[Python] json.dumpsエラーの解決方法
Pythonでjson.dumpsを使用する際にエラーが発生することがあります。主な原因は、シリアライズできないオブジェクトを含んでいる場合です。例えば、datetimeオブジェクトやカスタムクラスのインスタンスはデフォルトではJSONに変換できません。
この問題を解決するには、defaultパラメータを使用してカスタムシリアライザを指定するか、シリアライズ可能な形式に変換する必要があります。また、ensure_ascii=Falseを指定することで、非ASCII文字をそのまま出力することも可能です。
json.dumpsエラーの種類
PythonでJSONデータを生成する際に使用されるjson.dumps関数は、さまざまなエラーを引き起こすことがあります。
ここでは、代表的なエラーの種類について説明します。
TypeError: Object of type ‘X’ is not JSON serializable
このエラーは、json.dumpsがシリアライズできないオブジェクトを含むデータを処理しようとしたときに発生します。
Pythonの標準的なデータ型(リスト、辞書、文字列、数値など)はシリアライズ可能ですが、カスタムオブジェクトや特定のデータ型(例えば、datetimeオブジェクトやDecimalオブジェクト)はそのままではシリアライズできません。
import json
from datetime import datetime
# datetimeオブジェクトを含むデータ
data = {
"name": "Taro",
"date": datetime.now()
}
# シリアライズを試みる
json_str = json.dumps(data)TypeError: Object of type 'datetime' is not JSON serializableこのエラーは、datetimeオブジェクトがそのままではJSONに変換できないために発生します。
UnicodeEncodeError: ‘utf-8’ codec can’t encode character
このエラーは、json.dumpsがエンコードできない文字を含むデータを処理しようとしたときに発生します。
特に、非ASCII文字を含む文字列を処理する際に問題が生じることがあります。
import json
# 非ASCII文字を含むデータ
data = {
"message": "こんにちは"
}
# シリアライズを試みる
json_str = json.dumps(data, ensure_ascii=False){"message": "こんにちは"}この例では、ensure_ascii=Falseを指定することで、非ASCII文字をそのまま出力することができます。
OverflowError: Out of range float values are not JSON compliant
このエラーは、json.dumpsがJSONの仕様に準拠しない浮動小数点数を含むデータを処理しようとしたときに発生します。
特に、無限大やNaN(非数)を含む場合に問題が生じます。
import json
import math
# 無限大を含むデータ
data = {
"value": math.inf
}
# シリアライズを試みる
json_str = json.dumps(data)OverflowError: Out of range float values are not JSON compliantこのエラーは、math.infがJSONの仕様に準拠していないために発生します。
JSONでは無限大やNaNを表現することができません。
TypeErrorの解決方法
json.dumpsで発生するTypeErrorを解決するためには、シリアライズできないオブジェクトを適切に処理する必要があります。
ここでは、カスタムエンコーダの使用とデータ型の変換による解決方法を紹介します。
カスタムエンコーダの使用
カスタムエンコーダを使用することで、特定のオブジェクトをJSONにシリアライズする方法を定義できます。
JSONEncoderクラスの拡張
Pythonのjsonモジュールには、JSONEncoderクラスが用意されています。
このクラスを拡張することで、カスタムオブジェクトのシリアライズ方法を定義できます。
import json
from datetime import datetime
# JSONEncoderを拡張してカスタムエンコーダを作成
class CustomEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, datetime):
return obj.isoformat() # datetimeオブジェクトをISOフォーマットの文字列に変換
return super().default(obj)
# datetimeオブジェクトを含むデータ
data = {
"name": "Taro",
"date": datetime.now()
}
# カスタムエンコーダを使用してシリアライズ
json_str = json.dumps(data, cls=CustomEncoder)
print(json_str){"name": "Taro", "date": "2023-10-05T14:48:00.000000"}この例では、datetimeオブジェクトをISOフォーマットの文字列に変換するカスタムエンコーダを使用しています。
defaultメソッドの実装
JSONEncoderクラスのdefaultメソッドをオーバーライドすることで、特定のオブジェクトのシリアライズ方法を定義できます。
import json
from decimal import Decimal
# JSONEncoderを拡張してdefaultメソッドを実装
class CustomEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, Decimal):
return float(obj) # Decimalオブジェクトをfloatに変換
return super().default(obj)
# Decimalオブジェクトを含むデータ
data = {
"price": Decimal('19.99')
}
# カスタムエンコーダを使用してシリアライズ
json_str = json.dumps(data, cls=CustomEncoder)
print(json_str){"price": 19.99}この例では、Decimalオブジェクトをfloatに変換するカスタムエンコーダを使用しています。
データ型の変換
シリアライズできないデータ型を事前に変換することで、TypeErrorを回避することができます。
datetimeオブジェクトの変換
datetimeオブジェクトを文字列に変換することで、シリアライズ可能にします。
import json
from datetime import datetime
# datetimeオブジェクトを含むデータ
data = {
"name": "Taro",
"date": datetime.now().isoformat() # 文字列に変換
