[Python] difflibモジュールの使い方 – ファイルの比較/差分/一致箇所の検索
Pythonのdifflibモジュールは、シーケンスの比較や差分の計算に便利なツールを提供します。
特に、テキストファイルの比較や一致箇所の検索に役立ちます。
difflib.SequenceMatcherクラスを使うと、2つのシーケンス(文字列やリストなど)の類似度を計算できます。
また、difflib.unified_diffやdifflib.ndiffを使うと、ファイルの差分を表示できます。
これにより、ファイルの変更点や一致箇所を簡単に確認できます。
difflibモジュールとは
difflibモジュールは、Pythonに標準で搭載されているライブラリで、テキストの比較や差分の検出を行うための機能を提供します。
このモジュールは、特に文字列やファイルの類似性を評価する際に非常に便利です。
difflibを使用することで、2つのテキストの違いや一致箇所を簡単に見つけることができ、バージョン管理やデータの比較、テキストの変更履歴の追跡など、さまざまな用途に応用できます。
主な機能としては、文字列の類似度を計算するSequenceMatcherクラス、ファイルの差分を表示するunified_diffやndiff関数、HTML形式で差分を表示するHtmlDiffクラスなどがあります。
これらの機能を活用することで、プログラマーは効率的にテキストの比較作業を行うことができます。
SequenceMatcherクラスの使い方
SequenceMatcherの基本的な使い方
SequenceMatcherクラスは、2つのシーケンス(通常は文字列)を比較し、類似度を計算するためのクラスです。
基本的な使い方は以下の通りです。
from difflib import SequenceMatcher
# 比較する文字列
str1 = "Pythonプログラミング"
str2 = "Pythonプログラミング入門"
# SequenceMatcherのインスタンスを作成
matcher = SequenceMatcher(None, str1, str2)
# 類似度を計算
similarity = matcher.ratio()
print(f"類似度: {similarity:.2f}")類似度: 0.93類似度の計算方法
SequenceMatcherクラスのratio()メソッドを使用することで、2つのシーケンスの類似度を0から1の範囲で計算できます。
1に近いほど類似度が高いことを示します。
計算は、以下の式に基づいて行われます。
\[\text{類似度} = \frac{2 \times \text{一致した文字数}}{\text{シーケンス1の長さ} + \text{シーケンス2の長さ}}\]
一致ブロックの取得
一致ブロックとは、2つのシーケンスの中で一致している部分の情報を示します。
get_matching_blocks()メソッドを使用して、一致ブロックを取得できます。
from difflib import SequenceMatcher
str1 = "Pythonプログラミング"
str2 = "Pythonプログラミング入門"
matcher = SequenceMatcher(None, str1, str2)
matching_blocks = matcher.get_matching_blocks()
for block in matching_blocks:
print(f"一致ブロック: {block}")一致ブロック: Match(a=0, b=0, size=13)
一致ブロック: Match(a=13, b=15, size=0)比較結果の解釈方法
get_matching_blocks()メソッドの出力は、Matchオブジェクトのリストであり、各オブジェクトは一致した部分の開始位置とサイズを示します。
これにより、どの部分が一致しているのかを把握できます。
最初の要素は最初の一致部分、最後の要素は残りの部分を示します。
応用例:文字列の類似度を使ったフィルタリング
文字列の類似度を利用して、特定の条件に基づいてデータをフィルタリングすることができます。
例えば、ユーザーが入力した検索キーワードに対して、候補リストから類似度が高いものを抽出することが可能です。
from difflib import SequenceMatcher
def filter_similar_strings(input_string, candidates):
threshold = 0.7 # 類似度の閾値
similar_candidates = []
for candidate in candidates:
matcher = SequenceMatcher(None, input_string, candidate)
if matcher.ratio() >= threshold:
similar_candidates.append(candidate)
return similar_candidates
# 候補リスト
candidates = ["Pythonプログラミング", "Python入門", "Javaプログラミング", "Pythonの基礎"]
# フィルタリング
result = filter_similar_strings("Pythonプログラミング", candidates)
print("類似度が高い候補:", result)類似度が高い候補: ['Pythonプログラミング']このように、SequenceMatcherを活用することで、文字列の類似度を計算し、データのフィルタリングを行うことができます。
ファイルの差分を表示する方法
unified_diffの使い方
unified_diffは、2つのテキストファイルの差分を統一形式で表示するための関数です。
この形式は、変更された行を前後の文脈とともに表示するため、視覚的に理解しやすいのが特徴です。
基本的な使い方は以下の通りです。
from difflib import unified_diff
