[Python] seleniumでgoogle検索する方法と注意点
Seleniumを使用してPythonでGoogle検索を行うには、まずSelenium WebDriverをインストールし、ブラウザを操作します。
具体的には、webdriver.Chrome()でChromeブラウザを起動し、get()メソッドでGoogleのURLを開きます。
検索ボックスをfind_element()で取得し、send_keys()で検索ワードを入力し、submit()で検索を実行します。
注意点として、Googleは自動化ツールによるアクセスを制限しているため、頻繁なリクエストはブロックされる可能性があります。
また、Seleniumのバージョンやブラウザのバージョンが一致していることを確認する必要があります。
Google検索を自動化する手順
Google検索ページを開く
まず、Seleniumを使用してGoogleの検索ページを開きます。
以下のコードでは、Chromeブラウザを使用してGoogleのホームページを表示します。
from selenium import webdriver
# Chromeブラウザを起動
driver = webdriver.Chrome()
# Googleの検索ページを開く
driver.get("https://www.google.com")このコードを実行すると、Chromeブラウザが起動し、Googleの検索ページが表示されます。
検索ボックスの要素を取得する
次に、検索ボックスの要素を取得します。
Seleniumでは、要素を取得するためにfind_elementメソッドを使用します。
以下のコードでは、検索ボックスを取得します。
# 検索ボックスの要素を取得
search_box = driver.find_element("name", "q")このコードにより、検索ボックスの要素がsearch_box変数に格納されます。
検索ワードを入力する
取得した検索ボックスに検索ワードを入力します。
以下のコードでは、 Python Selenium と入力します。
# 検索ワードを入力
search_box.send_keys("Python Selenium")このコードを実行すると、検索ボックスに Python Selenium という文字列が入力されます。
検索を実行する
検索ボックスに入力した後、検索を実行します。
Enterキーをシミュレートすることで検索を行います。
以下のコードを使用します。
# 検索を実行
search_box.submit()このコードを実行すると、検索が実行され、検索結果ページが表示されます。
検索結果を取得する
最後に、検索結果を取得します。
検索結果の要素を取得し、表示するためのコードは以下の通りです。
# 検索結果の要素を取得
results = driver.find_elements("css selector", "h3")
# 検索結果を表示
for result in results:
print(result.text)このコードを実行すると、検索結果のタイトルがコンソールに表示されます。
h3タグを持つ要素を取得することで、検索結果のタイトルを取得しています。
実際のコード例
必要なライブラリのインポート
Seleniumを使用するためには、まず必要なライブラリをインポートします。
以下のコードでは、webdriverとByをインポートしています。
from selenium import webdriver
from selenium.webdriver.common.by import Byこれにより、Seleniumの機能を利用する準備が整います。
WebDriverの起動とGoogleページの表示
次に、WebDriverを起動し、Googleの検索ページを表示します。
以下のコードを使用します。
# Chromeブラウザを起動
driver = webdriver.Chrome()
# Googleの検索ページを開く
driver.get("https://www.google.com")このコードを実行すると、Chromeブラウザが起動し、Googleのホームページが表示されます。
検索ボックスへの入力と検索実行
検索ボックスに検索ワードを入力し、検索を実行します。
以下のコードでは、 Python Selenium と入力し、検索を行います。
# 検索ボックスの要素を取得
search_box = driver.find_element(By.NAME, "q")
# 検索ワードを入力
search_box.send_keys("Python Selenium")
# 検索を実行
search_box.submit()このコードを実行すると、検索ボックスに Python Selenium と入力され、検索が実行されます。
検索結果の取得と表示
検索結果を取得し、表示するためのコードは以下の通りです。
検索結果のタイトルを取得し、コンソールに表示します。
# 検索結果の要素を取得
results = driver.find_elements(By.CSS_SELECTOR, "h3")
# 検索結果を表示
for result in results:
print(result.text)このコードを実行すると、検索結果のタイトルがコンソールに表示されます。
h3タグを持つ要素を取得することで、検索結果のタイトルを取得しています。
コード全体のサンプル
以下に、これまでのコードをまとめた全体のサンプルを示します。
from selenium import webdriver
from selenium.webdriver.common.by import By
# Chromeブラウザを起動
driver = webdriver.Chrome()
# Googleの検索ページを開く
driver.get("https://www.google.com")
# 検索ボックスの要素を取得
search_box = driver.find_element(By.NAME, "q")
# 検索ワードを入力
search_box.send_keys("Python Selenium")
# 検索を実行
search_box.submit()
# 検索結果の要素を取得
results = driver.find_elements(By.CSS_SELECTOR, "h3")
# 検索結果を表示
for result in results:
print(result.text)
# 待機
input("Press Enter to close the browser...")
