【C++】OpenCVによる画像処理の基本から高速実装テクニックまで
C++とOpenCVを組み合わせれば、画像の読み込みから高度な特徴抽出まで一つのライブラリで完結します。
cv::Matでデータを保持し、imreadやimshowなどシンプルなAPIがすぐに動作確認を助けます。
コンパイル時はインクルードパスとリンク設定だけ押さえれば、クロスプラットフォームで高速に実行できます。
GPU対応モジュールを活用するとリアルタイム処理も狙え、PoCから製品レベルまで拡張しやすいです。
cv::Matの基礎とメモリ管理
OpenCVの画像処理で最も基本となるデータ構造がcv::Matです。
cv::Matは画像データを格納するためのクラスであり、画像のピクセル情報だけでなく、サイズやチャンネル数、データ型などのメタ情報も管理しています。
ここではcv::Matの内部構造やメモリ管理の仕組み、ROI(Region of Interest)やサブマトリクスの操作方法、画像型とチャンネル数の扱いについて詳しく解説します。
cv::Matの内部構造
cv::Matは単なる画像データの配列ではなく、画像のメタ情報とデータポインタを持つクラスです。
内部的には以下のような要素で構成されています。
- データポインタ: 実際のピクセルデータが格納されているメモリへのポインタ
- サイズ情報: 画像の行数(高さ)、列数(幅)、および次元数
- チャンネル数: 画像の色成分数(例:3チャンネルはBGRカラー画像)
- データ型: ピクセルの型(例:8ビット符号なし整数、32ビット浮動小数点など)
- 参照カウンタ: メモリの共有管理に使われるカウンタ
この構造により、cv::Matは効率的に画像データを扱いながら、コピー時の無駄なメモリ消費を抑えています。
データ共有とコピーオンライト
cv::Matの大きな特徴の一つが「コピーオンライト(Copy-On-Write)」の仕組みです。
これは、cv::Matオブジェクトをコピーした際に、実際の画像データはコピーせず、データポインタを共有するというものです。
これにより、コピー操作が非常に高速になります。
例えば、以下のコードを見てください。
#include <iostream>
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img1 = cv::imread("sample.jpg");
if (img1.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// img1をコピーしてimg2を作成(img2はimg1のコピー)
cv::Mat img2;
img1.copyTo(img2);
// img2の一部を変更してももimg1は変更されない
img2.at<cv::Vec3b>(0, 0) = cv::Vec3b(0, 0, 255); // 左上のピクセルを赤に変更
// img1の左上ピクセルの値を表示
std::cout << "img1(0,0): " << img1.at<cv::Vec3b>(0, 0) << std::endl;
// img2の左上ピクセルの値を表示
std::cout << "img2(0,0): " << img2.at<cv::Vec3b>(0, 0) << std::endl;
return 0;
}img1(0,0): [B, G, R] // 元の色(例:[123, 45, 67])
img2(0,0): [0, 0, 255] // 赤に変更された値この例では、img2はimg1のコピーですが、最初は同じデータを共有しています。
img2のピクセルを変更した瞬間に、OpenCVは内部でデータのコピーを行い、img1のデータは変更されません。
これがコピーオンライトの動作です。
この仕組みにより、複数のcv::Matオブジェクトが同じ画像データを効率的に共有でき、不要なメモリ消費を防げます。
スカラー値とcreate
cv::Matは画像データだけでなく、スカラー値(単一の値)を扱うこともできます。
例えば、画像全体を特定の色で初期化したい場合に便利です。
また、createメソッドを使うと、既存のcv::Matオブジェクトに対して新しいサイズや型のメモリを割り当て直すことができます。
createは、既に割り当てられているメモリが要求に合致していれば再割り当てを行わず、効率的にメモリを管理します。
以下はcreateの例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat mat;
// 3行3列、8ビット3チャンネルの画像を作成
mat.create(3, 3, CV_8UC3);
// 全ピクセルを青色に初期化
mat = cv::Scalar(255, 0, 0); // BGR順なので青
std::cout << "mat:\n" << mat << std::endl;
return 0;
}mat:
[255, 0, 0, 255, 0, 0, 255, 0, 0;
255, 0, 0, 255, 0, 0, 255, 0, 0;
255, 0, 0, 255, 0, 0, 255, 0, 0]このようにcreateでメモリを確保し、cv::Scalarで全画素を同じ値に設定できます。