}
# シリアライズ
json_str = json.dumps(data)
print(json_str){"name": "Taro", "date": "2023-10-05T14:48:00.000000"}Decimalオブジェクトの変換
Decimalオブジェクトをfloatに変換することで、シリアライズ可能にします。
import json
from decimal import Decimal
# Decimalオブジェクトを含むデータ
data = {
"price": float(Decimal('19.99')) # floatに変換
}
# シリアライズ
json_str = json.dumps(data)
print(json_str){"price": 19.99}このように、事前にデータ型を変換することで、json.dumpsでのTypeErrorを回避することができます。
UnicodeEncodeErrorの解決方法
json.dumpsを使用する際に発生するUnicodeEncodeErrorは、非ASCII文字を含むデータを処理する際に問題となることがあります。
ここでは、このエラーを解決するための方法を紹介します。
ensure_asciiオプションの使用
json.dumps関数には、ensure_asciiというオプションがあります。
このオプションをFalseに設定することで、非ASCII文字をそのまま出力することができます。
デフォルトではTrueに設定されており、すべての非ASCII文字がエスケープされます。
import json
# 非ASCII文字を含むデータ
data = {
"message": "こんにちは"
}
# ensure_asciiオプションを使用してシリアライズ
json_str = json.dumps(data, ensure_ascii=False)
print(json_str){"message": "こんにちは"}この例では、ensure_ascii=Falseを指定することで、非ASCII文字がエスケープされずにそのまま出力されています。
これにより、UnicodeEncodeErrorを回避することができます。
エンコーディングの確認と設定
Pythonのデフォルトエンコーディングがutf-8でない場合、UnicodeEncodeErrorが発生することがあります。
特に、システムのロケール設定やPythonのバージョンによって異なる場合があります。
エンコーディングを明示的に設定することで、エラーを回避できます。
import json
import sys
# 現在のデフォルトエンコーディングを確認
print("Default encoding:", sys.getdefaultencoding())
# 非ASCII文字を含むデータ
data = {
"message": "こんにちは"
}
# ensure_asciiオプションを使用してシリアライズ
json_str = json.dumps(data, ensure_ascii=False)
print(json_str)Default encoding: utf-8
{"message": "こんにちは"}この例では、デフォルトのエンコーディングがutf-8であることを確認しています。
json.dumpsのensure_asciiオプションを使用することで、エンコーディングに関する問題を回避できます。
エンコーディングの設定は、Pythonの環境設定やシステムのロケール設定に依存するため、必要に応じて環境を確認し、適切なエンコーディングを設定することが重要です。
OverflowErrorの解決方法
json.dumpsを使用する際に発生するOverflowErrorは、JSONの仕様に準拠しない浮動小数点数(無限大やNaN)を含むデータを処理する際に問題となります。
ここでは、このエラーを解決するための方法を紹介します。
無限大やNaNの処理
Pythonのjson.dumps関数には、allow_nanというオプションがあります。
このオプションをTrueに設定することで、無限大やNaNをnullとしてシリアライズすることができます。
デフォルトではTrueに設定されていますが、JSONの仕様に厳密に準拠する場合はFalseに設定する必要があります。
import json
import math
# 無限大やNaNを含むデータ
data = {
"positive_infinity": math.inf,
"negative_infinity": -math.inf,
"not_a_number": math.nan
}
# allow_nanオプションを使用してシリアライズ
json_str = json.dumps(data, allow_nan=True)
print(json_str){"positive_infinity": null, "negative_infinity": null, "not_a_number": null}この例では、allow_nan=Trueを指定することで、無限大やNaNがnullとしてシリアライズされています。
これにより、OverflowErrorを回避することができます。
float型の範囲内に収める方法
無限大やNaNを含むデータを事前に処理し、float型の範囲内に収めることで、OverflowErrorを回避することができます。
例えば、無限大を最大または最小のfloat値に置き換える方法があります。
import json
import math
import sys
# 無限大やNaNを含むデータ
data = {
"positive_infinity": math.inf,
"negative_infinity": -math.inf,
"not_a_number": math.nan
}
# 無限大やNaNをfloatの範囲内に収める関数
def sanitize_floats(data):
for key, value in data.items():
if isinstance(value, float):
if math.isinf(value):
data[key] = sys.float_info.max if value > 0 else -sys.float_info.max
elif math.isnan(value):
data[key] = 0.0 # NaNを0に置き換え
return data
# データを処理してからシリアライズ
sanitized_data = sanitize_floats(data)
json_str = json.dumps(sanitized_data)
print(json_str){"positive_infinity": 1.7976931348623157e+308, "negative_infinity": -1.7976931348623157e+308, "not_a_number": 0.0}この例では、無限大を最大または最小のfloat値に置き換え、NaNを0に置き換えることで、OverflowErrorを回避しています。
データを事前に処理することで、JSONの仕様に準拠したシリアライズが可能になります。
