[Python] エクセル操作でできることまとめ
Pythonでは、エクセルファイルを操作するためのライブラリが豊富に用意されています。代表的なものに、openpyxlやpandasがあります。
openpyxlは、エクセルファイルの読み書きやセルのスタイル設定、数式の操作などが可能です。
pandasは、データフレームを用いてエクセルデータを効率的に処理することができます。
これらのライブラリを活用することで、データの自動化や分析、レポート作成など、さまざまなエクセル操作をプログラムで実現できます。
Pythonでエクセル操作を始める前に
Pythonを使ってエクセルファイルを操作するためには、いくつかの準備が必要です。
ここでは、必要なライブラリのインストール方法やエクセルファイルの基本構造、Pythonでエクセルを操作するメリットについて解説します。
必要なライブラリのインストール
Pythonでエクセルファイルを操作するためには、主に以下のライブラリを使用します。
| ライブラリ名 | 説明 |
|---|---|
| openpyxl | Excel 2010以降の.xlsxファイルを読み書きするためのライブラリ |
| pandas | データ解析を行うためのライブラリで、エクセルファイルの読み書きも可能 |
| xlrd | Excelファイルを読み込むためのライブラリ(.xls形式) |
| xlwt | Excelファイルを書き出すためのライブラリ(.xls形式) |
これらのライブラリは、Pythonのパッケージ管理システムであるpipを使ってインストールできます。
以下は、openpyxlとpandasをインストールするコマンドの例です。
pip install openpyxl pandasエクセルファイルの基本構造
エクセルファイルは、以下のような基本構造を持っています。
- ワークブック(Workbook): エクセルファイル全体を指します。
- ワークシート(Worksheet): ワークブック内に含まれるシートのことです。
複数のシートを持つことができます。
- セル(Cell): ワークシート内のデータを格納する最小単位です。
行と列の交差点に位置します。
Pythonを使ってエクセルファイルを操作する際には、これらの構造を理解しておくことが重要です。
Pythonでエクセルを操作するメリット
Pythonでエクセルを操作することには、以下のようなメリットがあります。
- 自動化: 繰り返し行う作業を自動化することで、作業効率を大幅に向上させることができます。
- 大量データの処理: 大量のデータを迅速に処理し、分析することが可能です。
- 柔軟性: データの加工や分析を柔軟に行うことができ、カスタマイズも容易です。
これらのメリットを活かすことで、日常の業務やデータ分析の効率を高めることができます。
openpyxlを使ったエクセル操作
openpyxlは、Pythonでエクセルファイルを操作するための強力なライブラリです。
ここでは、openpyxlを使った基本的なエクセル操作について解説します。
openpyxlの基本的な使い方
openpyxlを使用するためには、まずライブラリをインポートする必要があります。
import openpyxlワークブックの作成と保存
新しいワークブックを作成し、保存する方法を紹介します。
# 新しいワークブックを作成
workbook = openpyxl.Workbook()
# ワークブックを保存
workbook.save('example.xlsx')このコードを実行すると、カレントディレクトリにexample.xlsxという名前のエクセルファイルが作成されます。
シートの追加と削除
ワークブックにシートを追加したり削除したりする方法です。
# 新しいシートを追加
sheet = workbook.create_sheet(title='NewSheet')
# シートを削除
workbook.remove(workbook['NewSheet'])シートの追加はcreate_sheetメソッドで行い、削除はremoveメソッドを使用します。
セルへのデータの書き込みと読み込み
openpyxlを使ってセルにデータを書き込んだり、読み込んだりする方法を解説します。
セルの指定方法
セルを指定してデータを操作する方法です。
# アクティブなシートを取得
sheet = workbook.active
# セルにデータを書き込む
sheet['A1'] = 'こんにちは'
# セルからデータを読み込む
value = sheet['A1'].value
print(value) # 出力: こんにちはセルは、行と列を指定してアクセスします。
データ型の扱い
openpyxlでは、セルに格納されるデータの型を自動的に判断します。
# 数値データの書き込み
sheet['B1'] = 123
# 日付データの書き込み
import datetime