# ブラウザを閉じる
driver.quit()このコードを実行すると、Googleで Python Selenium を検索し、検索結果のタイトルが表示されます。
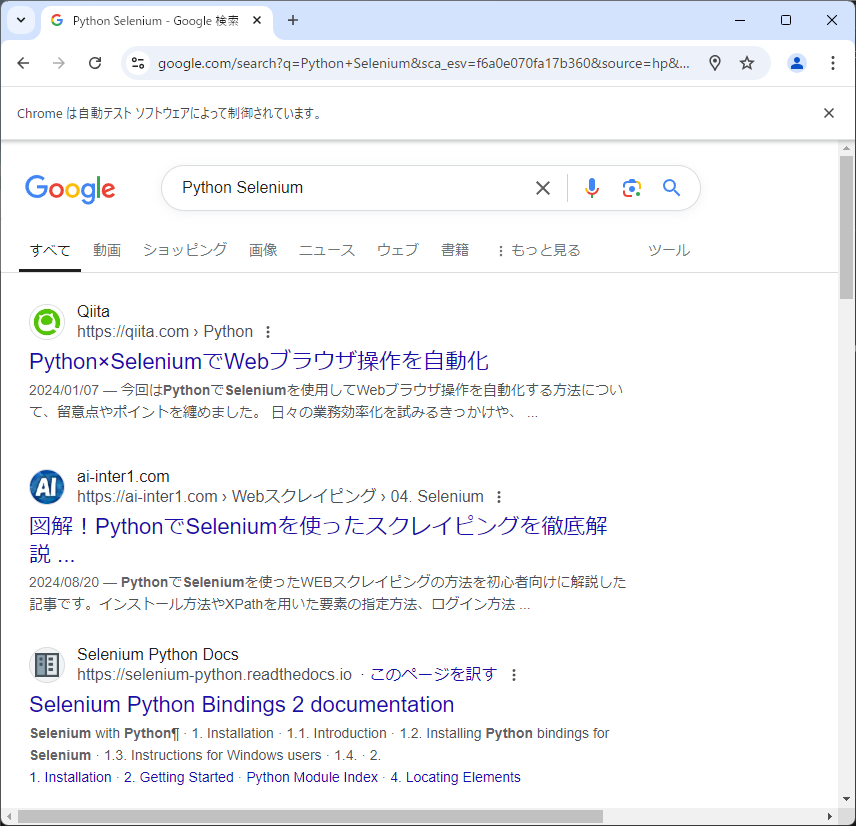
最後にdriver.quit()を使用してブラウザを閉じることを忘れないようにしましょう。
Google検索自動化の注意点
Googleの自動化ツール検出とブロック
Googleは、自動化ツールを使用して検索を行う行為を検出するための高度なアルゴリズムを持っています。
これにより、異常なトラフィックや自動化されたリクエストが検出されると、アカウントが一時的に制限されたり、IPアドレスがブロックされたりする可能性があります。
自動化を行う際は、リクエストの間隔を適切に設定し、自然なユーザー行動を模倣することが重要です。
リクエスト頻度の制限
Googleは、短時間に大量のリクエストを送信することを制限しています。
過剰なリクエストは、Googleのサーバーに負担をかけるため、アカウントの一時停止やIPアドレスのブロックにつながる可能性があります。
自動化スクリプトを実行する際は、リクエストの間隔を適切に設定し、一定の時間を置いてリクエストを送信することが推奨されます。
例えば、数秒から数十秒の間隔を設けると良いでしょう。
IPアドレスのブロックリスク
自動化ツールを使用してGoogleにアクセスする際、特定のIPアドレスがブロックされるリスクがあります。
特に、同一のIPアドレスから大量のリクエストが送信されると、GoogleはそのIPアドレスを悪意のあるものと見なすことがあります。
このため、プロキシサーバーを使用してIPアドレスを変更することや、VPNを利用することが考えられますが、これもGoogleの利用規約に反する可能性があるため注意が必要です。
CAPTCHAの発生と対策
自動化ツールを使用して検索を行うと、GoogleはCAPTCHAを表示することがあります。
これは、ユーザーが人間であることを確認するための仕組みです。
CAPTCHAが表示されると、自動化スクリプトは正常に動作しなくなります。
CAPTCHAを回避するためには、リクエストの頻度を下げたり、ユーザーエージェントを変更したりすることが有効です。
また、手動でCAPTCHAを解決する必要がある場合もあります。
Googleの利用規約に関する注意
Googleのサービスを自動化する際は、Googleの利用規約を遵守することが重要です。
自動化ツールを使用して検索を行うことは、利用規約に違反する可能性があります。
特に、商業目的での利用や、大量のデータを収集する行為は厳しく制限されています。
自動化を行う前に、必ず最新の利用規約を確認し、遵守するようにしましょう。
応用例
検索結果のスクレイピング
検索結果をスクレイピングすることで、特定の情報を自動的に収集することができます。
例えば、検索結果のタイトルやURL、スニペットを取得することが可能です。
以下のコードは、検索結果のタイトルとURLを取得する例です。
# 検索結果の要素を取得
results = driver.find_elements(By.CSS_SELECTOR, "h3")
# 検索結果のタイトルとURLを表示
for result in results:
title = result.text
url = result.find_element(By.XPATH, "..").get_attribute("href")
print(f"タイトル: {title}, URL: {url}")このコードを実行すると、検索結果のタイトルとそのリンクが表示されます。
検索結果のページ遷移
検索結果から特定のリンクをクリックして、詳細ページに遷移することもできます。
以下のコードは、最初の検索結果をクリックする例です。
# 最初の検索結果をクリック
first_result = results[0]
first_result.click()このコードを実行すると、最初の検索結果のリンクが開かれ、詳細ページに遷移します。
検索結果のフィルタリング
特定の条件に基づいて検索結果をフィルタリングすることも可能です。
例えば、特定のキーワードを含むタイトルのみを表示する場合、以下のように記述します。
# 特定のキーワードを含む検索結果をフィルタリング
keyword = "Python"
filtered_results = [result for result in results if keyword in result.text]
# フィルタリングされた結果を表示
for result in filtered_results:
print(result.text)このコードを実行すると、タイトルに Python を含む検索結果のみが表示されます。
検索結果の保存と分析
取得した検索結果をCSVファイルに保存し、後で分析することもできます。
以下のコードは、検索結果をCSVファイルに保存する例です。
import csv
