[Python] PDFを読み込んでウィンドウに表示する方法
PythonでPDFを読み込んでウィンドウに表示するには、いくつかのライブラリを組み合わせて使用します。
まず、PyMuPDFfitzやpdfplumberを使ってPDFを読み込み、ページごとに画像として取得します。
次に、TkinterやPyQtなどのGUIライブラリを使ってウィンドウに表示します。
例えば、PyMuPDFでPDFを画像に変換し、TkinterのCanvasウィジェットに表示する方法が一般的です。
PDFをPythonで扱うための基本ライブラリ
PythonでPDFを扱うためには、いくつかのライブラリが存在します。
ここでは、代表的なライブラリであるPyMuPDF、pdfplumber、PyPDF2、そしてGUIライブラリであるTkinterとPyQtについて解説します。
これらのライブラリを使うことで、PDFの読み込みや表示が容易になります。
PyMuPDF(fitz)の概要とインストール方法
PyMuPDFは、PDFや画像ファイルを扱うための強力なライブラリです。
特に、PDFのページを画像として取得したり、テキストを抽出したりする機能が充実しています。
インストール方法
以下のコマンドを使用して、PyMuPDFをインストールできます。
pip install PyMuPDFpdfplumberの概要とインストール方法
pdfplumberは、PDFからテキストや表を抽出するためのライブラリです。
特に、複雑なレイアウトのPDFからも正確にデータを取得できる点が特徴です。
インストール方法
以下のコマンドを使用して、pdfplumberをインストールできます。
pip install pdfplumberPyPDF2の概要とインストール方法
PyPDF2は、PDFファイルの操作を行うためのライブラリです。
ページの結合や分割、メタデータの取得など、PDFファイルの編集に便利な機能が揃っています。
インストール方法
以下のコマンドを使用して、PyPDF2をインストールできます。
pip install PyPDF2GUIライブラリ(Tkinter, PyQt)の概要とインストール方法
PDFをウィンドウに表示するためには、GUIライブラリが必要です。
ここでは、Pythonに標準で搭載されているTkinterと、より高度なGUIアプリケーションを作成できるPyQtについて説明します。
| ライブラリ名 | 概要 | インストール方法 |
|---|---|---|
| Tkinter | Python標準のGUIライブラリ。簡単なウィンドウアプリケーションを作成可能。 | 標準搭載のため、追加インストール不要。 |
| PyQt | 高度なGUIアプリケーションを作成できるライブラリ。多機能でカスタマイズ性が高い。 | pip install PyQt5 |
これらのライブラリを使うことで、PDFを読み込んでウィンドウに表示するアプリケーションを簡単に作成することができます。
次のセクションでは、PyMuPDFを使ってPDFを読み込む方法について詳しく解説します。
PyMuPDFを使ってPDFを読み込む
PyMuPDFを使用すると、PDFファイルを簡単に読み込むことができます。
ここでは、PDFを開く基本的なコードから、ページを画像として取得する方法、そして画像データの保存と表示の準備について解説します。
PyMuPDFでPDFを開く基本的なコード
まずは、PyMuPDFを使ってPDFファイルを開く基本的なコードを見てみましょう。
以下のコードでは、指定したPDFファイルを開き、ページ数を表示します。
import fitz # PyMuPDFをインポート
# PDFファイルを開く
pdf_file = fitz.open("sample.pdf")
# ページ数を表示
print(f"ページ数: {pdf_file.page_count}")
# PDFファイルを閉じる
pdf_file.close()ページ数: 5このコードでは、fitz.open()を使ってPDFファイルを開き、page_count属性でページ数を取得しています。
PDFファイルを使用した後は、必ずclose()メソッドでファイルを閉じることを忘れないようにしましょう。
PDFページを画像として取得する方法
次に、PDFの特定のページを画像として取得する方法を見てみましょう。
以下のコードでは、1ページ目を画像として取得し、表示します。
import fitz # PyMuPDFをインポート
# PDFファイルを開く
pdf_file = fitz.open("sample.pdf")
# 1ページ目を取得
page = pdf_file[0]
# ページを画像として取得
pix = page.get_pixmap()
# 画像を保存
pix.save("page1.png")
# PDFファイルを閉じる
pdf_file.close()ページ1の画像が "page1.png" として保存されました。このコードでは、get_pixmap()メソッドを使用してページを画像として取得し、save()メソッドで画像ファイルとして保存しています。
画像データの保存と表示の準備
画像データを保存した後、次はその画像をウィンドウに表示する準備をします。
ここでは、Tkinterを使って画像を表示する方法を示します。
まず、TkinterとPIL(Pillow)をインストールしておく必要があります。
Pillowは画像処理ライブラリで、Tkinterと組み合わせて画像を表示するのに便利です。
Pillowのインストール方法
pip install Pillow画像をTkinterで表示するコード
以下のコードでは、先ほど保存した画像をTkinterを使って表示します。
import tkinter as tk
from PIL import Image, ImageTk
# Tkinterウィンドウを作成
root = tk.Tk()
root.title("PDFページの表示")
# 画像を読み込む
image = Image.open("page1.png")
photo = ImageTk.PhotoImage(image)
# 画像を表示するラベルを作成
label = tk.Label(root, image=photo)
label.pack()
# ウィンドウを表示
root.mainloop()このコードを実行すると、”page1.png”の画像がウィンドウに表示されます。
