[Python] Pandas – CSVファイルのデータでグラフを作成する方法
Pandasを使用してCSVファイルからデータを読み込み、グラフを作成するには、まずpandasでデータを読み込み、matplotlibやseabornなどのライブラリを使って可視化します。
pandas.read_csv()でCSVファイルを読み込み、DataFrameとしてデータを取得します。
その後、DataFrame.plot()メソッドを使って簡単にグラフを作成できます。
matplotlib.pyplotをインポートしておくと、さらにカスタマイズが可能です。
グラフ作成に必要なライブラリ
Pythonでデータを可視化するためには、いくつかのライブラリを使用します。
ここでは、特に人気のあるmatplotlibとseaborn、そしてpandasの基本的な使い方について解説します。
matplotlibのインストール
matplotlibは、Pythonでグラフを描画するための基本的なライブラリです。
以下のコマンドを使用してインストールできます。
pip install matplotlibseabornのインストール
seabornは、matplotlibを基にした高水準のデータ可視化ライブラリです。
美しいグラフを簡単に作成できるため、データ分析において非常に便利です。
インストールは以下のコマンドで行います。
pip install seabornpandas.plot()の基本
pandasはデータ操作のためのライブラリですが、データフレームから直接グラフを描画する機能も持っています。
DataFrame.plot()メソッドを使用することで、簡単にグラフを作成できます。
import pandas as pd
import matplotlib.pyplot as plt
# サンプルデータの作成
data = {'年': [2020, 2021, 2022], '売上': [100, 150, 200]}
df = pd.DataFrame(data)
# 折れ線グラフの作成
df.plot(x='年', y='売上', kind='line')
plt.title('年ごとの売上')
plt.xlabel('年')
plt.ylabel('売上')
plt.show()
matplotlibとseabornの違い
| 特徴 | matplotlib | seaborn |
|---|---|---|
| 基本的な機能 | グラフの描画 | 高度な可視化機能 |
| デフォルトのスタイル | シンプル | 美しいデフォルトスタイル |
| データの扱い | 手動での設定が多い | データフレームとの統合が容易 |
| グラフの種類 | 多様なグラフが描ける | 特に統計的なグラフに強い |
このように、matplotlibは基本的なグラフ描画に適しており、seabornはより美しいグラフを簡単に作成するためのライブラリです。
用途に応じて使い分けることが重要です。
Pandasでグラフを作成する基本手順
pandasを使用すると、データフレームから簡単にグラフを作成できます。
ここでは、DataFrame.plot()メソッドを使った基本的なグラフ作成手順を解説します。
DataFrame.plot()の使い方
DataFrame.plot()メソッドを使用することで、データフレームのデータを基にさまざまな種類のグラフを描画できます。
以下は基本的な使い方の例です。
import pandas as pd
import matplotlib.pyplot as plt
# サンプルデータの作成
data = {'年': [2020, 2021, 2022], '売上': [100, 150, 200]}
df = pd.DataFrame(data)
# グラフの作成
df.plot(x='年', y='売上')
plt.show()
折れ線グラフの作成
折れ線グラフは、データの変化を視覚的に表現するのに適しています。
以下のコードで折れ線グラフを作成できます。
df.plot(x='年', y='売上', kind='line')
plt.title('年ごとの売上')
plt.xlabel('年')
plt.ylabel('売上')
plt.show()棒グラフの作成
棒グラフは、カテゴリごとの比較を行うのに便利です。
以下のコードで棒グラフを作成できます。
df.plot(x='年', y='売上', kind='bar')
plt.title('年ごとの売上')
plt.xlabel('年')
plt.ylabel('売上')
plt.show()散布図の作成
散布図は、2つの変数間の関係を視覚化するのに役立ちます。
以下のコードで散布図を作成できます。
# サンプルデータの作成
data = {'売上': [100, 150, 200], '利益': [20, 30, 50]}
df = pd.DataFrame(data)
# 散布図の作成
df.plot(kind='scatter', x='売上', y='利益')
plt.title('売上と利益の関係')
plt.xlabel('売上')
plt.ylabel('利益')
plt.show()ヒストグラムの作成
ヒストグラムは、データの分布を視覚化するのに適しています。
以下のコードでヒストグラムを作成できます。
# サンプルデータの作成
data = {'売上': [100, 150, 200, 150, 100, 200, 250]}
df = pd.DataFrame(data)
# ヒストグラムの作成
df['売上'].plot(kind='hist', bins=5)
plt.title('売上の分布')
plt.xlabel('売上')
plt.ylabel('頻度')