sheet['C1'] = datetime.datetime.now()数値や日付など、さまざまなデータ型を扱うことができます。
スタイルとフォーマットの適用
openpyxlを使ってセルのスタイルやフォーマットを設定する方法を紹介します。
フォントと色の設定
セルのフォントや背景色を設定する方法です。
from openpyxl.styles import Font, PatternFill
# フォントの設定
sheet['A1'].font = Font(name='Arial', size=14, bold=True)
# 背景色の設定
sheet['A1'].fill = PatternFill(start_color='FFFF00', end_color='FFFF00', fill_type='solid')フォントや色を設定することで、見やすいエクセルシートを作成できます。
セルの結合と罫線の追加
セルを結合したり、罫線を追加する方法です。
from openpyxl.styles import Border, Side
# セルの結合
sheet.merge_cells('A1:B1')
# 罫線の追加
thin_border = Border(left=Side(style='thin'), right=Side(style='thin'), top=Side(style='thin'), bottom=Side(style='thin'))
sheet['A1'].border = thin_borderセルの結合や罫線の追加により、シートのレイアウトを整えることができます。
pandasを使ったエクセル操作
pandasは、データ解析に特化したPythonライブラリで、エクセルファイルの読み書きも簡単に行うことができます。
ここでは、pandasを使ったエクセル操作について解説します。
pandasでエクセルファイルを読み込む
pandasを使ってエクセルファイルを読み込む方法を紹介します。
read_excel関数の使い方
read_excel関数を使うと、エクセルファイルをデータフレームとして読み込むことができます。
import pandas as pd
# エクセルファイルを読み込む
df = pd.read_excel('example.xlsx', sheet_name='Sheet1')
# データフレームの内容を表示
print(df.head())このコードを実行すると、指定したシートのデータがデータフレームとして読み込まれ、最初の数行が表示されます。
複数シートの読み込み
複数のシートを同時に読み込むことも可能です。
# 複数シートを読み込む
sheets = pd.read_excel('example.xlsx', sheet_name=None)
# 各シートのデータフレームを表示
for sheet_name, data in sheets.items():
print(f"Sheet: {sheet_name}")
print(data.head())sheet_name=Noneを指定することで、すべてのシートを辞書形式で読み込むことができます。
データフレームの操作とエクセルへの書き出し
pandasを使ってデータフレームを操作し、エクセルファイルに書き出す方法を解説します。
データのフィルタリングと集計
データフレームをフィルタリングしたり、集計したりする方法です。
# 条件に基づいてデータをフィルタリング
filtered_df = df[df['Column1'] > 10]
# データの集計
grouped_df = df.groupby('Category').sum()
print(filtered_df.head())
print(grouped_df.head())このように、条件に基づいてデータを抽出したり、特定の列で集計を行うことができます。
to_excel関数の使い方
to_excel関数を使って、データフレームをエクセルファイルに書き出します。
# データフレームをエクセルファイルに書き出す
filtered_df.to_excel('filtered_data.xlsx', index=False)このコードを実行すると、フィルタリングされたデータがfiltered_data.xlsxという名前のエクセルファイルに保存されます。
pandasとopenpyxlの連携
pandasとopenpyxlを組み合わせることで、より高度なエクセル操作が可能になります。
# pandasでデータフレームを作成
df = pd.DataFrame({
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35]
})
# openpyxlを使ってスタイルを適用
from openpyxl import load_workbook
from openpyxl.styles import Font