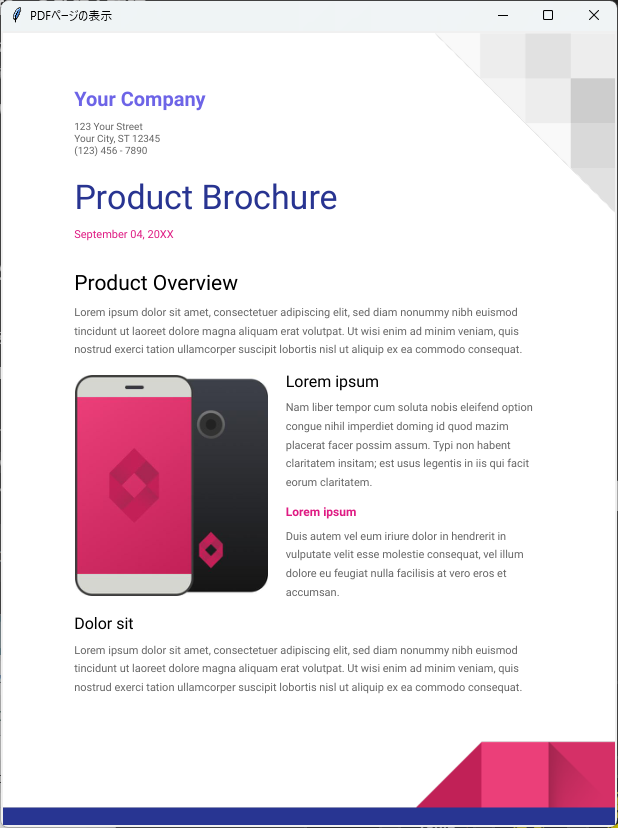
これで、PDFのページを画像として取得し、表示する準備が整いました。
次のセクションでは、PyQtを使ってPDFをウィンドウに表示する方法について解説します。
Tkinterを使ってPDFをウィンドウに表示する
Tkinterを使用すると、Pythonで簡単にGUIアプリケーションを作成できます。
ここでは、Tkinterを使ってPDFをウィンドウに表示する方法を解説します。
具体的には、基本的なウィンドウの作成から、Canvasウィジェットを使った画像表示、PDFページの描画、そしてページ送り機能の実装について説明します。
Tkinterの基本的なウィンドウ作成方法
まずは、Tkinterを使って基本的なウィンドウを作成する方法を見てみましょう。
以下のコードでは、シンプルなウィンドウを作成し、タイトルを設定します。
import tkinter as tk
# Tkinterウィンドウを作成
root = tk.Tk()
root.title("PDF Viewer") # ウィンドウのタイトルを設定
root.geometry("800x600") # ウィンドウのサイズを設定
# ウィンドウを表示
root.mainloop()このコードを実行すると、800×600ピクセルのウィンドウが表示されます。
ウィンドウのタイトルは PDF Viewer となります。
Canvasウィジェットを使った画像表示
次に、Canvasウィジェットを使って画像を表示する方法を見てみましょう。
Canvasは、図形や画像を描画するためのウィジェットです。
以下のコードでは、Canvasを作成し、画像を表示します。
import tkinter as tk
from PIL import Image, ImageTk
# Tkinterウィンドウを作成
root = tk.Tk()
root.title("PDF Viewer")
root.geometry("800x600")
# Canvasを作成
canvas = tk.Canvas(root, bg="white")
canvas.pack(fill=tk.BOTH, expand=True)
# 画像を読み込む
image = Image.open("page1.png")
photo = ImageTk.PhotoImage(image)
# 画像をCanvasに表示
canvas.create_image(0, 0, anchor=tk.NW, image=photo)
# ウィンドウを表示
root.mainloop()このコードでは、Canvasを作成し、create_image()メソッドを使って画像を表示しています。
画像はCanvasの左上隅に配置されます。
PDFページをCanvasに描画する方法
PDFのページをCanvasに描画するためには、まずPyMuPDFを使ってPDFを読み込み、ページを画像として取得する必要があります。
以下のコードでは、PDFの1ページ目をCanvasに描画します。
import tkinter as tk
from PIL import Image, ImageTk
import fitz # PyMuPDFをインポート
# PDFファイルを開く
pdf_file = fitz.open("sample.pdf")
# Tkinterウィンドウを作成
root = tk.Tk()
root.title("PDF Viewer")
root.geometry("800x600")
# Canvasを作成
canvas = tk.Canvas(root, bg="white")
canvas.pack(fill=tk.BOTH, expand=True)
# PDFの1ページ目を取得
page = pdf_file[0]
pix = page.get_pixmap() # ページを画像として取得
image = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
photo = ImageTk.PhotoImage(image)
# 画像をCanvasに表示
canvas.create_image(0, 0, anchor=tk.NW, image=photo)
# ウィンドウを表示
root.mainloop()
# PDFファイルを閉じる
pdf_file.close()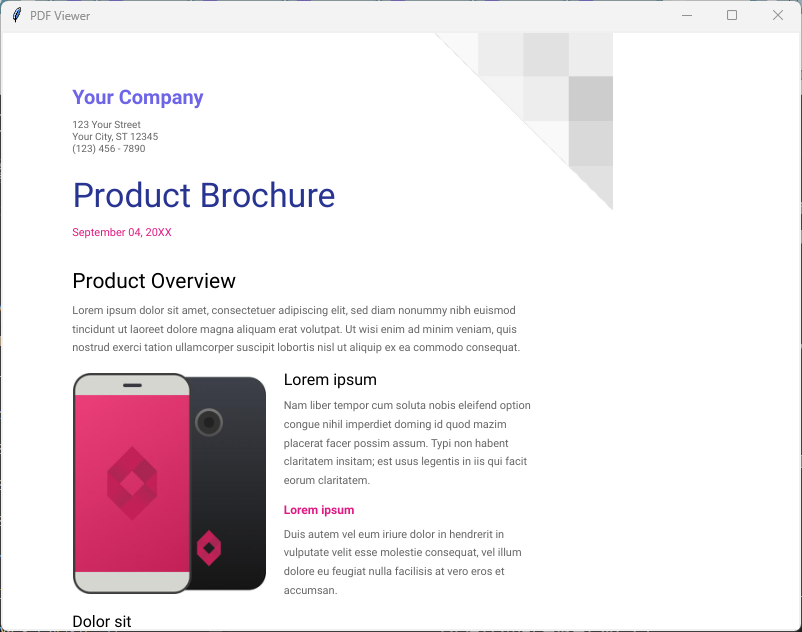
このコードでは、PDFの1ページ目を画像として取得し、Canvasに描画しています。
ページ送り機能の実装
最後に、ページ送り機能を実装します。
ユーザーがボタンをクリックすることで、次のページや前のページに移動できるようにします。
以下のコードでは、ページ送り機能を追加しています。
import tkinter as tk
from PIL import Image, ImageTk
import fitz # PyMuPDFをインポート
# PDFファイルを開く
pdf_file = fitz.open("sample.pdf")
current_page = 0 # 現在のページ番号
# ページをCanvasに描画する関数
def show_page(page_number):
global photo
page = pdf_file[page_number]
pix = page.get_pixmap()
image = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
photo = ImageTk.PhotoImage(image)
canvas.create_image(0, 0, anchor=tk.NW, image=photo)
# 次のページに移動する関数
def next_page():
global current_page
if current_page < pdf_file.page_count - 1:
current_page += 1
show_page(current_page)
# 前のページに移動する関数
def previous_page():
global current_page
if current_page > 0:
current_page -= 1
