[C++] OpenCVでk-meansクラスタリングを実装する方法
OpenCVは、画像処理やコンピュータビジョンのための強力なライブラリで、C++での開発に広く利用されています。
k-meansクラスタリングは、データをk個のクラスタに分けるための非階層的な手法です。
OpenCVでは、cv::kmeans関数を使用してk-meansクラスタリングを実装できます。
この関数は、入力データ、クラスタ数、終了条件、初期化方法などを引数として受け取ります。
結果として、各データポイントのクラスタラベルとクラスタの中心が返されます。
これにより、画像のセグメンテーションや色の量子化など、さまざまなアプリケーションに応用可能です。
OpenCVとk-meansクラスタリングの基礎知識
k-meansクラスタリングとは
k-meansクラスタリングは、データをk個のクラスタに分割するための非階層的な手法です。
この手法は、各データポイントを最も近いクラスタの中心(セントロイド)に割り当てることで、クラスタを形成します。
以下にk-meansクラスタリングの基本的な流れを示します。
- 初期化: k個のクラスタの中心をランダムに選択します。
- 割り当て: 各データポイントを最も近いクラスタの中心に割り当てます。
- 更新: 各クラスタの中心を、そのクラスタに属するデータポイントの平均に更新します。
- 収束判定: クラスタの中心が変化しなくなるまで、割り当てと更新を繰り返します。
この手法は、データの分布を理解しやすくするために広く利用されています。
特に、画像処理やパターン認識の分野で多くの応用があります。
OpenCVでのクラスタリングの利点
OpenCVは、コンピュータビジョンや画像処理のための強力なライブラリであり、k-meansクラスタリングを簡単に実装するための関数を提供しています。
OpenCVを使用することで、以下のような利点があります。
- 効率的な実装: OpenCVはC++で最適化されており、高速な処理が可能です。
特に大規模なデータセットに対しても効率的にクラスタリングを行うことができます。
- 豊富な機能: OpenCVは、画像処理に関連する多くの機能を提供しており、k-meansクラスタリングと組み合わせて様々な応用が可能です。
- クロスプラットフォーム: OpenCVは、Windows、Linux、macOSなど、様々なプラットフォームで動作します。
これにより、開発環境に依存せずにクラスタリングを実行できます。
これらの利点により、OpenCVは画像処理やデータ分析の分野で広く利用されています。
k-meansクラスタリングを用いた画像のセグメンテーションやカラー量子化など、様々な応用が可能です。
k-meansクラスタリングの実装手順
データの準備
画像データの読み込み
OpenCVを使用して画像データを読み込むには、cv::imread関数を利用します。
この関数は、指定したパスから画像を読み込み、cv::Matオブジェクトとして返します。
以下にサンプルコードを示します。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 画像を読み込む
cv::Mat image = cv::imread("path/to/image.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
std::cout << "画像が正常に読み込まれました。" << std::endl;
return 0;
}このコードは、指定したパスの画像を読み込み、成功したかどうかを確認します。
データの前処理
k-meansクラスタリングを行う前に、画像データを適切な形式に変換する必要があります。
通常、画像の各ピクセルを特徴ベクトルとして扱います。
以下に、画像データを2次元の特徴ベクトルに変換する方法を示します。
// 画像を2次元の特徴ベクトルに変換する
cv::Mat data;
image.convertTo(data, CV_32F); // データ型をfloatに変換
data = data.reshape(1, image.rows * image.cols); // 1行に変換このコードは、画像を1次元の行列に変換し、各ピクセルを特徴ベクトルとして扱います。
k-meansクラスタリングの実装
cv::kmeans関数の使い方
OpenCVのcv::kmeans関数を使用して、k-meansクラスタリングを実行します。
この関数は、データ、クラスタ数、終了条件などを引数として受け取ります。
以下にサンプルコードを示します。
// k-meansクラスタリングを実行する
int clusterCount = 3; // クラスタ数
cv::Mat labels, centers;
cv::kmeans(data, clusterCount, labels,
cv::TermCriteria(cv::TermCriteria::EPS + cv::TermCriteria::COUNT, 10, 1.0),
3, cv::KMEANS_PP_CENTERS, centers);このコードは、指定したクラスタ数でk-meansクラスタリングを実行し、各データポイントのクラスタラベルとクラスタの中心を計算します。
パラメータの設定
cv::kmeans関数には、いくつかの重要なパラメータがあります。
- クラスタ数: データを分割するクラスタの数を指定します。
- 終了条件: クラスタリングの終了条件を指定します。
通常、反復回数と精度の両方を設定します。
- 初期化方法: クラスタの初期中心を決定する方法を指定します。
cv::KMEANS_PP_CENTERSは、一般的に良好な結果をもたらします。
結果の可視化
クラスタリング結果の表示
クラスタリングの結果を可視化するために、各ピクセルをそのクラスタの中心の色で塗りつぶします。
以下にサンプルコードを示します。
// クラスタリング結果を表示する
cv::Mat clusteredImage(image.size(), image.type());
