【C++】OpenCVを使ったコンピュータビジョン開発の基本と応用
C++とOpenCVを使うと、多彩な画像処理や特徴抽出、物体検出、動画像解析などを効率よく実装できます。
Matで画像を扱い、imshowやVideoCaptureで可視化を行い、CUDAやT-APIで高速処理も実現できます。
OpenCV基礎クラスとデータ構造
OpenCVを使った画像処理やコンピュータビジョンのプログラムを作成する際には、さまざまなクラスやデータ構造を理解しておくことが重要です。
これらの基本的な要素を押さえることで、効率的に画像データを操作し、複雑な処理もスムーズに行えるようになります。
Matと画像データの管理
OpenCVの中核をなすクラスがMatです。
Matは画像や行列データを格納するためのクラスであり、画像処理のほぼすべての操作の基盤となります。
Matの特徴は、画像のピクセルデータを効率的に管理できる点にあります。
画像のサイズやチャンネル数、データ型などを柔軟に設定でき、画像の部分切り出しや変換、演算なども容易に行えます。
// 画像を読み込み、Matオブジェクトに格納する例
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 画像ファイルのパス
std::string imagePath = "sample.jpg";
// 画像を読み込む(カラー画像として読み込み)
cv::Mat image = cv::imread(imagePath, cv::IMREAD_COLOR);
// 画像が正しく読み込まれたか確認
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// 画像の情報を出力
std::cout << "画像のサイズ: " << image.cols << "x" << image.rows << std::endl;
std::cout << "チャンネル数: " << image.channels() << std::endl;
// 画像をウィンドウに表示
cv::imshow("読み込んだ画像", image);
cv::waitKey(0);
return 0;
}画像のサイズ: 1536x1024
チャンネル数: 3
※画像も表示されるこの例では、imread関数を使って画像ファイルをMatに読み込み、画像のサイズやチャンネル数を出力しています。
Matは画像のピクセルデータを二次元配列のように扱うことができ、ピクセル値のアクセスや変更も簡単です。
// ピクセル値のアクセス例
cv::Vec3b pixel = image.at<cv::Vec3b>(cv::Point(50, 50)); // (x=50, y=50)のピクセル
std::cout << "B: " << (int)pixel[0] << " G: " << (int)pixel[1] << " R: " << (int)pixel[2] << std::endl;Matはまた、画像の一部分だけを切り出すことも容易です。
// 画像の一部を切り出す例
cv::Rect roi(10, 10, 100, 100); // 左上の座標(10,10)、幅100、高さ100の領域
cv::Mat subImage = image(roi);
cv::imshow("切り出した画像", subImage);
cv::waitKey(0);Point・Size・Rectの活用法
OpenCVでは、画像処理のさまざまな操作において座標やサイズを表すためにPoint、Size、Rectといったクラスが頻繁に使われます。
これらは、画像内の位置や領域を直感的に扱うために便利です。
Point
Pointは2次元の座標を表すクラスです。
画像内のピクセル位置や、図形の中心点などを指定するのに使います。
// Pointの例
cv::Point pt1(50, 100); // x=50, y=100の点
cv::circle(image, pt1, 5, cv::Scalar(0, 255, 0), -1); // 点の位置に円を描くSize
Sizeは画像や図形の幅と高さを表します。
画像のリサイズや矩形の大きさを指定する際に使います。
// Sizeの例
cv::Size newSize(640, 480); // 幅640、高さ480のサイズ
cv::Mat resizedImage;
cv::resize(image, resizedImage, newSize);Rect
Rectは矩形領域を表すクラスです。
画像の一部分を切り出したり、ROI(Region of Interest)を設定したりするのに便利です。
// Rectの例
cv::Rect roi(10, 10, 100, 100); // 左上座標(10,10)、幅100、高さ100の矩形
cv::Mat roiImage = image(roi);
cv::imshow("ROI画像", roiImage);
cv::waitKey(0);これらのクラスは、座標やサイズを扱う際に非常に直感的であり、コードの可読性や保守性を高めてくれます。
これらの基本的なクラスとデータ構造を理解しておくことで、OpenCVを使った画像処理の土台がしっかりと築かれます。
次のステップでは、実際の画像操作や処理の具体例に進んでいきます。
画像入出力
画像処理のプログラムを作成する上で、画像や動画の入出力は基本中の基本です。
OpenCVでは、画像や動画の読み込み・書き出しに関する関数が豊富に用意されており、さまざまなフォーマットに対応しています。
ここでは、画像の読み込みと書き出し、そして動画ストリームの取得と保存について詳しく解説します。
画像の読み込みと書き出し
画像の読み込みにはcv::imread関数を使います。
ファイルパスと読み込みモードを指定することで、カラー画像やグレースケール画像を簡単に取得できます。
書き出しにはcv::imwriteを用います。
これにより、処理結果をファイルに保存可能です。
// 画像の読み込みと書き出しの例
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 画像ファイルのパス
std::string inputPath = "input.jpg";
std::string outputPath = "output.jpg";
// 画像をカラー画像として読み込み
cv::Mat image = cv::imread(inputPath, cv::IMREAD_COLOR);
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// 画像のサイズとチャンネル数を出力
std::cout << "読み込んだ画像のサイズ: " << image.cols << "x" << image.rows << std::endl;
// 画像をグレースケールに変換
cv::Mat grayImage;
cv::cvtColor(image, grayImage, cv::COLOR_BGR2GRAY);
// 変換した画像を保存
cv::imwrite(outputPath, grayImage);
// 保存成功のメッセージ
std::cout << "画像を保存しました: " << outputPath << std::endl;
// 画像を表示
cv::imshow("グレースケール画像", grayImage);
cv::waitKey(0);
return 0;
}この例では、imreadで画像を読み込み、cvtColorでグレースケールに変換し、imwriteで保存しています。
imwriteはJPEGやPNGなど多くのフォーマットに対応しており、ファイル名の拡張子によって自動的にフォーマットを判別します。
動画ストリームの取得と保存
動画の入出力にはcv::VideoCaptureとcv::VideoWriterを使用します。
VideoCaptureはカメラや動画ファイルからフレームを取得し、VideoWriterはフレームを動画ファイルに書き出します。
動画の読み込みとフレーム取得
// 動画の読み込みとフレーム取得例
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 動画ファイルのパス
std::string videoPath = "sample_video.mp4";
// VideoCaptureオブジェクトの作成
cv::VideoCapture cap(videoPath);
if (!cap.isOpened()) {
std::cerr << "動画のオープンに失敗しました。" << std::endl;
return -1;
}
cv::Mat frame;
while (true) {
// フレームを1枚ずつ取得
cap >> frame;
if (frame.empty()) {
break; // 動画の終端に達した場合
}
// 取得したフレームを表示
cv::imshow("動画フレーム", frame);
if (cv::waitKey(30) >= 0) break; // 30ms待機し、キー入力で終了
}
cap.release();
cv::destroyAllWindows();
return 0;
}動画の保存
動画を書き出すにはcv::VideoWriterを設定します。
コーデックやフレームレート、フレームサイズを指定し、フレームを逐次書き込みます。
// 動画の保存例
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 保存する動画ファイル名
std::string outputVideoPath = "output_video.avi";
// フレームサイズとコーデック設定
int frameWidth = 640;
int frameHeight = 480;
int fps = 30;
// コーデックの設定(例:MJPG)
int fourcc = cv::VideoWriter::fourcc('M', 'J', 'P', 'G');
// VideoWriterオブジェクトの作成
cv::VideoWriter writer(outputVideoPath, fourcc, fps, cv::Size(frameWidth, frameHeight));
if (!writer.isOpened()) {
std::cerr << "動画の書き込みに失敗しました。" << std::endl;
return -1;
}
// 例として、黒いフレームを一定数書き込み
for (int i = 0; i < 150; ++i) { // 5秒分(30fps×5秒)
cv::Mat frame = cv::Mat::zeros(cv::Size(frameWidth, frameHeight), CV_8UC3);
// 何らかの処理を行ったフレームを追加可能
writer.write(frame);
}
writer.release();
std::cout << "動画を書き出しました: " << outputVideoPath << std::endl;
return 0;
}この例では、黒い静止画のフレームを連続して書き込み、動画ファイルを作成しています。
実際には、カメラから取得したフレームや画像処理後のフレームをwriteに渡すことで、さまざまな動画を生成できます。
これらの入出力操作をマスターすることで、画像や動画を自在に扱えるようになり、より高度な画像処理やコンピュータビジョンのアプリケーションを開発できる土台が整います。
画像前処理
画像前処理は、画像解析や特徴抽出の精度を高めるために不可欠な工程です。
ノイズ除去や色空間の変換、二値化などを適切に行うことで、後続の処理の効率と精度を向上させることができます。
ここでは、代表的な前処理手法について詳しく解説します。
カラー空間変換
画像の色空間を変換することで、特定の特徴を強調したり、処理を容易にしたりできます。
OpenCVでは、cv::cvtColor関数を使ってさまざまな色空間への変換が可能です。
BGR⇔グレースケール
OpenCVの画像はデフォルトでBGR(青・緑・赤)形式です。
グレースケール画像に変換することで、色情報を排除し、輝度情報だけに集中できます。
// BGR画像をグレースケールに変換
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat colorImage = cv::imread("sample.jpg", cv::IMREAD_COLOR);
if (colorImage.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat grayImage;
cv::cvtColor(colorImage, grayImage, cv::COLOR_BGR2GRAY);
cv::imshow("グレースケール画像", grayImage);
cv::waitKey(0);
return 0;
}
この変換は、二値化やエッジ検出などの処理において非常に有効です。