show_page(current_page)
# Tkinterウィンドウを作成
root = tk.Tk()
root.title("PDF Viewer")
root.geometry("800x600")
# Canvasを作成
canvas = tk.Canvas(root, bg="white")
canvas.pack(fill=tk.BOTH, expand=True)
# ボタンを作成
button_frame = tk.Frame(root)
button_frame.pack(side=tk.BOTTOM, fill=tk.X)
prev_button = tk.Button(button_frame, text="前のページ", command=previous_page)
prev_button.pack(side=tk.LEFT)
next_button = tk.Button(button_frame, text="次のページ", command=next_page)
next_button.pack(side=tk.RIGHT)
# 最初のページを表示
show_page(current_page)
# ウィンドウを表示
root.mainloop()
# PDFファイルを閉じる
pdf_file.close()このコードでは、前のページと次のページに移動するためのボタンを作成し、それぞれのボタンに対応する関数を設定しています。
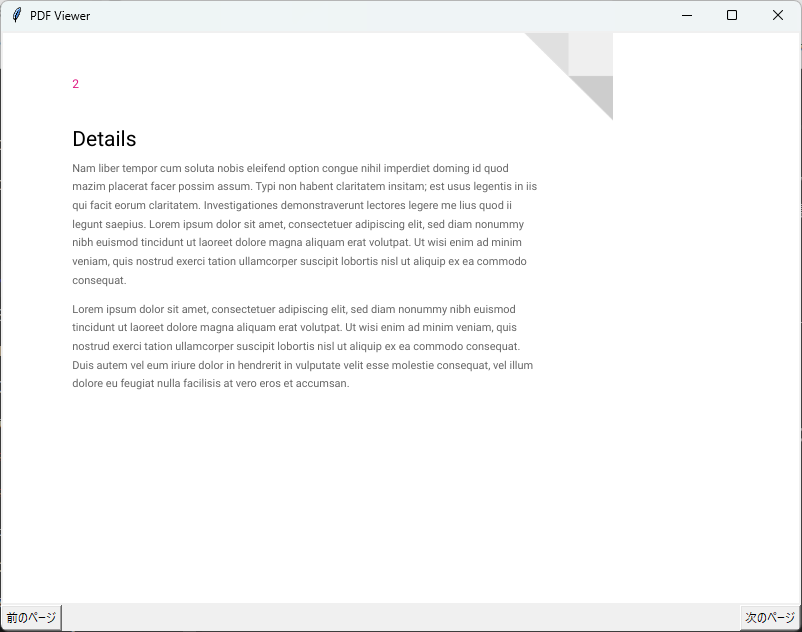
これにより、ユーザーは簡単にPDFのページを移動できるようになります。
次のセクションでは、PyQtを使ってPDFをウィンドウに表示する方法について解説します。
PyQtを使ってPDFをウィンドウに表示する
PyQtは、PythonでGUIアプリケーションを作成するための強力なライブラリです。
ここでは、PyQtを使ってPDFをウィンドウに表示する方法を解説します。
具体的には、基本的なウィンドウの作成から、QLabelウィジェットを使った画像表示、PDFページの描画、そしてページ送り機能の実装について説明します。
PyQtの基本的なウィンドウ作成方法
まずは、PyQtを使って基本的なウィンドウを作成する方法を見てみましょう。
以下のコードでは、シンプルなウィンドウを作成し、タイトルを設定します。
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow
# アプリケーションを作成
app = QApplication(sys.argv)
# メインウィンドウを作成
window = QMainWindow()
window.setWindowTitle("PDF Viewer") # ウィンドウのタイトルを設定
window.setGeometry(100, 100, 800, 600) # ウィンドウのサイズを設定
# ウィンドウを表示
window.show()
# アプリケーションの実行
sys.exit(app.exec_())このコードを実行すると、800×600ピクセルのウィンドウが表示されます。
ウィンドウのタイトルは PDF Viewer となります。
QLabelウィジェットを使った画像表示
次に、QLabelウィジェットを使って画像を表示する方法を見てみましょう。
QLabelは、テキストや画像を表示するためのウィジェットです。
以下のコードでは、QLabelを作成し、画像を表示します。
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow, QLabel
from PyQt5.QtGui import QPixmap
# アプリケーションを作成
app = QApplication(sys.argv)
# メインウィンドウを作成
window = QMainWindow()
window.setWindowTitle("PDF Viewer")
window.setGeometry(100, 100, 800, 600)
# QLabelを作成
label = QLabel(window)
label.setGeometry(0, 0, 800, 600) # QLabelのサイズを設定
# 画像を読み込む
pixmap = QPixmap("page1.png")
label.setPixmap(pixmap) # QLabelに画像を設定
# ウィンドウを表示
window.show()
# アプリケーションの実行
sys.exit(app.exec_())このコードでは、QLabelを作成し、setPixmap()メソッドを使って画像を表示しています。
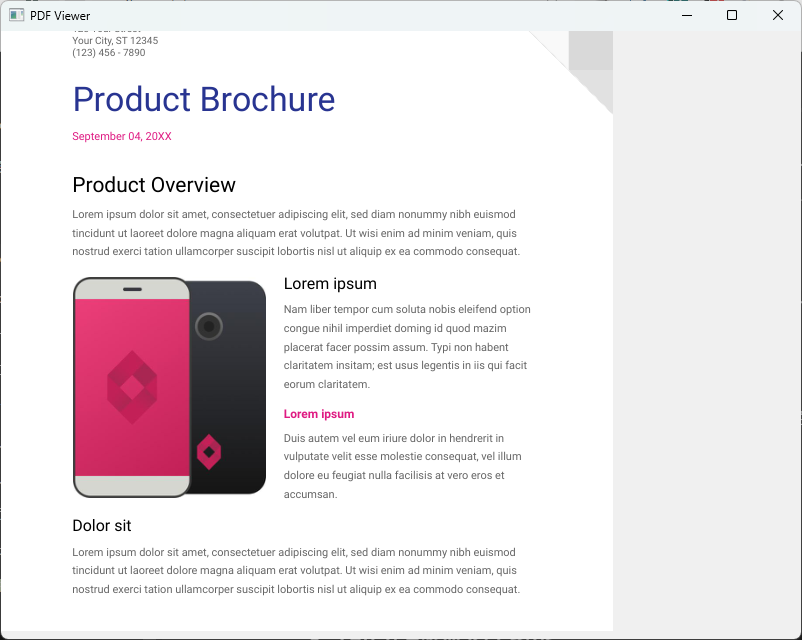
画像はウィンドウの左上隅に配置されます。
PDFページをQLabelに描画する方法
PDFのページをQLabelに描画するためには、まずPyMuPDFを使ってPDFを読み込み、ページを画像として取得する必要があります。
以下のコードでは、PDFの1ページ目をQLabelに描画します。
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow, QLabel
from PyQt5.QtGui import QPixmap
import fitz # PyMuPDFをインポート
# PDFファイルを開く
pdf_file = fitz.open("sample.pdf")
# アプリケーションを作成
app = QApplication(sys.argv)
# メインウィンドウを作成
window = QMainWindow()
window.setWindowTitle("PDF Viewer")
window.setGeometry(100, 100, 800, 600)
# QLabelを作成
label = QLabel(window)
label.setGeometry(0, 0, 800, 600) # QLabelのサイズを設定
# PDFの1ページ目を取得
page = pdf_file[0]
pix = page.get_pixmap() # ページを画像として取得
# QPixmapを作成し、画像データを読み込む
image = QPixmap()