# データフレームをエクセルに書き出し
df.to_excel('styled_data.xlsx', index=False)
# openpyxlでエクセルファイルを開く
workbook = load_workbook('styled_data.xlsx')
sheet = workbook.active
# フォントスタイルを設定
for cell in sheet['A'] + sheet[1]:
cell.font = Font(bold=True)
# 保存
workbook.save('styled_data.xlsx')この例では、pandasでデータフレームをエクセルに書き出し、openpyxlを使ってフォントスタイルを適用しています。
これにより、データの操作とスタイルの適用を効率的に行うことができます。
xlrdとxlwtを使ったエクセル操作
xlrdとxlwtは、Pythonでエクセルファイルを操作するための古典的なライブラリです。
特に、.xls形式のファイルを扱う際に使用されます。
ここでは、xlrdを使ったエクセルファイルの読み込みと、xlwtを使ったエクセルファイルの書き出しについて解説します。
xlrdでエクセルファイルを読み込む
xlrdを使ってエクセルファイルを読み込む方法を紹介します。
基本的な読み込み方法
xlrdを使ってエクセルファイルを読み込む基本的な方法です。
import xlrd
# エクセルファイルを開く
workbook = xlrd.open_workbook('example.xls')
# シートを取得
sheet = workbook.sheet_by_index(0)
# セルの値を取得
value = sheet.cell_value(0, 0)
print(value)このコードを実行すると、指定したシートの最初のセルの値が取得されます。
セルのデータ型の取得
セルのデータ型を取得する方法です。
# セルのデータ型を取得
cell_type = sheet.cell_type(0, 0)
print(cell_type)xlrdでは、セルのデータ型を数値で返します。
例えば、0は空、1は文字列、2は数値を表します。
xlwtでエクセルファイルを書き出す
xlwtを使ってエクセルファイルを書き出す方法を解説します。
新しいワークブックの作成
新しいワークブックを作成し、データを書き込む方法です。
import xlwt
# 新しいワークブックを作成
workbook = xlwt.Workbook()
# 新しいシートを追加
sheet = workbook.add_sheet('Sheet1')
# セルにデータを書き込む
sheet.write(0, 0, 'こんにちは')
# ワークブックを保存
workbook.save('output.xls')このコードを実行すると、output.xlsという名前のエクセルファイルが作成され、データが書き込まれます。
セルのスタイル設定
セルにスタイルを設定する方法です。
# スタイルを作成
style = xlwt.XFStyle()
font = xlwt.Font()
font.bold = True
style.font = font
# スタイルを適用してセルにデータを書き込む
sheet.write(0, 0, 'こんにちは', style)
# ワークブックを保存
workbook.save('styled_output.xls')この例では、フォントを太字に設定し、スタイルを適用してデータを書き込んでいます。
スタイルを設定することで、見やすいエクセルシートを作成することができます。
エクセル操作の応用例
Pythonを使ったエクセル操作は、基本的なデータの読み書きだけでなく、さまざまな応用が可能です。
ここでは、大量データの自動処理、グラフの作成と編集、マクロの自動化とPythonの連携について解説します。
大量データの自動処理
Pythonを使うことで、大量のデータを効率的に処理することができます。
例えば、以下のような自動処理が可能です。
- データのクレンジング: 不要なデータの削除や欠損値の補完を自動化します。
- データの変換: データ形式の変換や単位の変換を一括で行います。
- レポートの生成: 定期的なレポートを自動で生成し、エクセルファイルとして出力します。
これらの処理を自動化することで、手作業によるミスを減らし、作業効率を大幅に向上させることができます。
グラフの作成と編集
Pythonを使ってエクセルファイル内にグラフを作成し、編集することも可能です。
openpyxlを使ったグラフの作成例を紹介します。
import openpyxl
from openpyxl.chart import BarChart, Reference
# ワークブックを作成
workbook = openpyxl.Workbook()
sheet = workbook.active
# データを入力
data = [
['Year', 'Sales'],
[2018, 100],