HSVやLabへの変換
HSV(色相・彩度・明度)やLabは、色の情報を人間の視覚に近い形で表現できる色空間です。
これらに変換することで、色の閾値設定や色抽出が容易になります。
// BGRからHSVへの変換例
cv::Mat hsvImage;
cv::cvtColor(colorImage, hsvImage, cv::COLOR_BGR2HSV);HSV空間では、色相(Hue)を基準に色の抽出やフィルタリングを行うことが多く、特定の色範囲を簡単に選択できます。
ノイズ除去
画像にはさまざまなノイズが含まれることがあり、これが原因で誤検出や処理の失敗につながるため、適切なノイズ除去が必要です。
平滑化フィルタ(GaussianBlur/medianBlur)
- GaussianBlurは、ガウシアン分布に基づく平滑化フィルタで、画像の高周波成分を除去し、ノイズを低減します
// GaussianBlurの例
cv::Mat blurredImage;
cv::GaussianBlur(grayImage, blurredImage, cv::Size(5, 5), 1.5);
- medianBlurは、各ピクセルの周囲の中央値を取ることでノイズを除去します。特に塩胡椒ノイズに効果的です
// medianBlurの例
cv::Mat medianFiltered;
cv::medianBlur(grayImage, medianFiltered, 5);
モルフォロジー演算(膨張/収縮)
形態学的処理は、画像の構造を変化させる操作です。
膨張(dilation)は対象を拡大し、収縮(erosion)は縮小させます。
// 膨張と収縮の例
cv::Mat dilated, eroded;
cv::Mat element = cv::getStructuringElement(cv::MORPH_RECT, cv::Size(3, 3));
cv::dilate(medianFiltered, dilated, element);
cv::erode(dilated, eroded, element);これらの操作は、ノイズ除去や対象の連結・分離に役立ちます。
二値化と輪郭検出
画像の二値化は、対象と背景を明確に分離するために用います。
cv::threshold関数を使って閾値処理を行い、対象の抽出や輪郭検出の準備をします。
thresholdによる分割
// 二値化の例
cv::Mat binaryImage;
double thresh = 128; // 閾値
cv::threshold(blurredImage, binaryImage, thresh, 255, cv::THRESH_BINARY);
この例では、輝度値が閾値を超えるピクセルを白(255)、それ以外を黒(0)に変換しています。
findContoursと形状解析
二値化画像から輪郭を抽出し、対象の形状や位置を解析します。
// 輪郭検出の例
std::vector<std::vector<cv::Point>> contours;
cv::findContours(binaryImage, contours, cv::RETR_EXTERNAL, cv::CHAIN_APPROX_SIMPLE);
// 輪郭の描画
cv::Mat contourImage = cv::Mat::zeros(binaryImage.size(), CV_8UC3);
for (size_t i = 0; i < contours.size(); ++i) {
cv::Scalar color = cv::Scalar(0, 255, 0); // 緑色
cv::drawContours(contourImage, contours, static_cast<int>(i), color, 2);
}
cv::imshow("輪郭検出結果", contourImage);
cv::waitKey(0);
findContoursは、二値画像から連結成分の境界線を抽出し、drawContoursで視覚化します。
これにより、対象の形状や位置情報を取得でき、面積や周囲長の計測も可能です。
これらの前処理技術を適切に組み合わせることで、画像解析の精度と効率を大きく向上させることができます。
次の処理ステップに進む前に、これらの基本操作をしっかりと理解しておくことが重要です。
特徴量抽出
画像処理やコンピュータビジョンの応用において、特徴量抽出は重要な役割を果たします。
画像内の重要なポイントやパターンを抽出し、それらを比較・マッチングすることで、物体認識や追跡、3D再構築などの高度な処理が可能となります。
ここでは、代表的なコーナー検出と記述子生成の手法について詳しく解説します。
コーナー検出
コーナーは、画像内で局所的に変化が大きい点であり、特徴点として非常に有用です。
コーナー検出にはさまざまなアルゴリズムが存在しますが、ここでは代表的な2つを紹介します。
Harrisコーナー
Harrisコーナー検出は、最も古典的なコーナー検出手法の一つです。
画像の局所的な自己相関行列(コリニアリティ行列)を計算し、その固有値を用いてコーナーの強さを評価します。
// Harrisコーナー検出の例
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat src = cv::imread("sample.jpg", cv::IMREAD_GRAYSCALE);
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat dst, dst_norm, dst_norm_scaled;
dst = cv::Mat::zeros(src.size(), CV_32FC1);
// Harrisコーナー検出
int blockSize = 2;
int apertureSize = 3;
double k = 0.04; // 閾値
cv::cornerHarris(src, dst, blockSize, apertureSize, k);
// 正規化
cv::normalize(dst, dst_norm, 0, 255, cv::NORM_MINMAX);
cv::convertScaleAbs(dst_norm, dst_norm_scaled);
// コーナーの描画
cv::Mat result;
cv::cvtColor(src, result, cv::COLOR_GRAY2BGR);
for (int i = 0; i < dst_norm.rows; i++) {
for (int j = 0; j < dst_norm.cols; j++) {
if ((int)dst_norm.at<float>(i, j) > 200) { // 閾値
cv::circle(result, cv::Point(j, i), 5, cv::Scalar(0, 0, 255), 2);
}
}
}
cv::imshow("Harrisコーナー検出", result);
cv::waitKey(0);
return 0;
}

この例では、閾値を超えた点を赤い円でマークしています。
対象の画像ごとに細かく閾値を変更(最適化)しないと正しくマークできないことがほとんどです。
Harrisコーナーは、角の位置を高精度で検出できる一方、計算コストがやや高い点に注意が必要です。
FAST
FAST(Features from Accelerated Segment Test)は、高速にコーナーを検出できるアルゴリズムです。
リアルタイム処理に適しており、特にロボティクスやARアプリケーションで広く使われています。
// FASTコーナー検出の例
#include <iostream>
#include <opencv2/features2d.hpp>
#include <opencv2/opencv.hpp>
int main() {
cv::Mat src = cv::imread("sample.jpg", cv::IMREAD_GRAYSCALE);
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// 閾値
int threshold = 50;
// FAST検出器の作成
cv::Ptr<cv::FastFeatureDetector> detector =
cv::FastFeatureDetector::create(threshold);
std::vector<cv::KeyPoint> keypoints;
detector->detect(src, keypoints);
// 検出したポイントを描画
cv::Mat result;
cv::cvtColor(src, result, cv::COLOR_GRAY2BGR);
cv::drawKeypoints(src, keypoints, result, cv::Scalar(0, 255, 0));
cv::imshow("FASTコーナー検出", result);
cv::waitKey(0);
return 0;
}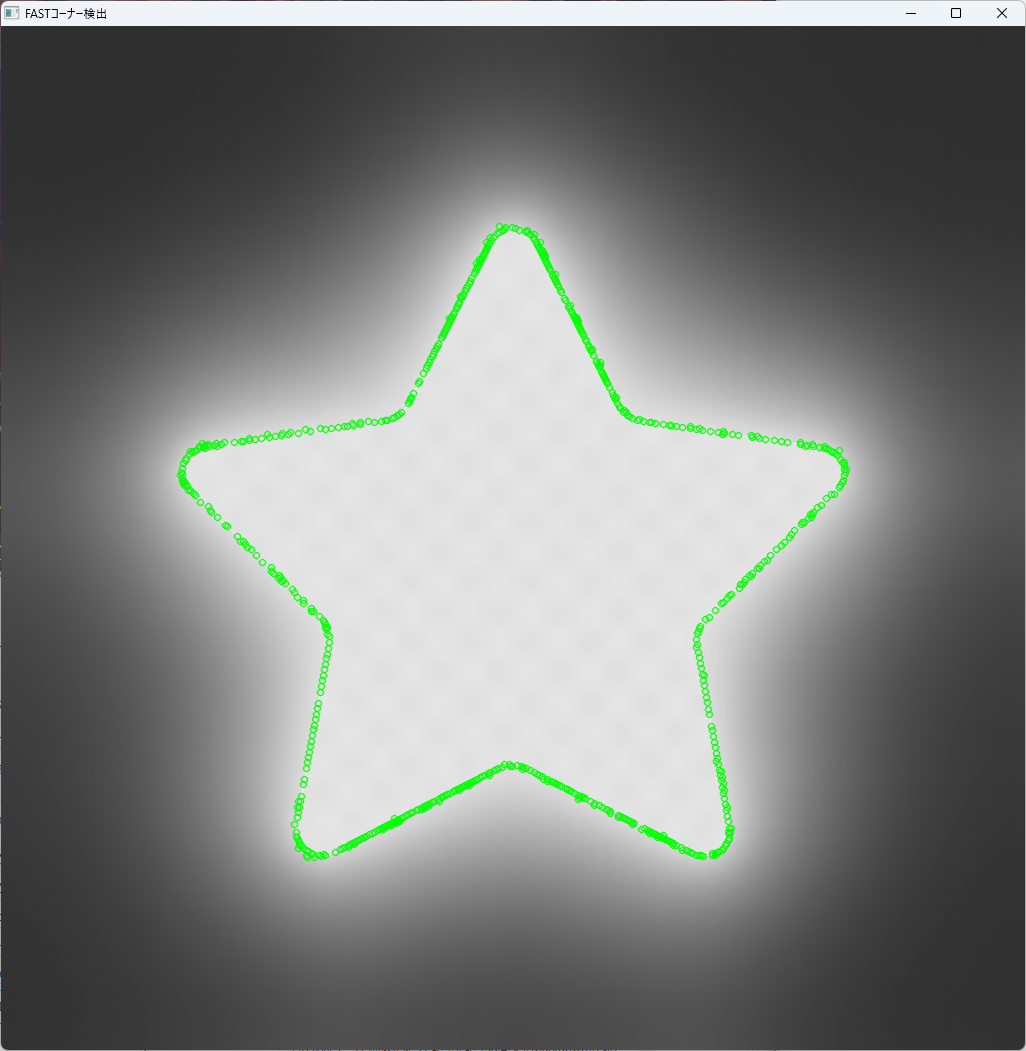
FASTは、閾値を調整することで検出の厳しさを制御でき、非常に高速な処理が可能です。
記述子生成
コーナーや特徴点を検出した後、それらの点の周囲のパターンを記述子として抽出します。
記述子は、特徴点の局所的な情報を符号化し、異なる画像間でのマッチングに用います。
SIFT/SURF
SIFT(Scale-Invariant Feature Transform)とSURF(Speeded-Up Robust Features)は、スケールや回転に対して不変な特徴記述子です。
これらは高い識別能力を持ち、多くのアプリケーションで標準的に使われています。
#include <iostream>
#include <opencv2/opencv.hpp>
#include <opencv2/features2d.hpp>
int main() {
// グレースケールで画像を読み込む
cv::Mat src = cv::imread("sample.jpg", cv::IMREAD_GRAYSCALE);
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// SIFT 検出器の作成
cv::Ptr<cv::SIFT> detector = cv::SIFT::create();
// 特徴点と記述子を格納する変数
std::vector<cv::KeyPoint> keypoints;
cv::Mat descriptors;
// 検出と計算
detector->detectAndCompute(src, cv::noArray(), keypoints, descriptors);
// 結果を表示
std::cout << "検出した特徴点数: " << keypoints.size() << std::endl;
// 特徴点を描画
cv::Mat output;
cv::drawKeypoints(src, keypoints, output, cv::Scalar::all(-1), cv::DrawMatchesFlags::DRAW_RICH_KEYPOINTS);
// ウィンドウ表示
cv::imshow("SIFT特徴点", output);
cv::waitKey(0);
return 0;
}

SURFは特許の関係でOpenCVの標準ビルドには含まれませんが、同様の用途に使われます。
ORB
ORB(Oriented FAST and Rotated BRIEF)は、SIFTやSURFに比べて高速かつオープンソースの特徴記述子です。
回転やスケールに対してある程度の不変性を持ち、リアルタイムアプリケーションに適しています。
// ORBの例
#include <iostream>
#include <opencv2/features2d.hpp>
#include <opencv2/opencv.hpp>
int main() {
cv::Mat src = cv::imread("sample.jpg", cv::IMREAD_GRAYSCALE);
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// ORB検出器の作成
cv::Ptr<cv::ORB> orb = cv::ORB::create(
1000, // nfeatures: 検出する最大特徴点数(増やすと検出数が増える)
1.2f, // scaleFactor: ピラミッドのスケール係数(小さくすると精度向上)
8, // nlevels: ピラミッドのレベル数(増やすとより広範囲に対応)
1, // edgeThreshold:
// エッジでの特徴検出の距離(小さくすると端に強くなる)
0, // firstLevel
2, // WTA_K: 比較するペア数(2 or 3 or 4。多いほど精度↑)
cv::ORB::HARRIS_SCORE, // scoreType:
// Harrisコーナーの代わりにFAST_SCOREも選べる