plt.show()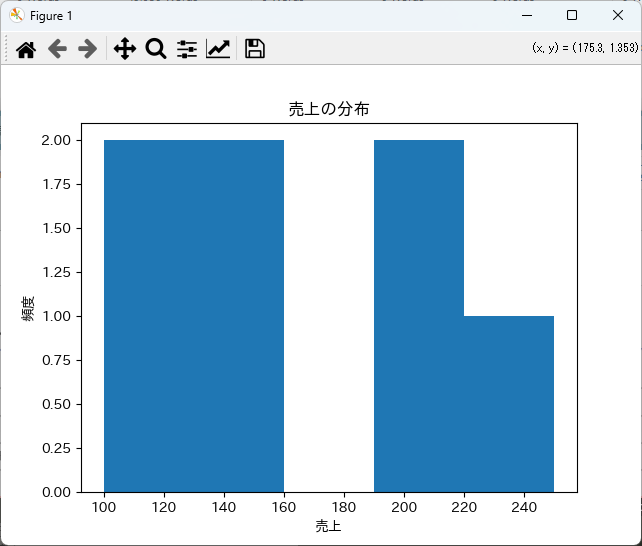
グラフのカスタマイズ
グラフをより見やすくするために、カスタマイズが可能です。
タイトルやラベルの追加
グラフにタイトルや軸ラベルを追加することで、情報を明確に伝えることができます。
plt.title('年ごとの売上')
plt.xlabel('年')
plt.ylabel('売上')軸の範囲設定
軸の範囲を設定することで、特定のデータに焦点を当てることができます。
plt.xlim(2019, 2023) # x軸の範囲を設定
plt.ylim(0, 300) # y軸の範囲を設定凡例の表示
凡例を表示することで、複数のデータ系列を区別しやすくなります。
plt.legend(['売上'])これらのカスタマイズを組み合わせることで、より効果的なグラフを作成できます。
matplotlibを使ったグラフのカスタマイズ
matplotlibを使用すると、グラフの見た目を細かくカスタマイズできます。
ここでは、グラフのサイズ設定や複数のグラフの表示、色やスタイルの変更方法について解説します。
plt.figure()でグラフのサイズを設定
plt.figure()を使用することで、グラフのサイズを指定できます。
以下のコードでは、幅と高さをインチ単位で設定しています。
import pandas as pd
import matplotlib.pyplot as plt
# サンプルデータの作成
data = {'年': [2020, 2021, 2022], '売上': [100, 150, 200]}
df = pd.DataFrame(data)
# グラフのサイズを設定
plt.figure(figsize=(10, 5)) # 幅10インチ、高さ5インチ
df.plot(x='年', y='売上')
plt.title('年ごとの売上')
plt.xlabel('年')
plt.ylabel('売上')
plt.show()
複数のグラフを並べて表示する方法
plt.subplot()を使用することで、複数のグラフを同じウィンドウに並べて表示できます。
以下の例では、2行1列の配置で2つのグラフを表示しています。
# サンプルデータの作成
data1 = {'年': [2020, 2021, 2022], '売上': [100, 150, 200]}
data2 = {'年': [2020, 2021, 2022], '利益': [20, 30, 50]}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
# 1つ目のグラフ
plt.subplot(2, 1, 1) # 2行1列の1番目
df1.plot(x='年', y='売上', title='年ごとの売上')
plt.ylabel('売上')
# 2つ目のグラフ
plt.subplot(2, 1, 2) # 2行1列の2番目
df2.plot(x='年', y='利益', title='年ごとの利益')
plt.ylabel('利益')
plt.tight_layout() # レイアウトの調整
plt.show()
グリッド線の追加
グリッド線を追加することで、データの読み取りが容易になります。
plt.grid()を使用してグリッド線を表示できます。
df.plot(x='年', y='売上')
plt.title('年ごとの売上')
plt.xlabel('年')
plt.ylabel('売上')
plt.grid(True) # グリッド線を表示
plt.show()
色やスタイルの変更
グラフの色やスタイルを変更することで、視覚的な印象を変えることができます。
以下の例では、色と線のスタイルを変更しています。
df.plot(x='年', y='売上', color='orange', linestyle='--', linewidth=2)
plt.title('年ごとの売上')
plt.xlabel('年')
plt.ylabel('売上')
plt.grid(True)
plt.show()
グラフの保存方法
作成したグラフは、画像ファイルとして保存することができます。
plt.savefig()を使用して、指定したファイル名で保存します。
df.plot(x='年', y='売上')
plt.title('年ごとの売上')
plt.xlabel('年')
plt.ylabel('売上')
plt.grid(True)
# グラフをPNG形式で保存
plt.savefig('sales_by_year.png')
plt.show()(グラフが表示され、'sales_by_year.png'として保存されます)このように、matplotlibを使ったグラフのカスタマイズは多岐にわたります。
これらの機能を活用して、より効果的なデータ可視化を行いましょう。
seabornを使った高度な可視化
seabornは、matplotlibを基にした高水準のデータ可視化ライブラリで、特に統計的なデータの可視化に強みを持っています。
ここでは、seabornの基本的な使い方から、さまざまなグラフの作成方法、カスタマイズ方法について解説します。
seabornの基本的な使い方
まず、seabornを使用するためには、ライブラリをインストールする必要があります。
以下のコマンドでインストールできます。
pip install seaborn次に、seabornをインポートし、データを準備して基本的なグラフを作成します。
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# サンプルデータの作成
data = {'年': [2020, 2021, 2022], '売上': [100, 150, 200]}