[2019, 150],
[2020, 200]
]
for row in data:
sheet.append(row)
# グラフを作成
chart = BarChart()
values = Reference(sheet, min_col=2, min_row=1, max_col=2, max_row=4)
chart.add_data(values, titles_from_data=True)
sheet.add_chart(chart, "E5")
# ワークブックを保存
workbook.save('chart_example.xlsx')このコードを実行すると、エクセルファイルに棒グラフが追加されます。
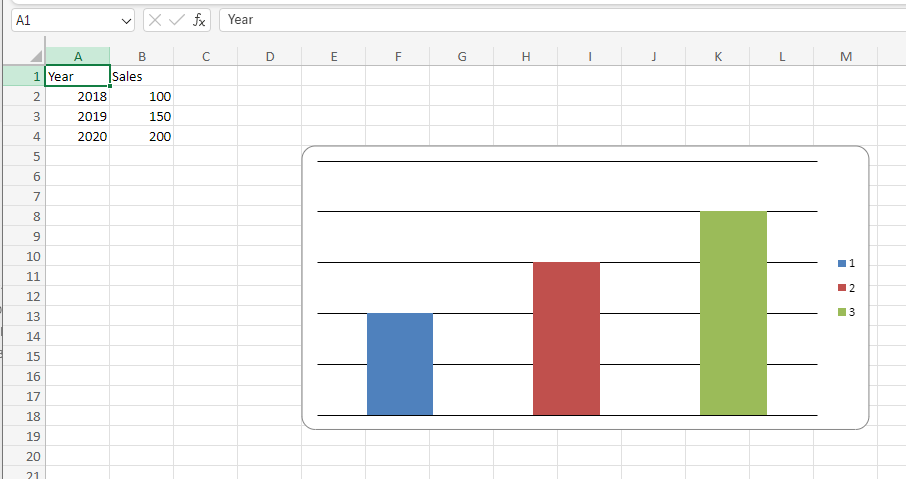
グラフを使うことで、データの視覚化が容易になり、分析がしやすくなります。
マクロの自動化とPythonの連携
エクセルのマクロをPythonで自動化することで、より高度な操作が可能になります。
Pythonのpywin32ライブラリを使って、エクセルのVBAマクロを実行することができます。
import win32com.client
# Excelアプリケーションを起動
excel = win32com.client.Dispatch("Excel.Application")
excel.Visible = True
# エクセルファイルを開く
workbook = excel.Workbooks.Open(r'C:\path\to\your\file.xlsm')
# マクロを実行
excel.Application.Run("YourMacroName")
# エクセルを閉じる
workbook.Close(SaveChanges=True)
excel.Quit()このコードを実行すると、指定したエクセルファイルのマクロが実行されます。
PythonとVBAを組み合わせることで、エクセルの機能を最大限に活用し、業務の効率化を図ることができます。
まとめ
Pythonを使ったエクセル操作は、データの自動化や効率化に非常に有用です。
この記事では、openpyxlやpandas、xlrd/xlwtを使ったエクセル操作の基本から応用までを解説しました。
これらの知識を活用して、日常の業務やデータ分析をより効率的に行いましょう。

![[Python] “import openpyxl”がエラーになる原因と対処法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-41164.png)
![[Python] import docxがエラーになる原因と対処法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-41163.png)
![[Python] エクセルファイルを読み込めない原因と対処法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-41162.png)
![[Python] Pandasでエクセルファイルを読み込む方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-41161.png)
![[Python] エクセルファイルを読み込んでデータを処理する方法【Pandas/Numpy/openpyxl】](https://af-e.net/wp-content/uploads/2024/09/thumbnail-41160.png)
![[Python] openpyxlでデータをエクセルファイルに出力する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-41159.png)
![[Python] openpyxlで列を指定してセルを取得する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-41158.png)
![[Python] openpyxlでエクセルの日付セルから日時を取得する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-41157.png)
![[Python] openpyxlでエクセルのセルの色を取得・変更する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-41156.png)
![[Python] エクセルで最終行を取得する方法【openpyxl】](https://af-e.net/wp-content/uploads/2024/09/thumbnail-41155.png)
![[Python] Excelのシートの行数・列数を取得する方法](https://af-e.net/wp-content/uploads/2024/08/thumbnail-9935.png)