31, // patchSize
5 // fastThreshold: FASTの閾値(小さくすると検出数↑)
);
std::vector<cv::KeyPoint> keypoints;
cv::Mat descriptors;
orb->detectAndCompute(src, cv::noArray(), keypoints, descriptors);
// 検出した特徴点の数
std::cout << "ORB特徴点数: " << keypoints.size() << std::endl;
// 描画
cv::Mat output;
cv::drawKeypoints(src, keypoints, output, cv::Scalar(255, 255, 0));
cv::imshow("ORB特徴点", output);
cv::waitKey(0);
return 0;
}
ORBは、特許の制約がなく、広く使われているため、実用的な選択肢です。
これらの特徴量抽出手法を適切に選択し、組み合わせることで、画像の内容を効果的に表現し、さまざまな画像認識やマッチングのタスクに応用できます。
次のステップでは、これらの特徴点を用いたマッチングや追跡について解説します。
特徴量マッチング
特徴点のマッチングは、異なる画像間で同一の物体やパターンを見つけ出すための重要なステップです。
抽出した特徴記述子同士を比較し、対応点を見つけることで、画像間の位置関係や変形を推定します。
ここでは、代表的なマッチング手法と外れ値除去の方法について詳しく解説します。
Brute‑Force Matcher
Brute‑Force(総当たり法)マッチャーは、すべての特徴記述子を比較し、最も類似度の高いペアを見つけ出すシンプルな方法です。
比較には、L2距離やHamming距離などを用います。
// Brute-Forceマッチャーの例
#include <opencv2/opencv.hpp>
#include <opencv2/features2d.hpp>
#include <iostream>
int main() {
// 画像の読み込み
cv::Mat img1 = cv::imread("image1.jpg", cv::IMREAD_GRAYSCALE);
cv::Mat img2 = cv::imread("image2.jpg", cv::IMREAD_GRAYSCALE);
if (img1.empty() || img2.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// ORB特徴点と記述子の抽出
cv::Ptr<cv::ORB> orb = cv::ORB::create();
std::vector<cv::KeyPoint> kp1, kp2;
cv::Mat desc1, desc2;
orb->detectAndCompute(img1, cv::noArray(), kp1, desc1);
orb->detectAndCompute(img2, cv::noArray(), kp2, desc2);
// Brute-Forceマッチャーの作成
cv::BFMatcher matcher(cv::NORM_HAMMING);
std::vector<cv::DMatch> matches;
matcher.match(desc1, desc2, matches);
// マッチング結果の描画
cv::Mat result;
cv::drawMatches(img1, kp1, img2, kp2, matches, result);
cv::imshow("Brute-Forceマッチング", result);
cv::waitKey(0);
return 0;
}
この方法はシンプルで実装も容易ですが、計算コストが高く、大量の特徴点を扱う場合は効率が落ちることがあります。
FLANN ベース Matcher
FLANN(Fast Library for Approximate Nearest Neighbors)は、高速な近似最近傍探索アルゴリズムを用いたマッチング手法です。
大規模な特徴記述子セットに対しても高速に処理できるため、実用的です。
// FLANNベースマッチャーの例
#include <opencv2/opencv.hpp>
#include <opencv2/features2d.hpp>
#include <iostream>
int main() {
// 画像の読み込み
cv::Mat img1 = cv::imread("image1.jpg", cv::IMREAD_GRAYSCALE);
cv::Mat img2 = cv::imread("image2.jpg", cv::IMREAD_GRAYSCALE);
if (img1.empty() || img2.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// ORB特徴点と記述子の抽出
cv::Ptr<cv::ORB> orb = cv::ORB::create();
std::vector<cv::KeyPoint> kp1, kp2;
cv::Mat desc1, desc2;
orb->detectAndCompute(img1, cv::noArray(), kp1, desc1);
orb->detectAndCompute(img2, cv::noArray(), kp2, desc2);
// FLANN用に記述子を変換
if (desc1.type() != CV_32F) {
desc1.convertTo(desc1, CV_32F);
}
if (desc2.type() != CV_32F) {
desc2.convertTo(desc2, CV_32F);
}
// FLANNマッチャーの作成
cv::FlannBasedMatcher matcher;
std::vector<cv::DMatch> matches;
matcher.match(desc1, desc2, matches);
// マッチング結果の描画
cv::Mat result;
cv::drawMatches(img1, kp1, img2, kp2, matches, result);
cv::imshow("FLANNマッチング", result);
cv::waitKey(0);
return 0;
}
FLANNは、近似探索を行うため高速でありながら、十分なマッチング精度を保つことができます。
RANSACによる外れ値除去
マッチング結果には、誤った対応(外れ値)が含まれることがあります。
これらを除去し、正確な対応関係を得るためにRANSAC(Random Sample Consensus)を用います。
// RANSACによる外れ値除去の例
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 先にマッチング結果を得ていると仮定
// 例として、matchesとkeypoints1, keypoints2を用意
std::vector<cv::DMatch> matches; // 事前に得たマッチング結果
std::vector<cv::Point2f> pts1, pts2;
// 対応点の抽出
for (const auto& match : matches) {
pts1.push_back(/* keypoints1[match.queryIdx].pt */);
pts2.push_back(/* keypoints2[match.trainIdx].pt */);
}
// アフィン変換やホモグラフィー推定
cv::Mat mask;
cv::Mat H = cv::findHomography(pts1, pts2, cv::RANSAC, 3.0, mask);
// 正常な対応点だけを抽出
std::vector<cv::DMatch> inlierMatches;
for (size_t i = 0; i < matches.size(); ++i) {
if (mask.at<uchar>(i)) {
inlierMatches.push_back(matches[i]);
}
}
// 正しい対応点だけを用いたマッチング結果の描画
// 省略
return 0;
}RANSACは、外れ値を除去し、正確な幾何変換推定を可能にします。
これにより、画像間の位置関係や変形を高精度で推定できるようになります。
これらのマッチング手法と外れ値除去を組み合わせることで、信頼性の高い特徴点対応を実現し、さまざまな画像認識や3D再構築、追跡などの応用に役立てることができます。
物体検出
物体検出は、画像や映像内に存在する特定の物体を識別し、その位置を特定する技術です。
従来の手法から深層学習を用いた高度なモデルまで、多様なアプローチが存在します。
ここでは、古典的なHaar分類器による検出と、深層学習を用いたDNNモジュールでの推論について詳しく解説します。
Haar分類器による検出
Haar分類器は、OpenCVに標準搭載されている古典的な物体検出手法です。
特に顔検出に広く使われており、学習済みのカスケード分類器を利用して高速に検出を行います。
カスケード分類器の利用にはカスケードファイルが必要です。
OpenCVをインストールすると、多くの環境ではhaarcascade_frontalface_default.xmlファイルが自動的に含まれています。以下のようなパスに存在することが多いです。
/usr/share/opencv4/haarcascades/haarcascade_frontalface_default.xmlopencv\sources\data\haarcascades\haarcascade_frontalface_default.xmlカスケードファイルをコピーしてカレントディレクトリに配置するなどをして、使える状態にしておきましょう。
// Haar分類器による顔検出の例
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// カスケード分類器の読み込み
cv::CascadeClassifier face_cascade;
if (!face_cascade.load("haarcascade_frontalface_default.xml")) {
std::cerr << "カスケードファイルの読み込みに失敗しました。" << std::endl;
return -1;
}
// 画像の読み込み
cv::Mat img = cv::imread("face.jpg");
if (img.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// グレースケール変換
cv::Mat gray;
cv::cvtColor(img, gray, cv::COLOR_BGR2GRAY);
cv::equalizeHist(gray, gray);
// 顔検出
std::vector<cv::Rect> faces;
face_cascade.detectMultiScale(gray, faces, 1.1, 3, 0, cv::Size(30, 30));
// 検出した顔に矩形を描画
for (size_t i = 0; i < faces.size(); ++i) {
cv::rectangle(img, faces[i], cv::Scalar(255, 0, 0), 2);
}
cv::imshow("顔検出", img);
cv::waitKey(0);
return 0;
}
サンプル写真(検証用にお使いください)

この方法は、処理が非常に高速であり、リアルタイムアプリケーションに適しています。
ただし、検出精度は深層学習モデルに比べて劣る場合があります。
DNNモジュールでの推論
OpenCVのDNN(Deep Neural Network)モジュールを使えば、深層学習モデルを利用した高精度な物体検出が可能です。
さまざまなフレームワークのモデルをロードし、推論を行うことができます。
Caffeモデルのロード
Caffeは、深層学習のフレームワークの一つで、多くの事前学習済みモデルが公開されています。
// Caffeモデルを用いた物体検出の例
#include <opencv2/dnn.hpp>
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// モデルと設定ファイルのパス
std::string modelFile = "deploy.caffemodel";
std::string configFile = "deploy.prototxt";
// ネットワークの読み込み
cv::dnn::Net net = cv::dnn::readNetFromCaffe(configFile, modelFile);
if (net.empty()) {
std::cerr << "モデルの読み込みに失敗しました。" << std::endl;
return -1;
}
// 画像の読み込み