json.dumpsの応用例
json.dumpsは、PythonでJSONデータを生成するための強力なツールです。
ここでは、json.dumpsの実用的な応用例をいくつか紹介します。
データベースから取得したデータのシリアライズ
データベースから取得したデータをJSON形式にシリアライズすることで、データの転送や保存が容易になります。
特に、Webアプリケーションでクライアントにデータを送信する際に便利です。
import json
import sqlite3
# SQLiteデータベースに接続
conn = sqlite3.connect('example.db')
cursor = conn.cursor()
# テーブルからデータを取得
cursor.execute("SELECT id, name, age FROM users")
rows = cursor.fetchall()
# データを辞書形式に変換
data = [{"id": row[0], "name": row[1], "age": row[2]} for row in rows]
# JSONにシリアライズ
json_str = json.dumps(data, ensure_ascii=False)
print(json_str)
# データベース接続を閉じる
conn.close()この例では、SQLiteデータベースから取得したデータを辞書形式に変換し、json.dumpsを使用してJSON形式にシリアライズしています。
Web APIのレスポンス生成
Web APIの開発において、サーバーからクライアントにデータを返す際にJSON形式を使用することが一般的です。
json.dumpsを使用することで、Pythonのデータを簡単にJSON形式に変換できます。
import json
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/api/data')
def get_data():
# サンプルデータ
data = {
"status": "success",
"data": {
"id": 1,
"name": "Taro",
"age": 30
}
}
# JSONレスポンスを生成
return jsonify(data)
if __name__ == '__main__':
app.run()この例では、Flaskを使用してWeb APIを構築し、jsonifyを使用してJSONレスポンスを生成しています。
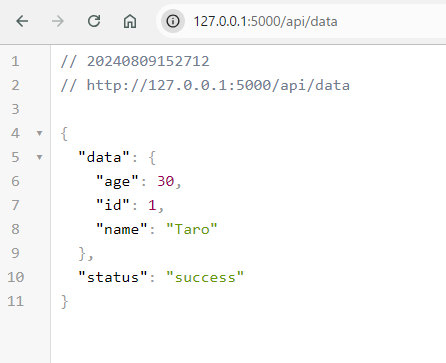
jsonifyは内部でjson.dumpsを使用しています。
設定ファイルの生成と管理
アプリケーションの設定をJSON形式で保存することで、設定の読み込みや管理が容易になります。
json.dumpsを使用して設定データをJSONファイルに書き込むことができます。
import json
# 設定データ
config = {
"app_name": "MyApp",
"version": "1.0",
"settings": {
"theme": "dark",
"language": "ja"
}
}
# JSONファイルに書き込む
with open('config.json', 'w', encoding='utf-8') as f:
json.dump(config, f, ensure_ascii=False, indent=4)
print("設定ファイルが生成されました。")この例では、アプリケーションの設定データをJSON形式でファイルに保存しています。
ensure_ascii=Falseを指定することで、日本語などの非ASCII文字をそのまま保存しています。
これにより、設定ファイルの管理が容易になります。
まとめ
この記事では、Pythonのjson.dumpsに関連するエラーの解決方法と応用例について詳しく解説しました。
json.dumpsを使用する際に発生するエラーの種類や、それらを解決するための具体的な方法を学ぶことで、JSONデータのシリアライズがよりスムーズに行えるようになります。
この記事を参考に、実際のプロジェクトでjson.dumpsを活用し、データのシリアライズを効率的に行ってみてください。
![[Python] ワイルドカード(*)の使い方 – パス指定/正規表現](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46843.png)
![[Python] with文で複数ファイルを同時に開く方法](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46842.png)
![[Python] with文の使い方 – 安全なファイル読み込み&クローズの実装](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46841.png)
![[Python] with openでファイルがない場合の例外処理を実装する](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46840.png)
![[Python] with openのファイル読み込みでエラー処理を定義する方法](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46839.png)
![[Python] watchdogライブラリの使い方 – フォルダの変更を監視する](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46838.png)
![[Python] tempfile関数の使い方 – 一時ファイル・ディレクトリの作成](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46837.png)
![[Python] sys.path.append関数の使い方 – モジュール検索パスにディレクトリを追加する](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46836.png)
![[Python] seek関数の使い方 – ファイルのカーソル位置の変更](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46835.png)
![[Python] pathlibモジュールの使い方 – 効率よくパスを操作する](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46834.png)
![[Python] os.walkの使い方 – ディレクトリを再帰的に探索する](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46833.png)
![[Python] os.path.joinメソッドの使い方 – ファイルパスの結合](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46832.png)