df = pd.DataFrame(data)
# 基本的な折れ線グラフの作成
sns.lineplot(data=df, x='年', y='売上')
plt.title('年ごとの売上')
plt.show()seabornでの折れ線グラフ作成
seabornを使用すると、簡単に美しい折れ線グラフを作成できます。
以下のコードでは、データフレームを使って折れ線グラフを描画しています。
sns.lineplot(data=df, x='年', y='売上', marker='o')
plt.title('年ごとの売上')
plt.xlabel('年')
plt.ylabel('売上')
plt.show()seabornでのヒートマップ作成
ヒートマップは、データの相関関係を視覚化するのに非常に便利です。
以下のコードでは、相関行列をヒートマップとして表示しています。
# サンプルデータの作成
data = {'売上': [100, 150, 200], '利益': [20, 30, 50], 'コスト': [80, 120, 150]}
df = pd.DataFrame(data)
# 相関行列の計算
correlation_matrix = df.corr()
# ヒートマップの作成
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
plt.title('相関行列のヒートマップ')
plt.show()seabornでのペアプロット作成
ペアプロットは、複数の変数間の関係を視覚化するのに役立ちます。
以下のコードでは、ペアプロットを作成しています。
# サンプルデータの作成
data = {
'売上': [100, 150, 200, 250, 300],
'利益': [20, 30, 50, 70, 90],
'コスト': [80, 120, 150, 180, 210]
}
df = pd.DataFrame(data)
# ペアプロットの作成
sns.pairplot(df)
plt.title('ペアプロット')
plt.show()seabornでのカスタマイズ
seabornでは、グラフのスタイルや色を簡単にカスタマイズできます。
以下の例では、スタイルを変更し、色を指定しています。
# スタイルの設定
sns.set(style='whitegrid')
# 折れ線グラフの作成
sns.lineplot(data=df, x='年', y='売上', color='blue', marker='o', linestyle='--')
plt.title('年ごとの売上')
plt.xlabel('年')
plt.ylabel('売上')
plt.show()このように、seabornを使うことで、データの可視化がより簡単かつ美しく行えます。
さまざまなグラフを活用して、データ分析を効果的に進めましょう。
CSVデータを使った応用的なグラフ作成
CSVファイルは、データ分析や可視化において非常に一般的な形式です。
ここでは、複数のCSVファイルを結合したり、時系列データやグループ化したデータを可視化する方法について解説します。
複数のCSVファイルを結合してグラフを作成
複数のCSVファイルを結合することで、より大きなデータセットを作成し、グラフを描画することができます。
以下の例では、2つのCSVファイルを結合しています。
import pandas as pd
import matplotlib.pyplot as plt
# CSVファイルの読み込み
df1 = pd.read_csv('sales_2020.csv')
df2 = pd.read_csv('sales_2021.csv')
# データフレームの結合
df = pd.concat([df1, df2], ignore_index=True)
# 売上の折れ線グラフを作成
df.plot(x='年', y='売上', kind='line')
plt.title('2020年と2021年の売上')
plt.xlabel('年')
plt.ylabel('売上')
plt.show()(結合したデータの折れ線グラフが表示されます)時系列データの可視化
時系列データを可視化することで、時間の経過に伴う変化を把握できます。
以下の例では、日付をインデックスにしたデータフレームを使用しています。
# サンプルデータの作成
data = {
'日付': pd.date_range(start='2020-01-01', periods=12, freq='M'),
'売上': [100, 150, 200, 250, 300, 350, 400, 450, 500, 550, 600, 650]
}
df = pd.DataFrame(data)
df.set_index('日付', inplace=True)
# 時系列データの折れ線グラフを作成
df.plot()
plt.title('月ごとの売上')
plt.xlabel('日付')
plt.ylabel('売上')
plt.show()(時系列データの折れ線グラフが表示されます)グループ化したデータの可視化
データをグループ化することで、カテゴリごとの集計を行い、可視化することができます。
以下の例では、カテゴリごとの売上を棒グラフで表示しています。
# サンプルデータの作成
data = {
'カテゴリ': ['A', 'B', 'A', 'B', 'A', 'B'],
'売上': [100, 150, 200, 250, 300, 350]
}
df = pd.DataFrame(data)
# カテゴリごとの売上をグループ化
grouped = df.groupby('カテゴリ').sum()
# 棒グラフの作成
grouped.plot(kind='bar')