for (int i = 0; i < data.rows; i++) {
int clusterIdx = labels.at<int>(i);
clusteredImage.at<cv::Vec3b>(i / image.cols, i % image.cols) = centers.at<cv::Vec3f>(clusterIdx);
}
clusteredImage.convertTo(clusteredImage, CV_8U);
cv::imshow("Clustered Image", clusteredImage);
cv::waitKey(0);このコードは、クラスタリング結果を画像として表示します。
画像へのクラスタリング結果の適用
クラスタリング結果を画像に適用することで、画像のセグメンテーションやカラー量子化を行うことができます。
これにより、画像の特徴を強調したり、データ量を削減したりすることが可能です。
サンプルプログラム
以下に、OpenCVを使用してk-meansクラスタリングを実装する完全なサンプルプログラムを示します。
このプログラムは、指定した画像を読み込み、k-meansクラスタリングを適用してクラスタリング結果を表示します。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 画像を読み込む
cv::Mat image = cv::imread("path/to/image.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// 画像を2次元の特徴ベクトルに変換する
cv::Mat data;
image.convertTo(data, CV_32F); // データ型をfloatに変換
data = data.reshape(1, image.rows * image.cols); // 1行に変換
// k-meansクラスタリングを実行する
int clusterCount = 3; // クラスタ数
cv::Mat labels, centers;
cv::kmeans(data, clusterCount, labels,
cv::TermCriteria(cv::TermCriteria::EPS + cv::TermCriteria::COUNT, 10, 1.0),
3, cv::KMEANS_PP_CENTERS, centers);
// クラスタリング結果を表示する
cv::Mat clusteredImage(image.size(), image.type());
for (int i = 0; i < data.rows; i++) {
int clusterIdx = labels.at<int>(i);
clusteredImage.at<cv::Vec3b>(i / image.cols, i % image.cols) = centers.at<cv::Vec3f>(clusterIdx);
}
clusteredImage.convertTo(clusteredImage, CV_8U);
cv::imshow("Clustered Image", clusteredImage);
cv::waitKey(0);
return 0;
}このプログラムは、以下の手順で動作します。
- 指定したパスから画像を読み込みます。
- 画像を2次元の特徴ベクトルに変換します。
cv::kmeans関数を使用して、k-meansクラスタリングを実行します。- 各ピクセルをそのクラスタの中心の色で塗りつぶし、クラスタリング結果を画像として表示します。
実行例
このプログラムを実行すると、元の画像が3つのクラスタに分割され、各クラスタの中心の色で塗りつぶされた画像が表示されます。
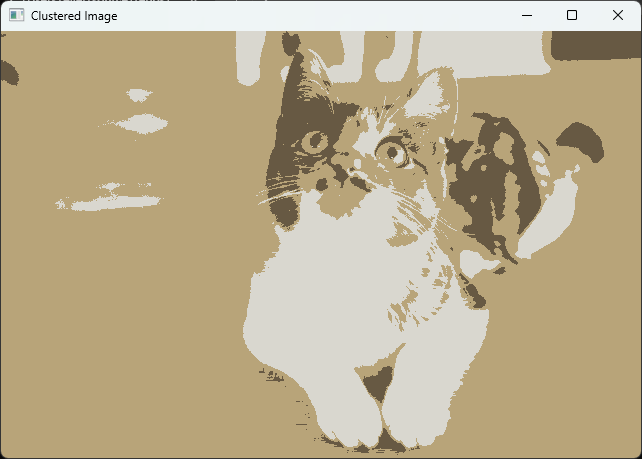
これにより、画像のセグメンテーションやカラー量子化の効果を視覚的に確認することができます。
応用例
画像のセグメンテーション
k-meansクラスタリングは、画像のセグメンテーションに広く利用されています。
画像を複数の領域に分割し、各領域を異なるクラスタとして識別することで、物体の輪郭や領域を明確にすることができます。
これにより、画像内の特定のオブジェクトを抽出したり、背景と前景を分離したりすることが可能です。
カラー量子化
カラー量子化は、画像の色数を減らす技術で、k-meansクラスタリングを用いることで実現できます。
画像内のピクセルを少数の代表的な色に置き換えることで、データ量を削減しつつ、視覚的な品質を保つことができます。
これにより、画像の圧縮やスタイル変換に役立ちます。
異常検知
k-meansクラスタリングは、異常検知にも応用されます。
通常のデータポイントをクラスタとしてグループ化し、クラスタに属さないデータポイントを異常として検出します。
これにより、画像内の異常なパターンやノイズを特定することができます。
顔認識の前処理
顔認識システムでは、k-meansクラスタリングを前処理として使用することがあります。
顔画像をクラスタリングすることで、肌の色や特徴を強調し、認識精度を向上させることができます。
また、背景の影響を軽減するためにも利用されます。
動画解析への応用
動画解析では、各フレームをk-meansクラスタリングで処理することで、動的なシーンのセグメンテーションやオブジェクトの追跡を行うことができます。
これにより、動きのあるオブジェクトをリアルタイムで検出し、追跡することが可能です。
特に、監視カメラや自動運転車のシステムでの応用が期待されています。
まとめ
この記事では、C++とOpenCVを用いたk-meansクラスタリングの実装方法について詳しく解説しました。
k-meansクラスタリングの基礎から実装手順、応用例までを通じて、画像処理におけるクラスタリングの有用性を理解することができたでしょう。
これを機に、実際にOpenCVを使って様々な画像データに対してk-meansクラスタリングを試し、さらなる応用を探求してみてください。