image.loadFromData(pix.tobytes()) # 画像データをQPixmapに読み込む
# QLabelに画像を設定
label.setPixmap(image)
# ウィンドウを表示
window.show()
# アプリケーションの実行
exit_code = app.exec_()
# PDFファイルを閉じる
pdf_file.close()
# アプリケーションを終了
sys.exit(exit_code)このコードでは、PDFの1ページ目を画像として取得し、QLabelに描画しています。
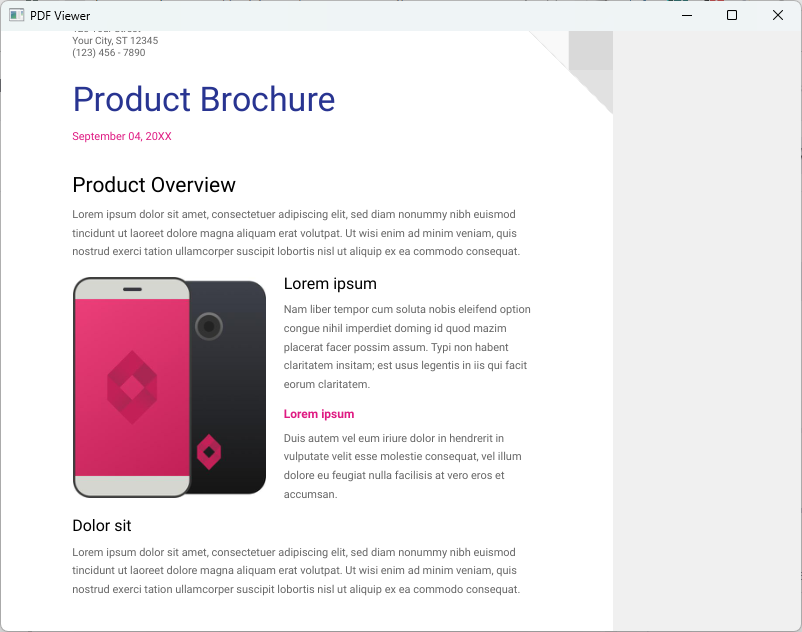
ページ送り機能の実装
最後に、ページ送り機能を実装します。
ユーザーがボタンをクリックすることで、次のページや前のページに移動できるようにします。
以下のコードでは、ページ送り機能を追加しています。
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow, QLabel, QPushButton, QVBoxLayout, QWidget
from PyQt5.QtGui import QPixmap
import fitz # PyMuPDFをインポート
# PDFファイルを開く
pdf_file = fitz.open("sample.pdf")
current_page = 0 # 現在のページ番号
# アプリケーションを作成
app = QApplication(sys.argv)
# メインウィンドウを作成
window = QMainWindow()
window.setWindowTitle("PDF Viewer")
window.setGeometry(100, 100, 800, 600)
# 中央ウィジェットを作成
central_widget = QWidget(window)
window.setCentralWidget(central_widget)
# レイアウトを作成
layout = QVBoxLayout(central_widget)
# QLabelを作成
label = QLabel()
layout.addWidget(label) # QLabelをレイアウトに追加
# ページをQLabelに描画する関数
def show_page(page_number):
global current_page
page = pdf_file[page_number]
pix = page.get_pixmap()
image = QPixmap()
image.loadFromData(pix.tobytes()) # 画像データをQPixmapに読み込む
label.setPixmap(image) # QLabelに画像を設定
# 次のページに移動する関数
def next_page():
global current_page
if current_page < pdf_file.page_count - 1:
current_page += 1
show_page(current_page)
# 前のページに移動する関数
def previous_page():
global current_page
if current_page > 0:
current_page -= 1
show_page(current_page)
# ボタンを作成
prev_button = QPushButton("前のページ")
prev_button.clicked.connect(previous_page) # 前のページボタンに関数を接続
layout.addWidget(prev_button) # ボタンをレイアウトに追加
next_button = QPushButton("次のページ")
next_button.clicked.connect(next_page) # 次のページボタンに関数を接続
layout.addWidget(next_button) # ボタンをレイアウトに追加
# 最初のページを表示
show_page(current_page)
# ウィンドウを表示
window.show()
# アプリケーションの実行
exit_code = app.exec_()
# PDFファイルを閉じる
pdf_file.close()
# アプリケーションを終了
sys.exit(exit_code)このコードでは、前のページと次のページに移動するためのボタンを作成し、それぞれのボタンに対応する関数を設定しています。

これにより、ユーザーは簡単にPDFのページを移動できるようになります。
次のセクションでは、PDFのテキスト抽出と表示について解説します。
PDFのテキスト抽出と表示
PDFファイルからテキストを抽出することは、データの分析や処理において非常に重要です。
ここでは、PyMuPDFとpdfplumberを使ったテキスト抽出方法、そして抽出したテキストをTkinterおよびPyQtで表示する方法について解説します。
PyMuPDFを使ったテキスト抽出方法
PyMuPDFを使用すると、PDFから簡単にテキストを抽出できます。
以下のコードでは、PDFの1ページ目からテキストを抽出し、表示します。
import fitz # PyMuPDFをインポート
# PDFファイルを開く
pdf_file = fitz.open("sample.pdf")
# 1ページ目を取得
page = pdf_file[0]
# テキストを抽出
text = page.get_text()
# 抽出したテキストを表示
print(text)
# PDFファイルを閉じる
pdf_file.close()ここに抽出されたテキストが表示されます。このコードでは、get_text()メソッドを使用してページからテキストを抽出しています。
抽出したテキストは、コンソールに表示されます。
pdfplumberを使ったテキスト抽出方法
pdfplumberを使用すると、より複雑なレイアウトのPDFからも正確にテキストを抽出できます。
以下のコードでは、PDFの1ページ目からテキストを抽出します。
import pdfplumber
# PDFファイルを開く
with pdfplumber.open("sample.pdf") as pdf:
# 1ページ目を取得
page = pdf.pages[0]
# テキストを抽出
text = page.extract_text()