# 比較する2つのテキスト
text1 = """\
Pythonは強力なプログラミング言語です。
データ分析や機械学習に広く使われています。
"""
text2 = """\
Pythonは非常に強力なプログラミング言語です。
データ分析や機械学習、Web開発に広く使われています。
"""
# unified_diffを使用して差分を取得
diff = unified_diff(text1.splitlines(), text2.splitlines(), lineterm='', fromfile='file1.txt', tofile='file2.txt')
# 差分を表示
for line in diff:
print(line)--- file1.txt
+++ file2.txt
@@ -1,2 +1,2 @@
-Pythonは強力なプログラミング言語です。
-データ分析や機械学習に広く使われています。
+Pythonは非常に強力なプログラミング言語です。
+データ分析や機械学習、Web開発に広く使われています。ndiffの使い方
ndiffは、2つのテキストの差分を行単位で表示するための関数です。
ndiffは、変更された行を + や - で示し、追加や削除を明示的に表示します。
以下はその基本的な使い方です。
from difflib import ndiff
# 比較する2つのテキスト
text1 = """\
Pythonは強力なプログラミング言語です。
データ分析や機械学習に広く使われています。
"""
text2 = """\
Pythonは非常に強力なプログラミング言語です。
データ分析や機械学習、Web開発に広く使われています。
"""
# ndiffを使用して差分を取得
diff = ndiff(text1.splitlines(), text2.splitlines())
# 差分を表示
for line in diff:
print(line)- Pythonは強力なプログラミング言語です。
+ Pythonは非常に強力なプログラミング言語です。
? +++
- データ分析や機械学習に広く使われています。
+ データ分析や機械学習、Web開発に広く使われています。
? ++++++
ファイルの差分を表示するサンプルコード
以下は、実際のファイルを比較して差分を表示するサンプルコードです。
from difflib import unified_diff
# ファイルを読み込む関数
def read_file(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
return file.readlines()
# ファイルの差分を表示する関数
def show_file_diff(file1, file2):
text1 = read_file(file1)
text2 = read_file(file2)
diff = unified_diff(text1, text2, lineterm='', fromfile=file1, tofile=file2)
for line in diff:
print(line)
# 使用例
show_file_diff('file1.txt', 'file2.txt')差分の出力形式の違い
unified_diffとndiffの出力形式には明確な違いがあります。
| 出力形式 | 特徴 |
|---|---|
| unified_diff | 変更された行を前後の文脈とともに表示。 |
| ndiff | 行単位での変更を + や - で示す。 |
unified_diffは、変更の前後を示すため、変更の影響を理解しやすいですが、ndiffは具体的な変更内容を明示的に示すため、どの行が追加または削除されたかをすぐに把握できます。
応用例:バージョン管理システムでの差分表示
バージョン管理システム(VCS)では、ファイルの変更履歴を追跡するために差分表示が重要です。
difflibモジュールを使用することで、特定のバージョン間の差分を簡単に表示できます。
例えば、Gitのようなシステムでは、コミット間の差分を表示する際にこのような手法が利用されます。
# Gitの差分表示の例
# git diff コマンドを使用して、変更内容を表示することができます。
# 例: git diff HEAD~1 HEADこのように、difflibを活用することで、ファイルの差分を視覚的に理解しやすく表示することができ、バージョン管理やコードレビューの際に非常に役立ちます。
一致箇所の検索
get_matching_blocksメソッドの使い方
get_matching_blocksメソッドは、SequenceMatcherクラスの一部であり、2つのシーケンス間で一致している部分の情報を取得するために使用されます。
このメソッドは、一致した部分の開始位置とサイズを示すMatchオブジェクトのリストを返します。
以下はその基本的な使い方です。
from difflib import SequenceMatcher
# 比較する文字列
str1 = "Pythonプログラミングは楽しい"
str2 = "Pythonプログラミングはとても楽しい"
# SequenceMatcherのインスタンスを作成
matcher = SequenceMatcher(None, str1, str2)
# 一致ブロックを取得
matching_blocks = matcher.get_matching_blocks()
# 一致ブロックを表示
for block in matching_blocks:
print(f"一致ブロック: 開始位置1={block.a}, 開始位置2={block.b}, サイズ={block.size}")一致ブロック: 開始位置1=0, 開始位置2=0, サイズ=18
一致ブロック: 開始位置1=18, 開始位置2=20, サイズ=0一致箇所の抽出方法
一致箇所を抽出するには、get_matching_blocksメソッドで得られたMatchオブジェクトを利用します。