cv::Mat img = cv::imread("test.jpg");
if (img.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// 入力Blobの作成
cv::Mat inputBlob = cv::dnn::blobFromImage(img, 1.0, cv::Size(300, 300), cv::Scalar(104, 117, 123));
net.setInput(inputBlob);
// 推論
cv::Mat detection = net.forward();
// 検出結果の解析
// 省略:検出結果の閾値処理と描画処理を行う
return 0;
}Caffeモデルは、画像の前処理や推論の設定が必要ですが、高い検出精度を誇ります。
TensorFlowモデルのロード
TensorFlowは、Googleが開発した深層学習フレームワークで、多くの高性能モデルが公開されています。
// TensorFlowモデルのロード例
#include <opencv2/dnn.hpp>
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// モデルのパス
std::string modelPath = "frozen_inference_graph.pb";
// ネットワークの読み込み
cv::dnn::Net net = cv::dnn::readNetFromTensorflow(modelPath);
if (net.empty()) {
std::cerr << "TensorFlowモデルの読み込みに失敗しました。" << std::endl;
return -1;
}
// 画像の読み込みと前処理
cv::Mat img = cv::imread("test.jpg");
if (img.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat inputBlob = cv::dnn::blobFromImage(img, 1.0, cv::Size(300, 300), cv::Scalar(0,0,0), true, false);
net.setInput(inputBlob);
// 推論
cv::Mat detection = net.forward();
// 検出結果の解析と描画
// 省略
return 0;
}TensorFlowモデルは、readNetFromTensorflow関数を使ってロードし、推論を行います。
ONNXモデルの活用
ONNX(Open Neural Network Exchange)は、異なるフレームワーク間でモデルを共有できるフォーマットです。
OpenCVはreadNetFromONNX関数をサポートしており、さまざまなモデルを簡単に利用できます。
// ONNXモデルのロード例
#include <opencv2/dnn.hpp>
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// ONNXモデルのパス
std::string onnxModel = "model.onnx";
// ネットワークの読み込み
cv::dnn::Net net = cv::dnn::readNetFromONNX(onnxModel);
if (net.empty()) {
std::cerr << "ONNXモデルの読み込みに失敗しました。" << std::endl;
return -1;
}
// 画像の前処理と推論
cv::Mat img = cv::imread("test.jpg");
if (img.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat inputBlob = cv::dnn::blobFromImage(img, 1.0, cv::Size(300, 300), cv::Scalar(0,0,0));
net.setInput(inputBlob);
cv::Mat detection = net.forward();
// 検出結果の解析と描画
// 省略
return 0;
}ONNXは、モデルの互換性と移植性を高め、多様な深層学習モデルをOpenCV上で利用できるようにします。
これらの深層学習モデルを用いた物体検出は、従来の手法に比べて高い精度と柔軟性を持ち、多くの実用的なアプリケーションに適用されています。
次のステップでは、これらの検出結果を活用した応用例について解説します。
カメラキャリブレーションと歪み補正
カメラキャリブレーションは、撮影に用いるカメラの内部パラメータやレンズの歪みを正確に推定し、画像の幾何学的な補正を行うための重要な工程です。
歪み補正を適切に行うことで、計測や画像解析の精度を向上させることができます。
ここでは、チェスボードパターンを用いたキャリブレーションと、リマッピングによる歪み補正について詳しく解説します。
チェスボード検出によるキャリブレーション
チェスボードパターンは、格子状の黒白の正方形からなる標準的なキャリブレーションターゲットです。
画像内のチェスボードのコーナーを検出し、その情報をもとにカメラの内部パラメータや歪み係数を推定します。
内部パラメータ推定
内部パラメータは、カメラの焦点距離や主点位置などを表し、画像座標系と実世界座標系の関係を定義します。
// チェスボードコーナー検出とキャリブレーションの例
#include <opencv2/opencv.hpp>
#include <vector>
#include <iostream>
int main() {
// チェスボードのコーナー数(例:9x6)
cv::Size patternSize(9, 6);
// 3Dの実世界座標(Z=0平面上に配置)
std::vector<cv::Point3f> objectPoints;
for (int i = 0; i < patternSize.height; ++i) {
for (int j = 0; j < patternSize.width; ++j) {
objectPoints.emplace_back(j, i, 0);
}
}
// 画像のリスト(複数画像を用意)
std::vector<cv::Mat> images; // 画像をロードして格納
// 例:images.push_back(cv::imread("calib1.jpg")); など
// 画像内のコーナー検出結果
std::vector<std::vector<cv::Point2f>> imagePoints;
std::vector<std::vector<cv::Point3f>> objectPointsVec;
for (const auto& img : images) {
std::vector<cv::Point2f> corners;
bool found = cv::findChessboardCorners(img, patternSize, corners);
if (found) {
cv::Mat gray;
cv::cvtColor(img, gray, cv::COLOR_BGR2GRAY);
cv::cornerSubPix(gray, corners, cv::Size(11, 11), cv::Size(-1, -1),
cv::TermCriteria(cv::TermCriteria::EPS + cv::TermCriteria::COUNT, 30, 0.1));
imagePoints.push_back(corners);
objectPointsVec.push_back(objectPoints);
}
}
// カメラキャリブレーション
cv::Mat cameraMatrix, distCoeffs;
std::vector<cv::Mat> rvecs, tvecs;
cv::calibrateCamera(objectPointsVec, imagePoints, images[0].size(), cameraMatrix, distCoeffs, rvecs, tvecs);
std::cout << "内部パラメータ:\n" << cameraMatrix << std::endl;
std::cout << "歪み係数:\n" << distCoeffs << std::endl;
return 0;
}このコードでは、複数の画像からチェスボードのコーナーを検出し、calibrateCamera関数を用いて内部パラメータと歪み係数を推定しています。
歪み係数の補正
推定された歪み係数を用いて、画像の歪みを補正します。
これにより、画像の幾何学的な歪みを除去し、正確な計測や解析が可能となります。
// 歪み補正の例
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 画像とキャリブレーション結果
cv::Mat src = cv::imread("distorted.jpg");
cv::Mat cameraMatrix, distCoeffs;
// 事前にキャリブレーションで得た値を設定
cameraMatrix = (cv::Mat_<double>(3,3) << /* 内部パラメータ */);
distCoeffs = (cv::Mat_<double>(1,5) << /* 歪み係数 */);
cv::Mat dst;
cv::undistort(src, dst, cameraMatrix, distCoeffs);
cv::imshow("歪み補正後", dst);
cv::waitKey(0);
return 0;
}undistort関数を使うことで、歪みを除去した画像を得ることができます。
リマッピングによる歪み補正
リマッピングは、歪み補正のために事前に計算したマップを使って画像のピクセル位置を再配置する方法です。
これにより、より高精度な歪み補正や特殊な補正効果を実現できます。
// リマッピングによる歪み補正の例
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 画像とキャリブレーション結果
cv::Mat src = cv::imread("distorted.jpg");
cv::Mat cameraMatrix, distCoeffs;
// 事前にキャリブレーションで得た値を設定
cameraMatrix = (cv::Mat_<double>(3,3) << /* 内部パラメータ */);
distCoeffs = (cv::Mat_<double>(1,5) << /* 歪み係数 */);
// 画像サイズ
cv::Size imageSize = src.size();
// 逆歪みマップの作成
cv::Mat map1, map2;
cv::initUndistortRectifyMap(cameraMatrix, distCoeffs, cv::Mat(),
cameraMatrix, imageSize, CV_16SC2, map1, map2);
// リマッピング
cv::Mat undistorted;
cv::remap(src, undistorted, map1, map2, cv::INTER_LINEAR);
cv::imshow("リマッピングによる歪み補正", undistorted);
cv::waitKey(0);
return 0;
}initUndistortRectifyMapで逆歪みマップを作成し、remapで画像を再配置します。
これにより、歪み補正の精度を高めることが可能です。
これらのキャリブレーションと歪み補正の技術を適用することで、画像の幾何学的な正確性を向上させ、計測や認識の精度を大きく改善できます。
次のステップでは、これらの補正技術を応用した具体的な事例について解説します。
幾何変換
画像の幾何変換は、画像の座標系を変換し、位置や形状を操作する技術です。
これにより、画像の回転、拡大縮小、平行移動、歪み補正など、多様な画像処理が可能となります。
OpenCVでは、アフィン変換や透視変換をはじめとした多くの幾何変換手法をサポートしています。
アフィン変換
アフィン変換は、平行移動、回転、拡大縮小、せん断などの線形変換を組み合わせたもので、画像の形状を保ったまま変換を行います。
3つの対応点を指定して変換行列を求め、その行列を用いて画像を変換します。
// アフィン変換の例
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 入力画像の読み込み
cv::Mat src = cv::imread("input.jpg");
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// 変換前の3点と変換後の3点を定義
std::vector<cv::Point2f> srcPoints = {cv::Point2f(0, 0), cv::Point2f(src.cols - 1, 0), cv::Point2f(0, src.rows - 1)};