# 抽出したテキストを表示
print(text)ここに抽出されたテキストが表示されます。このコードでは、extract_text()メソッドを使用してページからテキストを抽出しています。
pdfplumberは、テキストのレイアウトを考慮して抽出するため、複雑なPDFでも効果的です。
抽出したテキストをTkinterで表示する方法
抽出したテキストをTkinterで表示するためには、Textウィジェットを使用します。
以下のコードでは、PyMuPDFを使って抽出したテキストをTkinterのウィンドウに表示します。
import tkinter as tk
import fitz # PyMuPDFをインポート
# PDFファイルを開く
pdf_file = fitz.open("sample.pdf")
page = pdf_file[0]
text = page.get_text() # テキストを抽出
# Tkinterウィンドウを作成
root = tk.Tk()
root.title("PDF Text Viewer")
root.geometry("600x400")
# Textウィジェットを作成
text_widget = tk.Text(root)
text_widget.pack(expand=True, fill=tk.BOTH)
# 抽出したテキストをTextウィジェットに挿入
text_widget.insert(tk.END, text)
# ウィンドウを表示
root.mainloop()
# PDFファイルを閉じる
pdf_file.close()このコードでは、抽出したテキストをTextウィジェットに挿入し、ウィンドウに表示しています。
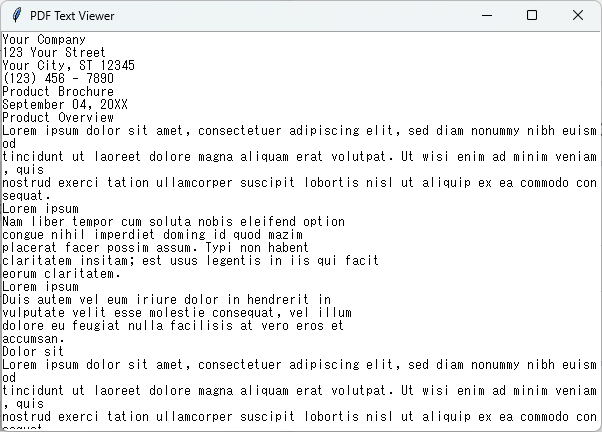
ユーザーはテキストをスクロールして読むことができます。
抽出したテキストをPyQtで表示する方法
抽出したテキストをPyQtで表示するためには、QTextEditウィジェットを使用します。
以下のコードでは、pdfplumberを使って抽出したテキストをPyQtのウィンドウに表示します。
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow, QTextEdit
import pdfplumber
# PDFファイルを開く
with pdfplumber.open("sample.pdf") as pdf:
page = pdf.pages[0]
text = page.extract_text() # テキストを抽出
# アプリケーションを作成
app = QApplication(sys.argv)
# メインウィンドウを作成
window = QMainWindow()
window.setWindowTitle("PDF Text Viewer")
window.setGeometry(100, 100, 600, 400)
# QTextEditを作成
text_edit = QTextEdit(window)
text_edit.setPlainText(text) # 抽出したテキストを設定
window.setCentralWidget(text_edit) # QTextEditを中央ウィジェットに設定
# ウィンドウを表示
window.show()
# アプリケーションの実行
sys.exit(app.exec_())このコードでは、抽出したテキストをQTextEditウィジェットに設定し、ウィンドウに表示しています。
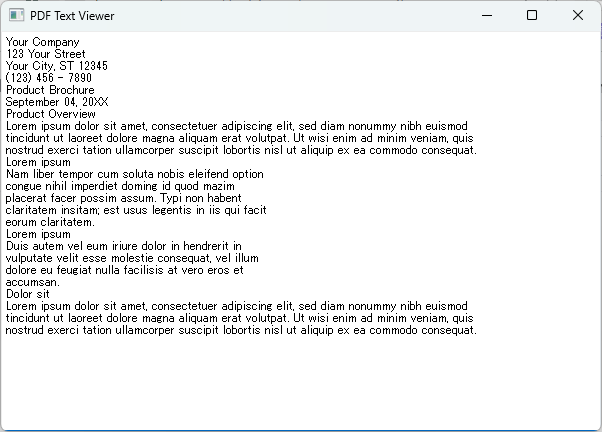
ユーザーはテキストを自由に編集したり、スクロールしたりすることができます。
これで、PDFからテキストを抽出し、TkinterおよびPyQtで表示する方法についての解説は終了です。
次のセクションでは、PDFの特定ページのみを表示する方法について解説します。
応用例:PDFの特定ページのみを表示する
PDFファイルの特定のページを表示することは、ユーザーが必要な情報に迅速にアクセスできるようにするために重要です。
ここでは、特定のページを選択して表示する方法、ページ範囲を指定して表示する方法、そしてページのサムネイルを表示する方法について解説します。
特定のページを選択して表示する方法
特定のページを選択して表示するためには、ユーザーからページ番号を入力させ、そのページを表示する機能を実装します。
以下のコードでは、Tkinterを使って特定のページを表示する方法を示します。
import tkinter as tk
from tkinter import simpledialog
import fitz # PyMuPDFをインポート
# PDFファイルを開く
pdf_file = fitz.open("sample.pdf")
# Tkinterウィンドウを作成
root = tk.Tk()
root.title("PDF Viewer")
root.geometry("800x600")
# Canvasを作成
canvas = tk.Canvas(root, bg="white")
canvas.pack(fill=tk.BOTH, expand=True)
# 特定のページを表示する関数
def show_page(page_number):
page = pdf_file[page_number]
pix = page.get_pixmap()
image = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
photo = ImageTk.PhotoImage(image)
canvas.create_image(0, 0, anchor=tk.NW, image=photo)
# ページ番号を入力させる
page_number = simpledialog.askinteger("ページ番号", "表示したいページ番号を入力してください(0から始まる):")
if page_number is not None and 0 <= page_number < pdf_file.page_count:
show_page(page_number)
# ウィンドウを表示
root.mainloop()