各オブジェクトのaとb属性は、それぞれのシーケンスにおける一致の開始位置を示し、size属性は一致のサイズを示します。
以下は、一致箇所を抽出する方法の例です。
from difflib import SequenceMatcher
str1 = "Pythonプログラミングは楽しい"
str2 = "Pythonプログラミングはとても楽しい"
matcher = SequenceMatcher(None, str1, str2)
matching_blocks = matcher.get_matching_blocks()
# 一致箇所を抽出
for block in matching_blocks:
if block.size > 0: # 一致サイズが0でない場合
match_str1 = str1[block.a:block.a + block.size]
match_str2 = str2[block.b:block.b + block.size]
print(f"一致箇所: '{match_str1}' と '{match_str2}'")一致箇所: 'Pythonプログラミングは' と 'Pythonプログラミングは'応用例:テキストの一致箇所を強調表示する
一致箇所を強調表示することで、視覚的にどの部分が一致しているかを明示することができます。
以下は、HTMLを使用して一致箇所を強調表示する例です。
from difflib import SequenceMatcher
def highlight_matches(str1, str2):
matcher = SequenceMatcher(None, str1, str2)
matching_blocks = matcher.get_matching_blocks()
highlighted_str1 = str1
highlighted_str2 = str2
# 一致箇所を強調表示
for block in matching_blocks:
if block.size > 0:
match_str1 = str1[block.a:block.a + block.size]
match_str2 = str2[block.b:block.b + block.size]
highlighted_str1 = highlighted_str1.replace(match_str1, f"<strong>{match_str1}</strong>")
highlighted_str2 = highlighted_str2.replace(match_str2, f"<strong>{match_str2}</strong>")
return highlighted_str1, highlighted_str2
# 使用例
str1 = "Pythonプログラミングは楽しい"
str2 = "Pythonプログラミングはとても楽しい"
highlighted1, highlighted2 = highlight_matches(str1, str2)
print("強調表示されたテキスト1:", highlighted1)
print("強調表示されたテキスト2:", highlighted2)強調表示されたテキスト1: <strong>Pythonプログラミングは</strong>楽しい
強調表示されたテキスト2: <strong>Pythonプログラミングは</strong>とても楽しいこのように、get_matching_blocksメソッドを使用することで、一致箇所を簡単に抽出し、強調表示することができます。
これにより、テキストの比較がより視覚的に理解しやすくなります。
差分のハイライト表示
HtmlDiffクラスの使い方
HtmlDiffクラスは、difflibモジュールに含まれており、2つのテキストの差分をHTML形式で表示するためのクラスです。
このクラスを使用することで、視覚的にわかりやすい差分表示を簡単に作成できます。
基本的な使い方は以下の通りです。
from difflib import HtmlDiff
# 比較する2つのテキスト
text1 = """\
Pythonは強力なプログラミング言語です。
データ分析や機械学習に広く使われています。
"""
text2 = """\
Pythonは非常に強力なプログラミング言語です。
データ分析や機械学習、Web開発に広く使われています。
"""
# HtmlDiffのインスタンスを作成
html_diff = HtmlDiff()
# 差分をHTML形式で生成
diff_html = html_diff.make_file(text1.splitlines(), text2.splitlines(), fromdesc='file1.txt', todesc='file2.txt')
# HTMLを表示
with open('diff_output.html', 'w', encoding='utf-8') as file:
file.write(diff_html)このコードを実行すると、diff_output.htmlというファイルが生成され、2つのテキストの差分がハイライト表示されたHTMLが作成されます。
HTML形式での差分表示
HtmlDiffクラスを使用すると、差分がHTML形式で表示されるため、Webブラウザで簡単に確認できます。
生成されるHTMLは、変更された行を色分けして表示し、追加された行は緑色、削除された行は赤色で示されます。
これにより、どの部分が変更されたのかを一目で把握することができます。
以下は、生成されたHTMLの一部の例です。
<table>
<tr>
<th></th>
<th>file1.txt</th>
<th>file2.txt</th>
</tr>
<tr>
<td>1</td>
<td>Pythonは強力なプログラミング言語です。</td>
<td class="diff_add">Pythonは非常に強力なプログラミング言語です。</td>