std::vector<cv::Point2f> dstPoints = {cv::Point2f(50, 50), cv::Point2f(src.cols - 50, 50), cv::Point2f(50, src.rows - 50)};
// アフィン変換行列の計算
cv::Mat affineMat = cv::getAffineTransform(srcPoints, dstPoints);
// 画像の変換
cv::Mat dst;
cv::warpAffine(src, dst, affineMat, src.size());
cv::imshow("アフィン変換結果", dst);
cv::waitKey(0);
return 0;
}
この例では、3つの点を対応させてアフィン変換行列を求め、その行列を使って画像を変形しています。
透視変換(Perspective Transform)
透視変換は、カメラの視点や歪みを考慮した変換で、四つの対応点を指定して画像の投影面を変換します。
これにより、画像の歪み補正や、異なる視点からの画像の合成が可能です。
// 透視変換の例
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 入力画像の読み込み
cv::Mat src = cv::imread("input.jpg");
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// 変換前と変換後の4点を定義
std::vector<cv::Point2f> srcPoints = {cv::Point2f(0, 0), cv::Point2f(src.cols - 1, 0), cv::Point2f(src.cols - 1, src.rows - 1), cv::Point2f(0, src.rows - 1)};
std::vector<cv::Point2f> dstPoints = {cv::Point2f(100, 50), cv::Point2f(src.cols - 100, 80), cv::Point2f(src.cols - 50, src.rows - 50), cv::Point2f(80, src.rows - 100)};
// 透視変換行列の計算
cv::Mat perspectiveMat = cv::getPerspectiveTransform(srcPoints, dstPoints);
// 画像の変換
cv::Mat dst;
cv::warpPerspective(src, dst, perspectiveMat, src.size());
cv::imshow("透視変換結果", dst);
cv::waitKey(0);
return 0;
}
この例では、四つの点を対応させて透視変換行列を計算し、画像を変形させています。
remapを使ったリマッピング
remapは、あらかじめ計算したマップを使って画像のピクセル位置を再配置することで、歪み補正や特殊な変換を行います。
initUndistortRectifyMapと組み合わせて、歪み補正や幾何学的な変形を高精度に実現します。
#include <iostream>
#include <opencv2/opencv.hpp>
#include <vector>
int main() {
// 1) 入力画像の読み込み
cv::Mat src = cv::imread("sample.jpg");
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::imshow("Original", src);
// 2) 位置調整(アフィン変換による平行移動+回転)
// 回転中心:画像中心、回転角度:30度、拡大率:1.0
cv::Point2f center(src.cols * 0.5f, src.rows * 0.5f);
double angle = 30.0, scale = 1.0;
cv::Mat affineMat = cv::getRotationMatrix2D(center, angle, scale);
// 30ピクセル右に平行移動
affineMat.at<double>(0, 2) += 30;
affineMat.at<double>(1, 2) += 0;
cv::Mat affineDst;
cv::warpAffine(src, affineDst, affineMat, src.size());
cv::imshow("Affine Transform", affineDst);
// 3) 視点変換(射影変換/パースペクティブ変換)
// 入力側4点と出力側4点を指定
std::vector<cv::Point2f> srcQuad, dstQuad;
srcQuad.push_back(cv::Point2f(0, 0));
srcQuad.push_back(cv::Point2f(src.cols, 0));
srcQuad.push_back(cv::Point2f(src.cols, src.rows));
srcQuad.push_back(cv::Point2f(0, src.rows));
dstQuad.push_back(cv::Point2f(50, 50));
dstQuad.push_back(cv::Point2f(src.cols - 30, 30));
dstQuad.push_back(cv::Point2f(src.cols - 10, src.rows - 20));
dstQuad.push_back(cv::Point2f(30, src.rows - 10));
cv::Mat perspMat = cv::getPerspectiveTransform(srcQuad, dstQuad);
cv::Mat perspDst;
cv::warpPerspective(src, perspDst, perspMat, src.size());
cv::imshow("Perspective Transform", perspDst);
// 4) 歪み補正(リマッピング)
// サンプルのカメラ内部パラメータと歪み係数
cv::Mat cameraMatrix =
(cv::Mat_<double>(3, 3) << 800.0, 0.0, src.cols * 0.5, 0.0, 800.0,
src.rows * 0.5, 0.0, 0.0, 1.0);
cv::Mat distCoeffs = (cv::Mat_<double>(1, 5) << -0.5, 0.25, 0.0, 0.0, 0.0);
cv::Mat map1, map2;
cv::initUndistortRectifyMap(cameraMatrix, distCoeffs, cv::Mat(),
cameraMatrix, src.size(), CV_16SC2, map1, map2);
cv::Mat undistorted;
cv::remap(src, undistorted, map1, map2, cv::INTER_LINEAR);
cv::imshow("Undistorted (Remap)", undistorted);
// すべてのウィンドウ待機
cv::waitKey(0);
return 0;
}




この方法では、事前に計算したマップを用いて画像のピクセルを再配置し、歪みや歪み以外の幾何学的変形を高精度に補正します。
これらの幾何変換技術を適切に使いこなすことで、画像の位置調整や歪み補正、視点変換など、多彩な画像処理を実現できます。
次のステップでは、これらの技術を応用した具体的な事例について解説します。
ステレオビジョン
ステレオビジョンは、二つのカメラから得られる画像を用いて、シーンの深度情報を推定する技術です。
左右の画像の対応点を見つけ、その視差(画像間の対応点のずれ)を計測することで、距離や奥行きの情報を得ることができます。
ここでは、ステレオ画像の整列と視差マップの生成方法について詳しく解説します。
ステレオ画像の整列(Rectification)
ステレオ画像の整列(Rectification)は、左右の画像を同じ平面上に投影し、対応点が同じ水平線上に並ぶように変換する処理です。
これにより、視差計算が容易になり、対応点の探索範囲を狭めることができます。
// ステレオ画像の整列(Rectification)の例
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 左右画像の読み込み
cv::Mat leftImg = cv::imread("left.jpg");
cv::Mat rightImg = cv::imread("right.jpg");
if (leftImg.empty() || rightImg.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// キャリブレーションパラメータ(例:内部パラメータと回転・並進行列)
cv::Mat cameraMatrix1, distCoeffs1, cameraMatrix2, distCoeffs2;
cv::Mat R, T, R1, R2, P1, P2, Q;
// 事前にキャリブレーション済みのパラメータを設定
// 例:cv::stereoRectify()を用いて計算
cv::stereoRectify(cameraMatrix1, distCoeffs1, cameraMatrix2, distCoeffs2,
leftImg.size(), R, T, R1, R2, P1, P2, Q);
// マップの作成
cv::Mat map1x, map1y, map2x, map2y;
cv::initUndistortRectifyMap(cameraMatrix1, distCoeffs1, R1, P1, leftImg.size(), CV_16SC2, map1x, map1y);
cv::initUndistortRectifyMap(cameraMatrix2, distCoeffs2, R2, P2, rightImg.size(), CV_16SC2, map2x, map2y);
// 画像のリマッピング
cv::Mat rectLeft, rectRight;
cv::remap(leftImg, rectLeft, map1x, map1y, cv::INTER_LINEAR);
cv::remap(rightImg, rectRight, map2x, map2y, cv::INTER_LINEAR);
// 結果の表示
cv::imshow("整列済み左画像", rectLeft);
cv::imshow("整列済み右画像", rectRight);
cv::waitKey(0);
return 0;
}この例では、stereoRectifyを用いて整列用のパラメータを計算し、その後initUndistortRectifyMapとremapで画像を整列させています。
視差マップ生成
視差マップは、左右画像の対応点の水平視差をピクセル単位で表した画像です。
視差値が大きいほど、対象物までの距離が近いことを示します。
視差マップの生成には、ブロックマッチングやSemi‑Global Matching(SGM)といったアルゴリズムが用いられます。
ブロックマッチング
ブロックマッチングは、画像内の小さなブロック(パッチ)を比較し、最も類似度の高い位置を探索する方法です。
計算が高速で実装も容易ですが、細かいディテールや平坦な領域では精度が低下しやすいです。
// ブロックマッチングによる視差推定の例
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 整列済みの左右画像
cv::Mat leftImg = cv::imread("rect_left.jpg", cv::IMREAD_GRAYSCALE);
cv::Mat rightImg = cv::imread("rect_right.jpg", cv::IMREAD_GRAYSCALE);
if (leftImg.empty() || rightImg.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// ステereoBMの作成
int numDisparities = 16 * 5; // 5段階の視差範囲
int blockSize = 15; // ブロックサイズ
cv::Ptr<cv::StereoBM> stereo = cv::StereoBM::create(numDisparities, blockSize);
cv::Mat disparity;
stereo->compute(leftImg, rightImg, disparity);
// 視差マップの表示
cv::normalize(disparity, disparity, 0, 255, cv::NORM_MINMAX);
disparity.convertTo(disparity, CV_8U);