# PDFファイルを閉じる
pdf_file.close()このコードでは、simpledialog.askinteger()を使用してユーザーからページ番号を入力させ、そのページを表示しています。
ページ範囲を指定して表示する方法
ページ範囲を指定して表示する場合、開始ページと終了ページを入力させ、その範囲内のページを表示する機能を実装します。
以下のコードでは、指定した範囲のページを表示します。
import tkinter as tk
from tkinter import simpledialog
import fitz # PyMuPDFをインポート
# PDFファイルを開く
pdf_file = fitz.open("sample.pdf")
# Tkinterウィンドウを作成
root = tk.Tk()
root.title("PDF Viewer")
root.geometry("800x600")
# Canvasを作成
canvas = tk.Canvas(root, bg="white")
canvas.pack(fill=tk.BOTH, expand=True)
# ページ範囲を表示する関数
def show_pages(start_page, end_page):
for page_number in range(start_page, end_page + 1):
page = pdf_file[page_number]
pix = page.get_pixmap()
image = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
photo = ImageTk.PhotoImage(image)
canvas.create_image(0, 0, anchor=tk.NW, image=photo)
root.update() # ウィンドウを更新
# ページ範囲を入力させる
start_page = simpledialog.askinteger("開始ページ", "表示したい開始ページ番号を入力してください(0から始まる):")
end_page = simpledialog.askinteger("終了ページ", "表示したい終了ページ番号を入力してください(0から始まる):")
if start_page is not None and end_page is not None and 0 <= start_page <= end_page < pdf_file.page_count:
show_pages(start_page, end_page)
# ウィンドウを表示
root.mainloop()
# PDFファイルを閉じる
pdf_file.close()このコードでは、ユーザーから開始ページと終了ページを入力させ、その範囲内のページを表示しています。
ページのサムネイルを表示する方法
PDFのページをサムネイルとして表示することで、ユーザーはページの内容を簡単に確認できます。
以下のコードでは、PDFの各ページのサムネイルを表示します。
import tkinter as tk
from PIL import Image, ImageTk
import fitz # PyMuPDFをインポート
# PDFファイルを開く
pdf_file = fitz.open("sample.pdf")
# Tkinterウィンドウを作成
root = tk.Tk()
root.title("PDF Thumbnails")
root.geometry("800x600")
# Canvasを作成
canvas = tk.Canvas(root, bg="white")
canvas.pack(fill=tk.BOTH, expand=True)
# サムネイルを表示する関数
def show_thumbnails():
for page_number in range(pdf_file.page_count):
page = pdf_file[page_number]
pix = page.get_pixmap()
image = Image.frombytes("RGB", [pix.width // 4, pix.height // 4], pix.samples) # サムネイルサイズに縮小
photo = ImageTk.PhotoImage(image)
canvas.create_image(0, page_number * (pix.height // 4), anchor=tk.NW, image=photo)
root.update() # ウィンドウを更新
# サムネイルを表示
show_thumbnails()
# ウィンドウを表示
root.mainloop()
# PDFファイルを閉じる
pdf_file.close()このコードでは、各ページのサムネイルを作成し、Canvasに表示しています。
サムネイルは元のページのサイズを1/4に縮小して表示しています。
これにより、ユーザーはPDFの内容を一目で確認できるようになります。
次のセクションでは、PDFの注釈やハイライトを表示する方法について解説します。
応用例:PDFの注釈やハイライトを表示する
PDFファイルには、注釈やハイライトが含まれていることがあります。
これらの情報を取得し、表示することで、ユーザーは重要なポイントを簡単に確認できます。
ここでは、PDFの注釈を取得する方法、注釈をウィンドウに表示する方法、そしてハイライトされたテキストを抽出して表示する方法について解説します。
PDFの注釈を取得する方法
PyMuPDFを使用すると、PDFの注釈を簡単に取得できます。
以下のコードでは、PDFのすべての注釈を取得し、表示します。
import fitz # PyMuPDFをインポート
# PDFファイルを開く
pdf_file = fitz.open("sample.pdf")
# 注釈を取得
annotations = []
for page in pdf_file:
for annot in page.annots():
annotations.append(annot)
# 注釈を表示
for annot in annotations:
print(f"注釈タイプ: {annot.type[1]}, 内容: {annot.info['title']} - {annot.info['subject']}")
