolを使用して評価関数を並列に実行しています。
これにより、計算時間を短縮することができます。
チェックポイント機能の利用
DEAPでは、進化の途中でチェックポイントを保存し、後で再開することができます。
これにより、長時間の計算を中断しても、進行状況を保持できます。
以下は、チェックポイント機能の利用例です。
import pickle
# チェックポイントの保存
def save_checkpoint(population, generation):
with open("checkpoint.pkl", "wb") as f:
pickle.dump((population, generation), f)
# チェックポイントの読み込み
def load_checkpoint():
with open("checkpoint.pkl", "rb") as f:
return pickle.load(f)
# アルゴリズムの実行
if __name__ == "__main__":
try:
population, generation = load_checkpoint()
except FileNotFoundError:
population = toolbox.population(n=50)
generation = 0
while generation < 10:
# 評価
for ind in population:
ind.fitness.values = toolbox.evaluate(ind)
# 次世代の生成
offspring = toolbox.select(population, len(population))
offspring = list(map(toolbox.clone, offspring))
for child1, child2 in zip(offspring[::2], offspring[1::2]):
if random.random() < 0.5:
toolbox.mate(child1, child2)
del child1.fitness.values
del child2.fitness.values
for mutant in offspring:
if random.random() < 0.2:
toolbox.mutate(mutant)
del mutant.fitness.values
population[:] = offspring
generation += 1
# チェックポイントの保存
save_checkpoint(population, generation)このコードでは、進化の途中でチェックポイントを保存し、再開する機能を実装しています。
これにより、長時間の計算を効率的に管理できます。
これらの高度な機能を活用することで、DEAPを使用した進化的アルゴリズムの実装がさらに強力になります。
さまざまな最適化問題に対して、柔軟かつ効率的にアプローチすることが可能です。
DEAPの応用例
DEAPは、さまざまな分野での最適化問題に応用可能です。
ここでは、機械学習モデルの最適化、ニューラルネットワークの進化的設計、ゲームAIの進化、自動車の経路最適化、ポートフォリオ最適化の5つの応用例を紹介します。
機械学習モデルの最適化
DEAPを使用して、機械学習モデルのハイパーパラメータを最適化することができます。
例えば、サポートベクターマシン(SVM)のカーネルや正則化パラメータを最適化するために、遺伝的アルゴリズムを利用することができます。
以下は、SVMのハイパーパラメータを最適化するための基本的な流れです。
- 個体をハイパーパラメータの組み合わせとして定義。
- 評価関数でモデルの精度を計算。
- 遺伝的アルゴリズムを用いて最適なハイパーパラメータを探索。
ニューラルネットワークの進化的設計
DEAPを使用して、ニューラルネットワークのアーキテクチャを進化的に設計することができます。
個体は、ニューラルネットワークの層の数や各層のノード数を表現し、適応度関数でモデルの性能を評価します。
進化的アルゴリズムを用いて、最適なアーキテクチャを見つけることが可能です。
- 個体をニューラルネットワークの構造として定義。
- 評価関数でモデルの精度を計算。
- 遺伝的アルゴリズムを用いて最適なアーキテクチャを探索。
ゲームAIの進化
DEAPは、ゲームAIの進化にも利用されます。
例えば、ボードゲームや戦略ゲームにおいて、AIの行動戦略を進化的に最適化することができます。
個体は、特定の戦略や行動パターンを表現し、対戦結果を評価して適応度を計算します。
これにより、より強力なAIを生成することが可能です。
- 個体をゲームの行動戦略として定義。
- 評価関数で対戦結果を計算。
- 遺伝的アルゴリズムを用いて最適な戦略を探索。
自動車の経路最適化
自動車の経路最適化問題においても、DEAPを利用することができます。
個体は、特定の経路を表現し、適応度関数で移動距離や時間を評価します。
遺伝的アルゴリズムを用いて、最短経路や最適な経路を見つけることが可能です。
- 個体を経路として定義。
- 評価関数で移動距離や時間を計算。
- 遺伝的アルゴリズムを用いて最適な経路を探索。
ポートフォリオ最適化
ポートフォリオ最適化問題においても、DEAPを活用することができます。
個体は、異なる資産の配分を表現し、適応度関数でリスクとリターンを評価します。
遺伝的アルゴリズムを用いて、最適な資産配分を見つけることが可能です。
- 個体を資産の配分として定義。
- 評価関数でリスクとリターンを計算。
- 遺伝的アルゴリズムを用いて最適な資産配分を探索。
これらの応用例を通じて、DEAPがさまざまな最適化問題に対して柔軟に対応できることがわかります。
進化的アルゴリズムを活用することで、複雑な問題に対して効果的な解決策を見つけることが可能です。
まとめ
この記事では、DEAPライブラリを使用した遺伝的アルゴリズムの基本的な使い方から、高度な機能や応用例まで幅広く取り上げました。
特に、マルチオブジェクティブ最適化や並列処理の実装など、実践的な技術を学ぶことで、さまざまな最適化問題に対するアプローチが可能になります。
これを機に、DEAPを活用して自身のプロジェクトや研究に取り組んでみてはいかがでしょうか。
![[Python] bisectライブラリの使い方 – ニ分探索の効率化](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46600.png)
![[Python] a*(A Star)探索アルゴリズムを実装する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43234.png)
![[Python] ベジェ曲線を実装する方法(二次ベジェ/三次ベジェ)](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43239.png)
![[Python] ベッセル関数を使ったグラフ作成方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43238.png)
![[Python] ベルヌーイ分布を実装する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43237.png)
![[Python] エイトケンのΔ2乗加速法を実装する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43236.png)
![[Python] アッカーマン関数のプログラムを作成する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43235.png)
![[Python] matplotlibでC曲線を描画する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43245.png)
![[Python] CRC(巡回冗長検査)のアルゴリズムを実装する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43244.png)
![[Python] コラッツ予想(コラッツの問題)のプログラムを作成する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43243.png)
![[Python] コーシー分布の計算を行う方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43242.png)
![[Python] ボイヤームーア法で文字列検索する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43240.png)