ROIとサブマトリクス操作
ROI(Region of Interest)は画像の一部分を切り出して処理したい場合に使います。
cv::MatではROIを簡単に扱え、元の画像データをコピーせずに部分領域を参照することが可能です。
ROIはcv::Rectで矩形領域を指定し、cv::Matのoperator()やcv::Mat::rowRange、cv::Mat::colRangeで切り出します。
以下はROIの例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat image = cv::imread("image.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// ROIを矩形で指定(x=50, y=50, 幅=100, 高さ=100)
cv::Rect roi(50, 50, 100, 100);
// ROI部分のサブマトリクスを取得(データは共有)
cv::Mat subImage = image(roi);
// ROI部分を赤色で塗りつぶす
subImage = cv::Scalar(0, 0, 255); // BGRで赤
// 変更は元画像にも反映される
cv::imshow("Modified Image", image);
cv::waitKey(0);
return 0;
}このコードでは、元画像の一部を切り出して赤色で塗りつぶしています。
subImageは元画像のデータを共有しているため、subImageの変更はimageにも反映されます。
ROIを使うことで、画像の一部分だけを効率的に処理でき、メモリの無駄遣いを防げます。
画像型とチャンネル数の扱い
OpenCVのcv::Matは画像のデータ型とチャンネル数を組み合わせて表現します。
データ型はピクセルの1チャンネルあたりの型を示し、チャンネル数は色成分の数を示します。
代表的なデータ型は以下の通りです。
| 型名 | 説明 | OpenCV定数 |
|---|---|---|
| 8UC1 | 8ビット符号なし1チャンネル | CV_8UC1 |
| 8UC3 | 8ビット符号なし3チャンネル | CV_8UC3 |
| 16SC1 | 16ビット符号付き1チャンネル | CV_16SC1 |
| 32FC1 | 32ビット浮動小数点1チャンネル | CV_32FC1 |
チャンネル数は1(グレースケール)、3(BGRカラー)、4(BGRAカラー)などがあります。
画像の型はcv::Mat::type()で取得でき、CV_MAT_DEPTH(type)でデータ型、CV_MAT_CN(type)でチャンネル数を取得できます。
以下は型とチャンネル数の確認例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat image = cv::imread("image.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
int type = image.type();
int depth = CV_MAT_DEPTH(type);
int channels = CV_MAT_CN(type);
std::cout << "Image depth: " << depth << std::endl;
std::cout << "Channels: " << channels << std::endl;
// depthの値の意味を表示
switch (depth) {
case CV_8U: std::cout << "8-bit unsigned integer" << std::endl; break;
case CV_8S: std::cout << "8-bit signed integer" << std::endl; break;
case CV_16U: std::cout << "16-bit unsigned integer" << std::endl; break;
case CV_16S: std::cout << "16-bit signed integer" << std::endl; break;
case CV_32S: std::cout << "32-bit signed integer" << std::endl; break;
case CV_32F: std::cout << "32-bit float" << std::endl; break;
case CV_64F: std::cout << "64-bit float" << std::endl; break;
default: std::cout << "Unknown depth" << std::endl; break;
}
return 0;
}Image depth: 0
Channels: 3
8-bit unsigned integerこの例では、一般的なカラー画像(8ビット3チャンネル)であることがわかります。
画像処理の際は、データ型とチャンネル数を正しく理解し、適切な型変換やチャンネル分割を行うことが重要です。
例えば、グレースケール画像に変換したい場合はcv::cvtColorを使い、3チャンネルから1チャンネルに変換します。