# PDFファイルを閉じる
pdf_file.close()このコードでは、各ページの注釈を取得し、注釈のタイプと内容を表示しています。
annot.typeで注釈の種類を取得し、annot.infoで注釈の詳細情報を取得しています。
注釈をウィンドウに表示する方法
取得した注釈をTkinterを使ってウィンドウに表示する方法を見てみましょう。
以下のコードでは、PDFの注釈をリストボックスに表示します。
import tkinter as tk
import fitz # PyMuPDFをインポート
# PDFファイルを開く
pdf_file = fitz.open("sample.pdf")
# Tkinterウィンドウを作成
root = tk.Tk()
root.title("PDF Annotations")
root.geometry("400x400")
# リストボックスを作成
listbox = tk.Listbox(root)
listbox.pack(expand=True, fill=tk.BOTH)
# 注釈を取得してリストボックスに追加
for page in pdf_file:
for annot in page.annots():
listbox.insert(tk.END, f"{annot.type[1]}: {annot.info['title']} - {annot.info['subject']}")
# ウィンドウを表示
root.mainloop()
# PDFファイルを閉じる
pdf_file.close()このコードでは、PDFの注釈をリストボックスに追加し、ユーザーが注釈を簡単に確認できるようにしています。
ハイライトされたテキストを抽出して表示する方法
PDF内のハイライトされたテキストを抽出するためには、注釈の中からハイライトタイプのものをフィルタリングし、その内容を表示します。
以下のコードでは、ハイライトされたテキストを抽出して表示します。
import fitz # PyMuPDFをインポート
# PDFファイルを開く
pdf_file = fitz.open("sample.pdf")
# ハイライトされたテキストを取得
highlighted_texts = []
for page in pdf_file:
for annot in page.annots():
if annot.type[0] == 8: # ハイライトのタイプ
highlighted_texts.append(annot.info['title']) # タイトルを取得
# ハイライトされたテキストを表示
for text in highlighted_texts:
print(f"ハイライト: {text}")
# PDFファイルを閉じる
pdf_file.close()このコードでは、ハイライトされた注釈をフィルタリングし、その内容を表示しています。
annot.type[0]が8の場合、ハイライト注釈であることを示します。
これで、PDFの注釈やハイライトを取得し、表示する方法についての解説は終了です。
次のセクションでは、PDFの画像を抽出して表示する方法について解説します。
応用例:PDFの画像を抽出して表示する
PDFファイルには、埋め込まれた画像が含まれていることがあります。
これらの画像を抽出し、表示することで、PDFの内容をより豊かにすることができます。
ここでは、PDFから画像を抽出する方法、抽出した画像をTkinterで表示する方法、そしてPyQtで表示する方法について解説します。
PDFから画像を抽出する方法
PyMuPDFを使用すると、PDFから画像を簡単に抽出できます。
以下のコードでは、PDF内のすべての画像を抽出し、保存します。
import fitz # PyMuPDFをインポート
import os
# PDFファイルを開く
pdf_file = fitz.open("sample.pdf")
# 画像を保存するディレクトリを作成
output_dir = "extracted_images"
os.makedirs(output_dir, exist_ok=True)
# PDFから画像を抽出
for page_number in range(len(pdf_file)):
page = pdf_file[page_number]
images = page.get_images(full=True) # すべての画像を取得
for img_index, img in enumerate(images):
xref = img[0] # 画像の参照番号
base_image = pdf_file.extract_image(xref) # 画像を抽出
image_bytes = base_image["image"] # 画像データ
image_filename = os.path.join(output_dir, f"image_page{page_number + 1}_{img_index + 1}.png")
# 画像を保存
with open(image_filename, "wb") as img_file:
img_file.write(image_bytes)
# PDFファイルを閉じる
pdf_file.close()このコードでは、PDF内のすべての画像を抽出し、指定したディレクトリに保存しています。
get_images()メソッドを使用して画像を取得し、extract_image()メソッドで画像データを抽出しています。
抽出した画像をTkinterで表示する方法
抽出した画像をTkinterを使って表示する方法を見てみましょう。
以下のコードでは、指定した画像をTkinterのウィンドウに表示します。
import tkinter as tk
from PIL import Image, ImageTk
import os
# Tkinterウィンドウを作成
root = tk.Tk()
root.title("Extracted Images")
root.geometry("800x600")
# Canvasを作成
canvas = tk.Canvas(root, bg="white")
canvas.pack(fill=tk.BOTH, expand=True)
# 画像を表示する関数
def show_image(image_path):
image = Image.open(image_path)