# 検索結果をCSVファイルに保存
with open('search_results.csv', mode='w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(["タイトル", "URL"])
for result in results:
title = result.text
url = result.find_element(By.XPATH, "..").get_attribute("href")
writer.writerow([title, url])このコードを実行すると、検索結果がsearch_results.csvというファイルに保存されます。
他の検索エンジンでの応用
Seleniumを使用して、他の検索エンジン(例:BingやYahoo)でも同様の自動化が可能です。
検索エンジンのURLや要素の取得方法を変更するだけで、同じ手法を適用できます。
例えば、Bingでの検索を行う場合は、以下のようにURLを変更します。
# Bingの検索ページを開く
driver.get("https://www.bing.com")
# 検索ボックスの要素を取得
search_box = driver.find_element(By.NAME, "q")
# 検索ワードを入力
search_box.send_keys("Python Selenium")
# 検索を実行
search_box.submit()このように、他の検索エンジンでも同様の手法を用いて自動化を行うことができます。
まとめ
この記事では、PythonのSeleniumを使用してGoogle検索を自動化する方法について詳しく解説しました。
具体的には、検索ページの表示から検索結果の取得までの一連の流れを示し、実際のコード例を通じてその手法を具体化しました。
自動化を行う際の注意点や応用例についても触れ、実践的な知識を提供しました。
これを機に、Seleniumを活用して自動化のスキルを磨き、さまざまなプロジェクトに応用してみてはいかがでしょうか。
![[Python] Seleniumの使い方をわかりやすく解説(初心者向け)](https://af-e.net/wp-content/uploads/2024/10/thumbnail-45919.png)
![[Python] seleniumでaタグをクリックしてhref要素(URL)を取得する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-42529.png)
![[Python] seleniumで一つ・全てのaタグのテキストを取得する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-42530.png)
![[Python] seleniumで使うChrome Driverをインストールする方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-42531.png)
![[Python] seleniumで使うEdge Driverのインストール方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-42532.png)
![[Python] seleniumでiframe内の要素を取得する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-42534.png)
![[Python] seleniumでiframeの中身を取得できない原因と対処法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-42535.png)
![[Python] seleniumでJavaScriptを実行して自動ログインを実装する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-42540.png)
![[Python] seleniumでJavaScriptのポップアップをクリックして自動で閉じる方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-42541.png)
![[Python] seleniumでiframe操作後、もとのフレームに戻る方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-42539.png)
![[Python] seleniumからJavaScriptを実行する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-42542.png)
![[Python] seleniumでiframeが読み込まれるまで待機する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-42537.png)