cv::imshow("視差マップ(ブロックマッチング)", disparity);
cv::waitKey(0);
return 0;
}この例では、StereoBMを用いて視差マップを計算し、正規化して表示しています。
Semi‑Global Matching
Semi‑Global Matching(SGM)は、ブロックマッチングの一種で、グローバル最適化に近い結果を高速に得られる手法です。
より滑らかで正確な視差マップを生成でき、平坦な領域やエッジの多い部分でも高い精度を保ちます。
// Semi-Global Matchingによる視差推定の例
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 整列済みの左右画像
cv::Mat leftImg = cv::imread("rect_left.jpg", cv::IMREAD_GRAYSCALE);
cv::Mat rightImg = cv::imread("rect_right.jpg", cv::IMREAD_GRAYSCALE);
if (leftImg.empty() || rightImg.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// SGBMの作成
int minDisparity = 0;
int numDisparities = 16 * 8; // 128
int blockSize = 5;
cv::Ptr<cv::StereoSGBM> sgbm = cv::StereoSGBM::create(minDisparity, numDisparities, blockSize);
sgbm->setP1(8 * blockSize * blockSize);
sgbm->setP2(32 * blockSize * blockSize);
sgbm->setMode(cv::StereoSGBM::MODE_SGBM);
cv::Mat disparity;
sgbm->compute(leftImg, rightImg, disparity);
// 視差マップの正規化と表示
cv::normalize(disparity, disparity, 0, 255, cv::NORM_MINMAX);
disparity.convertTo(disparity, CV_8U);
cv::imshow("視差マップ(SGM)", disparity);
cv::waitKey(0);
return 0;
}この例では、StereoSGBMを用いて高精度な視差マップを生成しています。
これらの技術を組み合わせることで、シーンの奥行き情報を高精度に取得でき、ロボティクスや3D再構築、ナビゲーションなど多様な応用に役立てることが可能です。
次のステップでは、これらの深度情報を活用した具体的な応用例について解説します。
動画像解析
動画像解析は、動画内の動きや変化を検出・追跡し、シーンの理解や異常検知、行動認識などに応用される重要な技術です。
背景差分やオプティカルフローは、その中でも基本的かつ広く使われている手法です。
ここでは、背景差分による動体検出と、オプティカルフロー解析について詳しく解説します。
背景差分による動体検出
背景差分は、静止背景と比較して動いている物体を検出する手法です。
背景モデルを構築し、新しいフレームとの差分を計算することで、動いている部分を抽出します。
MOG2
MOG2(Mixture of Gaussians 2)は、背景モデルの更新にガウス混合モデルを用いた手法で、照明変化や動きの多様性に対して頑健です。
// MOG2による背景差分の例
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 背景差分器の作成
cv::Ptr<cv::BackgroundSubtractor> pBackSub = cv::createBackgroundSubtractorMOG2();
// 動画キャプチャの開始
cv::VideoCapture cap(0); // カメラから取得
if (!cap.isOpened()) {
std::cerr << "カメラのオープンに失敗しました。" << std::endl;
return -1;
}
cv::Mat frame, fgMask;
while (true) {
cap >> frame;
if (frame.empty()) break;
// 背景差分の適用
pBackSub->apply(frame, fgMask);
// 膨張処理でノイズ除去
cv::dilate(fgMask, fgMask, cv::Mat(), cv::Point(-1, -1), 2);
// 動体部分を抽出
cv::imshow("背景差分(MOG2)", fgMask);
if (cv::waitKey(30) >= 0) break;
}
cap.release();
return 0;
}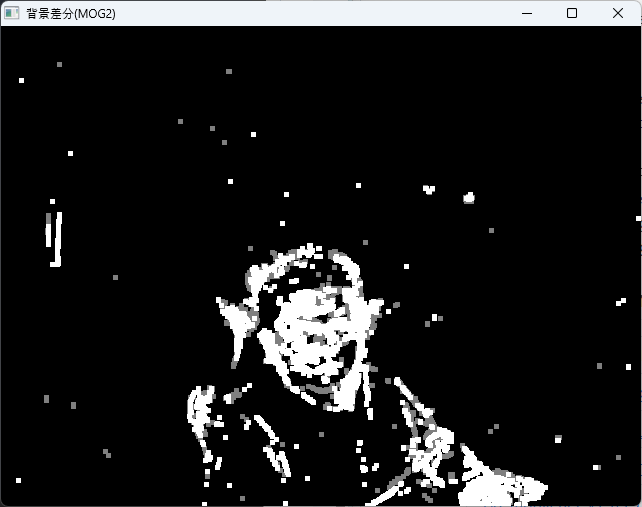
この例では、カメラからの映像に対して背景差分を行い、動いている部分を検出しています。
KNN
KNN(K-Nearest Neighbors)も背景差分に用いられる手法で、背景モデルを各ピクセルの履歴から学習し、動きのある部分を検出します。
// KNNによる背景差分の例
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 背景差分器の作成
cv::Ptr<cv::BackgroundSubtractor> pBackSub = cv::createBackgroundSubtractorKNN();
// 動画キャプチャの開始
cv::VideoCapture cap(0);
if (!cap.isOpened()) {
std::cerr << "カメラのオープンに失敗しました。" << std::endl;
return -1;
}
cv::Mat frame, fgMask;
while (true) {
cap >> frame;
if (frame.empty()) break;
// 背景差分の適用
pBackSub->apply(frame, fgMask);
// ノイズ除去
cv::erode(fgMask, fgMask, cv::Mat());
cv::dilate(fgMask, fgMask, cv::Mat());
// 動体の検出
cv::imshow("背景差分(KNN)", fgMask);
if (cv::waitKey(30) >= 0) break;
}
cap.release();
return 0;
}KNNは、動きの検出において比較的安定しており、照明変化や背景の動きに対しても適応します。
オプティカルフロー解析
オプティカルフローは、連続するフレーム間のピクセルの動きを推定する手法です。
物体の追跡や動きの解析に広く使われており、Lucas-Kanade法とFarneback法が代表的です。
Lucas‑Kanade法
Lucas-Kanade法は、局所的な領域内での動きを推定し、少量の動きに対して高い精度を持ちます。
小さな変位に適しており、特徴点の追跡に用いられることが多いです。
// Lucas-Kanade法による特徴点追跡の例
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 2フレームの画像
cv::Mat prevGray, currGray;
cv::VideoCapture cap(0);
if (!cap.isOpened()) {
std::cerr << "カメラのオープンに失敗しました。" << std::endl;
return -1;
}
// 最初のフレーム
cv::Mat prevFrame;
cap >> prevFrame;
cv::cvtColor(prevFrame, prevGray, cv::COLOR_BGR2GRAY);
// Shi-Tomasiコーナー検出
std::vector<cv::Point2f> prevPts;
cv::goodFeaturesToTrack(prevGray, prevPts, 100, 0.3, 7);
while (true) {
cv::Mat frame, gray;
cap >> frame;
if (frame.empty()) break;
cv::cvtColor(frame, gray, cv::COLOR_BGR2GRAY);
// オプティカルフローの計算
std::vector<cv::Point2f> currPts;
std::vector<uchar> status;
std::vector<float> err;
cv::calcOpticalFlowPyrLK(prevGray, gray, prevPts, currPts, status, err);
// 正常に追跡できた点だけを描画
for (size_t i = 0; i < prevPts.size(); ++i) {
if (status[i]) {
cv::line(frame, prevPts[i], currPts[i], cv::Scalar(0, 255, 0), 2);
cv::circle(frame, currPts[i], 3, cv::Scalar(0, 0, 255), -1);
}
}
cv::imshow("Lucas-Kanadeオプティカルフロー", frame);
if (cv::waitKey(30) >= 0) break;
// 次のフレームの準備
prevGray = gray.clone();
prevPts.clear();
for (size_t i = 0; i < currPts.size(); ++i) {
if (status[i]) prevPts.push_back(currPts[i]);
}
}
return 0;
}この例では、特徴点の追跡を行い、動きの方向と大きさを可視化しています。
Farneback法
Farneback法は、密なオプティカルフローを推定し、画像全体の動き場を計算します。
滑らかで連続的な動きの推定に適しており、背景の動きや大きな変位も捉えることができます。
// Farneback法による密なオプティカルフローの例
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 連続する2フレーム
cv::VideoCapture cap(0);
if (!cap.isOpened()) {
std::cerr << "カメラのオープンに失敗しました。" << std::endl;
return -1;
}
cv::Mat prevFrame, prevGray, currFrame, currGray;
cap >> prevFrame;
cv::cvtColor(prevFrame, prevGray, cv::COLOR_BGR2GRAY);
while (true) {
cap >> currFrame;
if (currFrame.empty()) break;
cv::cvtColor(currFrame, currGray, cv::COLOR_BGR2GRAY);
// オプティカルフローの計算
cv::Mat flow;
cv::calcOpticalFlowFarneback(prevGray, currGray, flow, 0.5, 3, 15, 3, 5, 1.2, 0);
// フローの可視化
cv::Mat flowParts[2];
cv::split(flow, flowParts);
cv::Mat magnitude, angle;
cv::cartToPolar(flowParts[0], flowParts[1], magnitude, angle, true);
// 表示用画像の作成
cv::Mat hsv[3], hsvImage, bgrImage;
hsv[0] = angle;
cv::normalize(magnitude, hsv[1], 0, 255, cv::NORM_MINMAX);
hsv[2] = cv::Mat::ones(angle.size(), CV_32F) * 255;
cv::merge(hsv, 3, hsvImage);
hsvImage.convertTo(hsvImage, CV_8U);
cv::cvtColor(hsvImage, bgrImage, cv::COLOR_HSV2BGR);
cv::imshow("Farnebackオプティカルフロー", bgrImage);
if (cv::waitKey(30) >= 0) break;
prevGray = currGray.clone();
}
return 0;
}この例では、動きの方向と大きさを色相と明度で表現し、動き場を可視化しています。
これらの動画像解析技術を適用することで、動画内の動きや変化を詳細に把握し、監視システムや行動解析、ロボット制御など多様な応用に役立てることができます。
物体追跡