</tr>
<tr>
<td>2</td>
<td>データ分析や機械学習に広く使われています。</td>
<td class="diff_add">データ分析や機械学習、Web開発に広く使われています。</td>
</tr>
</table>応用例:Webアプリケーションでの差分表示
Webアプリケーションにおいて、ユーザーがアップロードしたファイルの変更点を表示する機能は非常に有用です。
HtmlDiffを使用することで、ユーザーがアップロードしたファイルの差分を視覚的に表示することができます。
以下は、Flaskを使用した簡単なWebアプリケーションの例です。
from flask import Flask, request, render_template_string
from difflib import HtmlDiff
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def index():
if request.method == 'POST':
text1 = request.form['text1']
text2 = request.form['text2']
html_diff = HtmlDiff()
diff_html = html_diff.make_file(text1.splitlines(), text2.splitlines(), fromdesc='Original', todesc='Modified')
return render_template_string('''
<h1>差分表示</h1>
<div>{{ diff_html|safe }}</div>
<a href="/">戻る</a>
''', diff_html=diff_html)
return '''
<form method="post">
<h2>元のテキスト</h2>
<textarea name="text1" rows="10" cols="50"></textarea>
<h2>変更後のテキスト</h2>
<textarea name="text2" rows="10" cols="50"></textarea>
<br>
<input type="submit" value="差分を表示">
</form>
'''
if __name__ == '__main__':
app.run(debug=True)このアプリケーションでは、ユーザーが2つのテキストを入力し、送信するとその差分がHTML形式で表示されます。
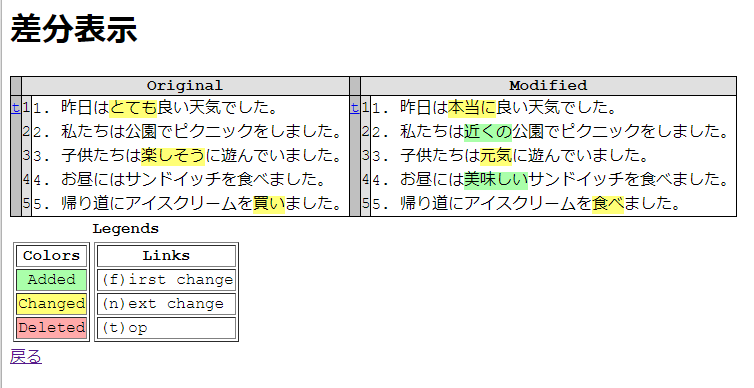
これにより、ユーザーは変更点を簡単に確認できるようになります。
応用例
テキストファイルの変更履歴を追跡する
テキストファイルの変更履歴を追跡するために、difflibモジュールを使用することができます。
例えば、定期的にファイルを更新するシステムにおいて、前のバージョンと新しいバージョンの差分を比較し、変更点を記録することが可能です。
以下は、変更履歴を追跡するための基本的なサンプルコードです。
from difflib import unified_diff
def track_changes(old_file, new_file):
with open(old_file, 'r', encoding='utf-8') as f1, open(new_file, 'r', encoding='utf-8') as f2:
old_text = f1.readlines()
new_text = f2.readlines()
diff = unified_diff(old_text, new_text, fromfile=old_file, tofile=new_file)
for line in diff:
print(line)
# 使用例
track_changes('old_version.txt', 'new_version.txt')このコードを実行することで、指定した2つのファイルの変更点を表示し、変更履歴を簡単に追跡することができます。
類似度を使ったデータクレンジング
データクレンジングのプロセスにおいて、類似度を計算することで、重複データや不正確なデータを特定することができます。
SequenceMatcherを使用して、データセット内の類似したエントリを見つけ、必要に応じて統合や削除を行うことができます。
以下は、類似度を使ったデータクレンジングの例です。
from difflib import SequenceMatcher
def cleanse_data(data):
cleaned_data = []
threshold = 0.8 # 類似度の閾値
for entry in data:
if not any(SequenceMatcher(None, entry, existing).ratio() > threshold for existing in cleaned_data):
cleaned_data.append(entry)
return cleaned_data
# 使用例
data = ["データ分析", "データ分析", "データ解析", "データ分析に関する研究"]
cleaned_data = cleanse_data(data)
print("クレンジング後のデータ:", cleaned_data)クレンジング後のデータ: ['データ分析', 'データ解析', 'データ分析に関する研究']自然言語処理でのテキスト比較
自然言語処理(NLP)の分野では、テキストの比較が重要な役割を果たします。
例えば、文書の類似度を評価することで、情報検索や文書クラスタリングを行うことができます。
difflibを使用して、異なる文書間の類似度を計算し、関連性の高い文書を特定することができます。
from difflib import SequenceMatcher
def compare_documents(doc1, doc2):