photo = ImageTk.PhotoImage(image)
canvas.create_image(0, 0, anchor=tk.NW, image=photo)
canvas.image = photo # 参照を保持
# 抽出した画像を表示
image_files = os.listdir("extracted_images")
if image_files:
show_image(os.path.join("extracted_images", image_files[0])) # 最初の画像を表示
# ウィンドウを表示
root.mainloop()このコードでは、抽出した画像の最初のファイルをTkinterのウィンドウに表示しています。
Image.open()を使用して画像を読み込み、ImageTk.PhotoImage()でTkinterに適した形式に変換しています。
抽出した画像をPyQtで表示する方法
抽出した画像をPyQtを使って表示する方法を見てみましょう。
以下のコードでは、指定した画像をPyQtのウィンドウに表示します。
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow, QLabel, QVBoxLayout, QWidget
from PyQt5.QtGui import QPixmap
import os
# アプリケーションを作成
app = QApplication(sys.argv)
# メインウィンドウを作成
window = QMainWindow()
window.setWindowTitle("Extracted Images")
window.setGeometry(100, 100, 800, 600)
# 中央ウィジェットを作成
central_widget = QWidget(window)
window.setCentralWidget(central_widget)
# レイアウトを作成
layout = QVBoxLayout(central_widget)
# 画像を表示する関数
def show_image(image_path):
label = QLabel()
pixmap = QPixmap(image_path)
label.setPixmap(pixmap) # QLabelに画像を設定
layout.addWidget(label) # レイアウトに追加
# 抽出した画像を表示
image_files = os.listdir("extracted_images")
if image_files:
show_image(os.path.join("extracted_images", image_files[0])) # 最初の画像を表示
# ウィンドウを表示
window.show()
# アプリケーションの実行
sys.exit(app.exec_())このコードでは、抽出した画像の最初のファイルをPyQtのウィンドウに表示しています。
QPixmapを使用して画像を読み込み、QLabelに設定しています。
これで、PDFから画像を抽出し、TkinterおよびPyQtで表示する方法についての解説は終了です。
次のセクションでは、PDFのテキスト抽出と表示について解説します。
まとめ
この記事では、Pythonを使用してPDFファイルを扱うためのさまざまな方法について解説しました。
具体的には、PDFの読み込み、ページの表示、テキストや画像の抽出、さらには注釈やハイライトの表示方法に至るまで、幅広い内容を取り上げました。
これらの技術を活用することで、PDFファイルの情報を効果的に利用し、ユーザーにとって便利なアプリケーションを作成することが可能です。
ぜひ、実際にコードを試してみて、PDFの操作に関するスキルを向上させてみてください。
![[Python] markdownテキストの数式(LaTeX)を画像化する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43165.png)
![[Python] markdownテキストをPDFに変換する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43161.png)
![[Python] markdownをパースして読み込む方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43162.png)
![[Python] markdownテキストで改行する際の注意点](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43163.png)
![[Python] markdownをHTMLに変換する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43160.png)
![[Python] 日本語OCRでPDFからテキストを抽出する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43168.png)
![[Python] markdownを読み込む方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43166.png)
![[Python] markdownのテキストを表示する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43167.png)
![[Python] 複数のPDFを結合する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43171.png)
![[Python] PDFをページごとに画像に変換する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43170.png)
![[Python] PDFからテキストを抽出する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43169.png)
![[Python] テキストや画像からPDFを作成する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-43172.png)