物体追跡は、動画内で特定の対象物を継続的に追跡し、その動きや位置を把握する技術です。
シングルオブジェクトの追跡から複数の対象物を同時に追跡するマルチオブジェクト追跡まで、多様な手法が存在します。
ここでは、代表的なシングルオブジェクトトラッカーのKCFとCSRT、そしてマルチオブジェクト追跡について解説します。
シングルオブジェクトトラッカー
シングルオブジェクトトラッカーは、動画の中で一つの対象物を追跡するためのアルゴリズムです。
対象の初期位置を設定し、その後のフレームで位置を更新し続けます。
KCF
KCF(Kernelized Correlation Filters)は、高速かつ高精度な追跡アルゴリズムです。
opencv_trackingのリンクが必要です。注意してください。例:-lopencv_tracking
カーネル化された相関フィルタを用いて、対象の特徴を効率的に学習し、追跡します。
// KCFトラッカーの例
#include <opencv2/opencv.hpp>
#include <opencv2/tracking.hpp>
#include <iostream>
int main() {
cv::VideoCapture cap(0);
if (!cap.isOpened()) {
std::cerr << "カメラのオープンに失敗しました。" << std::endl;
return -1;
}
cv::Mat frame;
cap >> frame;
if (frame.empty()) return -1;
// 初期ROIの設定(例:手動で選択)
cv::Rect2d roi = cv::selectROI("追跡対象の選択", frame);
if (roi.width == 0 || roi.height == 0) return -1;
// KCFトラッカーの作成
cv::Ptr<cv::Tracker> tracker = cv::TrackerKCF::create();
tracker->init(frame, roi);
while (true) {
cap >> frame;
if (frame.empty()) break;
// 追跡の更新
bool ok = tracker->update(frame, roi);
if (ok) {
cv::rectangle(frame, roi, cv::Scalar(255, 0, 0), 2);
} else {
cv::putText(frame, "追跡失敗", cv::Point(50, 50), cv::FONT_HERSHEY_SIMPLEX, 1, cv::Scalar(0, 0, 255), 2);
}
cv::imshow("KCF追跡", frame);
if (cv::waitKey(30) == 27) break; // ESCキーで終了
}
return 0;
}この例では、最初に追跡対象を手動で選択し(ドラッグで選択してエンターキーを押す)、その後追跡を継続します。
角度が都度変わる顔などは、追跡が行えるようになるまで少し時間がかかる場合があります。
KCFは高速でありながら追跡精度も高いため、多くの実用シーンで利用されています。
CSRT
CSRT(Channel and Spatial Reliability Tracking)は、追跡の精度とロバスト性に優れたアルゴリズムです。
opencv_trackingのリンクが必要です。注意してください。例:-lopencv_tracking
特徴の空間的な信頼性を考慮し、追跡の安定性を向上させています。
// main.cpp
#include <iostream>
#include <opencv2/opencv.hpp>
#include <opencv2/tracking.hpp>
int main() {
// カメラをオープン
cv::VideoCapture cap(0);
if (!cap.isOpened()) {
std::cerr << "カメラのオープンに失敗しました。" << std::endl;
return -1;
}
cv::Mat frame;
cap >> frame;
if (frame.empty()) return -1;
// 初期追跡領域をユーザに選択させる
cv::Rect roi = cv::selectROI("追跡対象の選択", frame);
if (roi.width == 0 || roi.height == 0) return -1;
// CSRT トラッカーを生成
cv::Ptr<cv::TrackerCSRT> tracker = cv::TrackerCSRT::create();
tracker->init(frame, roi);
while (true) {
cap >> frame;
if (frame.empty()) break;
// トラッカーで追跡領域を更新
bool ok = tracker->update(frame, roi);
if (ok) {
// 追跡成功:緑色の矩形を描画
cv::rectangle(frame, roi, cv::Scalar(0, 255, 0), 2);
} else {
// 追跡失敗:赤色のテキストを表示
cv::putText(frame, "追跡失敗", cv::Point(50, 50),
cv::FONT_HERSHEY_SIMPLEX, 1, cv::Scalar(0, 0, 255), 2);
}
// 結果をウィンドウに表示
cv::imshow("CSRT追跡", frame);
if (cv::waitKey(30) == 27) break; // ESC キーで終了
}
return 0;
}
CSRTは追跡の安定性が高いため、対象の形状や外観が変化しやすい場合に適しています。
マルチオブジェクトトラッキング
マルチオブジェクト追跡は、複数の対象物を同時に追跡する技術です。
複数の追跡器を個別に管理したり、複合的なアルゴリズムを用いたりして、シーン内の複数の対象をリアルタイムで追跡します。
opencv_trackingのリンクが必要です。注意してください。例:-lopencv_tracking
OpenCVには標準でマルチオブジェクト追跡のための高レベルAPIはありませんが、複数のシングルオブジェクトトラッカーを管理することで実現可能です。
#include <iostream>
#include <opencv2/opencv.hpp>
#include <opencv2/tracking.hpp>
#include <vector>
int main() {
// カメラを開く
cv::VideoCapture cap(0);
if (!cap.isOpened()) {
std::cerr << "カメラのオープンに失敗しました。" << std::endl;
return -1;
}
cv::Mat frame;
cap >> frame;
if (frame.empty()) {
std::cerr << "フレームが取得できませんでした。" << std::endl;
return -1;
}
// ROI 選択ウィンドウの準備
cv::namedWindow("追跡対象の選択", cv::WINDOW_NORMAL);
cv::imshow("追跡対象の選択", frame);
// 複数のROIを手動で選択
std::vector<cv::Rect> rois;
int numObjects = 2; // 例:2つの対象
for (int i = 0; i < numObjects; ++i) {
// selectROI は cv::Rect2d を返すが、cv::Rect
// に代入すると切り捨てで整数化される
cv::Rect roi = cv::selectROI("追跡対象の選択", frame);
if (roi.width == 0 || roi.height == 0) continue;
rois.push_back(roi);
}
cv::destroyWindow("追跡対象の選択");
// 複数のトラッカーを作成
std::vector<cv::Ptr<cv::Tracker>> trackers;
for (const auto& roi : rois) {
auto tracker = cv::TrackerKCF::create();
tracker->init(frame, roi);
trackers.push_back(tracker);
}
// メインループ
while (true) {
cap >> frame;
if (frame.empty()) break;
// 各トラッカーを更新して描画
for (size_t i = 0; i < trackers.size(); ++i) {
bool ok = trackers[i]->update(frame, rois[i]);
if (ok) {
// 追跡領域を青い矩形で描画
cv::rectangle(frame, rois[i], cv::Scalar(255, 0, 0), 2);
} else {
// 追跡失敗時にテキストを表示
cv::putText(frame, "追跡失敗",
cv::Point(50, 50 + 30 * static_cast<int>(i)),
cv::FONT_HERSHEY_SIMPLEX, 0.8,
cv::Scalar(0, 0, 255), 2);
}
}
// 結果表示
cv::imshow("マルチオブジェクト追跡", frame);
// ESCキーで終了
if (cv::waitKey(30) == 27) {
std::cout << "ESCキーが押されました。終了します。" << std::endl;
break;
}
}
return 0;
}
この例では、複数の対象を手動で選択し、それぞれに追跡器を割り当てて追跡しています。
実用的には、対象の自動検出と追跡の連携や、追跡器の最適化が必要です。
これらの追跡技術を適用することで、監視システムやインタラクティブなアプリケーション、ロボットのナビゲーションなど、多彩なシーンで対象物の動きを正確に追跡・解析できます。
GPU活用と処理高速化
画像処理やコンピュータビジョンの処理速度を向上させるためには、GPUの並列処理能力や最適化技術を活用することが不可欠です。
OpenCVは、CUDAやT‑API、マルチスレッド処理をサポートしており、これらを適切に利用することで、リアルタイム処理や大規模データの高速処理が可能となります。
CUDAモジュールの利用
CUDA(Compute Unified Device Architecture)は、NVIDIAのGPUを用いた並列計算プラットフォームです。
OpenCVのCUDAモジュールを使えば、画像処理の多くの演算をGPU上で高速に実行できます。
// CUDAを用いた画像の高速ぼかし処理例
#include <opencv2/opencv.hpp>
#include <opencv2/cudaimgproc.hpp>
#include <iostream>
int main() {
// CPU上の画像を読み込み
cv::Mat srcHost = cv::imread("input.jpg");
if (srcHost.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// GPUメモリに画像を転送
cv::cuda::GpuMat srcDevice, dstDevice;
srcDevice.upload(srcHost);
// CUDAのGaussianBlurを適用
cv::cuda::GaussianBlur(srcDevice, dstDevice, cv::Size(15, 15), 0);
// 結果をCPUにダウンロード
cv::Mat dstHost;
dstDevice.download(dstHost);
cv::imshow("GPU高速ぼかし", dstHost);
cv::waitKey(0);
return 0;
}この例では、GPU上でガウシアンぼかしを行い、処理時間を大幅に短縮しています。
CUDA対応の関数は、従来のCPU版よりも高速に動作します。
T‑APIによる最適化
T‑API(Transparent API)は、OpenCVの画像処理関数を自動的に最適化し、CPUやGPUの能力に応じて最適な実行環境を選択します。
OpenCVを自分でビルドした場合は、WITH_OPENCL=ON オプションを付けたうえでのビルドが必要です。例:-DWITH_OPENCL=ON
これにより、コードの変更なしに処理速度を向上させることが可能です。
// T‑APIを有効にした例
#include <iostream>
#include <opencv2/core/ocl.hpp>
#include <opencv2/opencv.hpp>
int main() {
// 画像の読み込み
cv::Mat src = cv::imread("sample.jpg");
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// T‑APIを有効化