matcher = SequenceMatcher(None, doc1, doc2)
similarity = matcher.ratio()
return similarity
# 使用例
doc1 = "Pythonは強力なプログラミング言語です。"
doc2 = "Pythonは非常に強力なプログラミング言語です。"
similarity_score = compare_documents(doc1, doc2)
print(f"文書の類似度: {similarity_score:.2f}")文書の類似度: 0.94バージョン管理システムの差分表示機能の実装
バージョン管理システムでは、ファイルの変更履歴を管理し、差分を表示する機能が不可欠です。
difflibを使用することで、特定のバージョン間の差分を簡単に表示することができます。
以下は、簡単なバージョン管理システムの差分表示機能の実装例です。
from difflib import unified_diff
def show_version_diff(version1, version2):
diff = unified_diff(version1.splitlines(), version2.splitlines(), lineterm='', fromfile='Version 1', tofile='Version 2')
for line in diff:
print(line)
# 使用例
version1 = """\
Pythonは強力なプログラミング言語です。
データ分析や機械学習に広く使われています。
"""
version2 = """\
Pythonは非常に強力なプログラミング言語です。
データ分析や機械学習、Web開発に広く使われています。
"""
show_version_diff(version1, version2)--- Version 1
+++ Version 2
@@ -1,2 +1,2 @@
-Pythonは強力なプログラミング言語です。
-データ分析や機械学習に広く使われています。
+Pythonは非常に強力なプログラミング言語です。
+データ分析や機械学習、Web開発に広く使われています。このように、difflibを活用することで、バージョン管理システムにおける差分表示機能を簡単に実装することができます。
これにより、ユーザーは変更点を迅速に把握し、適切な判断を下すことができるようになります。
まとめ
この記事では、Pythonのdifflibモジュールを使用して、テキストの比較や差分の表示、類似度の計算など、さまざまな機能について詳しく解説しました。
特に、SequenceMatcherやHtmlDiffクラスを活用することで、テキストの一致箇所を見つけたり、差分を視覚的に表示したりする方法を紹介しました。
これにより、データのクレンジングやバージョン管理システムの実装に役立てることができるでしょう。
今後は、実際のプロジェクトにおいてdifflibを活用し、テキストデータの比較や差分表示を行うことで、作業の効率化を図ってみてください。
![[Python] ワイルドカード(*)の使い方 – パス指定/正規表現](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46843.png)
![[Python] with文で複数ファイルを同時に開く方法](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46842.png)
![[Python] with文の使い方 – 安全なファイル読み込み&クローズの実装](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46841.png)
![[Python] with openでファイルがない場合の例外処理を実装する](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46840.png)
![[Python] with openのファイル読み込みでエラー処理を定義する方法](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46839.png)
![[Python] watchdogライブラリの使い方 – フォルダの変更を監視する](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46838.png)
![[Python] tempfile関数の使い方 – 一時ファイル・ディレクトリの作成](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46837.png)
![[Python] sys.path.append関数の使い方 – モジュール検索パスにディレクトリを追加する](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46836.png)
![[Python] seek関数の使い方 – ファイルのカーソル位置の変更](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46835.png)
![[Python] pathlibモジュールの使い方 – 効率よくパスを操作する](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46834.png)
![[Python] os.walkの使い方 – ディレクトリを再帰的に探索する](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46833.png)
![[Python] os.path.joinメソッドの使い方 – ファイルパスの結合](https://af-e.net/wp-content/uploads/2024/10/thumbnail-46832.png)