plt.title('カテゴリごとの売上')
plt.xlabel('カテゴリ')
plt.ylabel('売上')
plt.show()(カテゴリごとの売上の棒グラフが表示されます)ピボットテーブルを使ったグラフ作成
ピボットテーブルを使用することで、データを集計し、可視化することができます。
以下の例では、売上データをピボットテーブルに変換し、ヒートマップを作成しています。
# サンプルデータの作成
data = {
'年': [2020, 2020, 2021, 2021],
'月': ['1月', '2月', '1月', '2月'],
'売上': [100, 150, 200, 250]
}
df = pd.DataFrame(data)
# ピボットテーブルの作成
pivot_table = df.pivot_table(values='売上', index='月', columns='年')
# ヒートマップの作成
sns.heatmap(pivot_table, annot=True, cmap='coolwarm')
plt.title('月ごとの売上(年別)')
plt.show()(ピボットテーブルを使ったヒートマップが表示されます)データのフィルタリングとグラフ作成
特定の条件に基づいてデータをフィルタリングし、その結果を可視化することも可能です。
以下の例では、売上が200以上のデータをフィルタリングしてグラフを作成しています。
# サンプルデータの作成
data = {
'年': [2020, 2021, 2020, 2021],
'売上': [100, 250, 200, 300]
}
df = pd.DataFrame(data)
# 売上が200以上のデータをフィルタリング
filtered_df = df[df['売上'] >= 200]
# フィルタリングしたデータの棒グラフを作成
filtered_df.plot(x='年', y='売上', kind='bar')
plt.title('売上が200以上のデータ')
plt.xlabel('年')
plt.ylabel('売上')
plt.show()(フィルタリングしたデータの棒グラフが表示されます)これらの手法を活用することで、CSVデータを使ったさまざまな応用的なグラフ作成が可能になります。
データ分析や可視化の幅を広げて、より深い洞察を得ることができるでしょう。
まとめ
この記事では、Pythonのpandasやseabornを使用して、CSVファイルからデータを読み込み、さまざまなグラフを作成する方法について詳しく解説しました。
特に、データの可視化における基本的な手法から応用的なテクニックまでを紹介し、実際のコード例を通じて具体的な操作を示しました。
これを機に、データ分析や可視化のスキルを向上させ、実際のプロジェクトに活かしてみてはいかがでしょうか。
![[Python] PandasのRow(列)・Column(行)の理解](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46871.png)
![[Python/Pandas] query関数の使い方 – 条件に合う行を抽出する](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46870.png)
![[Python] plotlyの使い方 – 様々なグラフを描画する](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46869.png)
![[Python/Pandas] pivot_tableの使い方 – ピボットテーブルの作成](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46868.png)
![[Python] Pandasのapply関数の使い方 – 関数の処理を適用する](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46867.png)
![[Python/Pandas] maskメソッドの使い方 – 条件に合う要素だけ処理する](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46866.png)
![[Python] groupbyメソッドの使い方 – 要素のグループ化/集約関数の適用](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46864.png)
![[Python] dropna関数の使い方 – 欠損値(NaN)を削除する](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46863.png)
![[Python] Pandas – DataFrameを結合するconcat()の使い方](https://af-e.net/wp-content/uploads/2024/09/thumbnail-41401.png)
![[Python] Pandas – CSVから値を検索する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-41403.png)
![[Python] Pandas – DataFrameに行・列を追加する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-41410.png)
![[Python] Pandas – 2つのDataFrameを結合する方法](https://af-e.net/wp-content/uploads/2024/09/thumbnail-41405.png)