cv::ocl::setUseOpenCL(true);
// 画像の平滑化
cv::Mat dst;
cv::GaussianBlur(src, dst, cv::Size(15, 15), 0);
cv::imshow("T-APIによる高速処理", dst);
cv::waitKey(0);
return 0;
}この例では、OpenCLやCUDAが利用可能な環境では自動的に最適なハードウェアを選択し、処理を高速化します。
マルチスレッド処理
マルチスレッド処理は、複数のCPUコアを活用して、処理を並列化する技術です。
OpenCVは、内部的にマルチスレッド化された関数を多く持ち、また自分でスレッドを管理して処理を分散させることも可能です。
// OpenCVの並列処理を利用した例
#include <opencv2/opencv.hpp>
#include <iostream>
#include <thread>
void processRegion(const cv::Mat& src, cv::Mat& dst, cv::Rect region) {
// 指定した領域に対して処理を行う(例:エッジ検出)
cv::Mat roiSrc = src(region);
cv::Mat roiDst;
cv::Canny(roiSrc, roiDst, 50, 150);
roiDst.copyTo(dst(region));
}
int main() {
cv::Mat src = cv::imread("input.jpg", cv::IMREAD_GRAYSCALE);
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat dst = cv::Mat::zeros(src.size(), src.type());
// 画像を4つの領域に分割
int midX = src.cols / 2;
int midY = src.rows / 2;
std::thread t1(processRegion, std::cref(src), std::ref(dst), cv::Rect(0, 0, midX, midY));
std::thread t2(processRegion, std::cref(src), std::ref(dst), cv::Rect(midX, 0, midX, midY));
std::thread t3(processRegion, std::cref(src), std::ref(dst), cv::Rect(0, midY, midX, midY));
std::thread t4(processRegion, std::cref(src), std::ref(dst), cv::Rect(midX, midY, midX, midY));
t1.join();
t2.join();
t3.join();
t4.join();
cv::imshow("マルチスレッド処理結果", dst);
cv::waitKey(0);
return 0;
}
この例では、画像を4つの領域に分割し、それぞれを別スレッドで処理しています。
これにより、処理時間を短縮し、CPUのマルチコア性能を最大限に活用できます。
これらのGPU活用と最適化技術を駆使することで、リアルタイム処理や大規模データの高速処理が実現し、実用的なアプリケーションの性能向上に大きく寄与します。
応用事例
画像処理やコンピュータビジョンの技術は、多くの実用的なアプリケーションに応用されています。
ここでは、OCRと文字認識、AR(拡張現実)によるオーバーレイ、セマンティックセグメンテーション(特にU-Netを用いた実装)、そしてジェスチャー認識について詳しく解説します。
OCRと文字認識
OCR(Optical Character Recognition)は、画像内の文字を認識し、テキストデータに変換する技術です。
OpenCVと深層学習を組み合わせることで、高精度な文字認識システムを構築できます。
-ltesseract -lbleptonica \
-lopencv_core -lopencv_imgcodecs -lopencv_highgui -lopencv_imgproc// Tesseract OCRを用いた文字認識の例
#include <tesseract/baseapi.h>
#include <leptonica/allheaders.h>
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 画像の読み込み
cv::Mat img = cv::imread("text_image.png");
if (img.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// OpenCVの画像をTesseractに渡すためにPixに変換
Pix *pix = pixCreate(img.cols, img.rows, 8);
// 画像の前処理や変換は省略
// Tesseractの初期化
tesseract::TessBaseAPI *api = new tesseract::TessBaseAPI();
if (api->Init(NULL, "eng")) {
std::cerr << "Tesseractの初期化に失敗しました。" << std::endl;
return -1;
}
api->SetImage(pix);
char* outText = api->GetUTF8Text();
std::cout << "認識結果:\n" << outText << std::endl;
// 後始末
delete[] outText;
api->End();
pixDestroy(&pix);
return 0;
}この例では、Tesseract OCRエンジンを用いて画像内の文字を抽出しています。
深層学習モデルと連携させることで、手書き文字や多言語対応も可能です。
AR(拡張現実)でのオーバーレイ
ARは、カメラ映像に仮想の情報やオブジェクトを重ね合わせる技術です。
OpenCVと3Dライブラリを組み合わせることで、現実世界に仮想オブジェクトを自然に配置できます。
// OpenCVとOpenGLを用いたARの基本例(概略)
#include <opencv2/opencv.hpp>
#include <GL/gl.h>
#include <GL/glu.h>
int main() {
// カメラキャプチャ
cv::VideoCapture cap(0);
if (!cap.isOpened()) return -1;
cv::Mat frame;
while (true) {
cap >> frame;
if (frame.empty()) break;
// 特徴点検出とマーカー認識(例:ARマーカー)
// 位置と姿勢推定
// 3Dモデルの描画(OpenGL)
// 例:仮想の3Dキューブを描画
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
glLoadIdentity();
// カメラの位置・姿勢に合わせて変換
// 3Dオブジェクトの描画
glBegin(GL_QUADS);
glColor3f(1, 0, 0);
glVertex3f(-0.5, -0.5, 0);
glVertex3f(0.5, -0.5, 0);
glVertex3f(0.5, 0.5, 0);
glVertex3f(-0.5, 0.5, 0);
glEnd();
// 画面に描画
// 省略
}
return 0;
}このように、カメラ映像に対して仮想オブジェクトをリアルタイムに重ね合わせることで、インタラクティブなAR体験を実現します。
ィブな操作やロボット制御、AR/VR体験において重要な役割を果たしています。
これらの応用事例は、画像処理技術の多彩な可能性を示しており、産業や研究、エンターテインメントなどさまざまな分野で革新的なソリューションを生み出しています。
トラブルシューティング
画像処理やコンピュータビジョンの開発においては、さまざまな問題に直面することがあります。
パフォーマンスの低下やメモリリーク、モデルの互換性の問題など、これらの課題を適切に解決することが、安定したシステム構築の鍵となります。
ここでは、代表的なトラブルとその対策について詳しく解説します。
パフォーマンスボトルネックの解消
処理速度が遅い場合、多くは計算負荷や不適切なアルゴリズム選択、ハードウェアの未活用に起因します。
- GPUの活用:OpenCVのCUDAやT‑APIを利用し、重い画像処理をGPUにオフロードします。特に、大規模な画像や動画処理では、GPUの並列処理能力を最大限に引き出すことが効果的です
- アルゴリズムの最適化:不要な処理や高コストな演算を見直し、必要な部分だけを高速化します。例えば、画像の解像度を適切に設定し、処理対象を絞ることも重要です
- マルチスレッド化:複数コアを活用し、処理を並列化します。OpenCVの内部関数は多くがマルチスレッド対応しているため、適切に設定すれば自動的に高速化されます
// OpenCVの並列処理設定例
#include <opencv2/opencv.hpp>
#include <opencv2/core/utility.hpp>
int main() {
cv::setNumThreads(cv::getNumberOfCPUs()); // CPUコア数に合わせてスレッド数設定
// 以降の処理は自動的に並列化される
return 0;
}- 処理のバッチ化:複数の画像やフレームを一括処理し、処理効率を向上させます
メモリリーク対策
長時間動作させるシステムや大量の画像データを扱う場合、メモリリークはシステムの安定性を著しく低下させます。
- リソースの適切な解放:
cv::Matやcv::PtrなどのOpenCVオブジェクトは、スコープを抜けると自動的に解放されるが、動的に確保したリソースは明示的に解放する必要があります - スマートポインタの利用:
cv::Ptrやstd::shared_ptrを用いて、リソースの自動管理を行います - ツールの活用:ValgrindやVisual Studioの診断ツールを使い、メモリリークを検出・修正します
// スマートポインタの例
#include <opencv2/opencv.hpp>
#include <memory>
int main() {
auto imgPtr = std::make_shared<cv::Mat>(cv::imread("image.jpg"));
// 画像処理
// 画像は自動的に解放される
return 0;
}- コードの見直し:不要なメモリ確保や解放忘れを防ぐため、コードレビューと静的解析を徹底します
モデル互換性の課題
深層学習モデルの互換性問題は、異なるフレームワークやバージョン間でのモデルの読み込み・推論において頻繁に発生します。
- モデルのエクスポートとインポート:ONNXやOpenVINOなどの中間表現を利用し、異なるフレームワーク間での互換性を確保します
- フレームワークのバージョン管理:TensorFlowやPyTorchのバージョンを固定し、環境の一貫性を保ちます
- モデルの最適化:TensorRTやOpenVINOを用いて、推論速度と互換性を向上させます
- 事前検証:新しいモデルを導入する前に、テスト環境で十分に動作確認を行います
# ONNXモデルの検証例
onnxruntime_test --model=model.onnx --input=input_data.npy- ドキュメントと仕様の確認:モデルの入出力仕様や前処理・後処理の要件を明確にし、適合性を確保します
これらのトラブルシューティングのポイントを押さえることで、システムの安定性と効率性を向上させ、開発・運用の負担を軽減できます。
まとめ
この記事では、OpenCVを用いた画像処理やコンピュータビジョンの基本技術から応用事例、そしてシステムのトラブルシューティングまで幅広く解説しました。
パフォーマンス向上やメモリ管理、モデル互換性の課題に対処する方法を理解し、実践的なシステム構築に役立てることができます。
![[C++] OpenCVでのGrabCutアルゴリズムによる画像セグメンテーションの実装](https://af-e.net/wp-content/uploads/2024/08/thumbnail-29323.png)
![[C++] OpenCVでOCRを実装する方法と活用例](https://af-e.net/wp-content/uploads/2024/08/thumbnail-29328.png)
![[C++] OpenCVでk-meansクラスタリングを実装する方法](https://af-e.net/wp-content/uploads/2024/08/thumbnail-29327.png)
![[C++] OpenCVでオプティカルフローを実装する方法](https://af-e.net/wp-content/uploads/2024/08/thumbnail-29329.png)