これらのcv::Matの基礎知識を押さえることで、OpenCVを使った画像処理の土台がしっかり固まります。
効率的なメモリ管理や部分領域の操作、型の扱いを理解して、より高度な処理に挑戦してみてください。
画像入出力
imreadでのカラーフラグ指定
cv::imread関数は画像ファイルを読み込む際に、どのように画像を読み込むかを指定するためのフラグを受け取れます。
これにより、カラー画像として読み込むか、グレースケールとして読み込むか、あるいはアルファチャンネルを含めるかを制御できます。
主なフラグは以下の通りです。
| フラグ名 | 説明 | 定数値(OpenCV 4.x) |
|---|---|---|
cv::IMREAD_COLOR | カラー画像として読み込む(3チャンネルBGR) | 1 |
cv::IMREAD_GRAYSCALE | グレースケール画像として読み込む(1チャンネル) | 0 |
cv::IMREAD_UNCHANGED | 画像のアルファチャンネルも含めて読み込む | -1 |
デフォルトはcv::IMREAD_COLORで、カラー画像として読み込みます。
以下はフラグを指定して画像を読み込む例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// カラー画像として読み込み
cv::Mat colorImage = cv::imread("image.png", cv::IMREAD_COLOR);
if (colorImage.empty()) {
std::cerr << "カラー画像の読み込みに失敗しました。" << std::endl;
return -1;
}
std::cout << "カラー画像のサイズ: " << colorImage.cols << "x" << colorImage.rows << std::endl;
// グレースケール画像として読み込み
cv::Mat grayImage = cv::imread("image.png", cv::IMREAD_GRAYSCALE);
if (grayImage.empty()) {
std::cerr << "グレースケール画像の読み込みに失敗しました。" << std::endl;
return -1;
}
std::cout << "グレースケール画像のサイズ: " << grayImage.cols << "x" << grayImage.rows << std::endl;
// アルファチャンネルを含めて読み込み
cv::Mat unchangedImage = cv::imread("image.png", cv::IMREAD_UNCHANGED);
if (unchangedImage.empty()) {
std::cerr << "アルファチャンネル付き画像の読み込みに失敗しました。" << std::endl;
return -1;
}
std::cout << "アルファチャンネル付き画像のチャンネル数: " << unchangedImage.channels() << std::endl;
return 0;
}カラー画像のサイズ: 640x480
グレースケール画像のサイズ: 640x480
アルファチャンネル付き画像のチャンネル数: 4このように、フラグを変えることで読み込む画像のチャンネル数や色空間を制御できます。
アルファチャンネルが必要な場合はIMREAD_UNCHANGEDを使い、単純に明度だけが欲しい場合はIMREAD_GRAYSCALEを使うと効率的です。
imwriteの圧縮パラメータ
cv::imwrite関数は画像をファイルに保存する際に、フォーマットごとに圧縮率や品質を指定できるパラメータを受け取れます。
これにより、ファイルサイズと画質のバランスを調整可能です。
主な画像フォーマットの圧縮パラメータは以下の通りです。
| フォーマット | パラメータ名 | 説明 | 値の範囲 |
|---|---|---|---|
| JPEG | cv::IMWRITE_JPEG_QUALITY | 画質(高いほど画質良好、ファイル大) | 0~100(デフォルト95) |
| PNG | cv::IMWRITE_PNG_COMPRESSION | 圧縮レベル(高いほど圧縮強) | 0~9(デフォルト3) |
| WebP | cv::IMWRITE_WEBP_QUALITY | 画質 | 1~100(デフォルト90) |
パラメータはstd::vector<int>で渡し、キーと値のペアで指定します。
以下はJPEG画像を品質90で保存する例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat image = cv::imread("image.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
std::vector<int> params;
params.push_back(cv::IMWRITE_JPEG_QUALITY);
params.push_back(90); // 品質90で保存
bool result = cv::imwrite("output_quality90.jpg", image, params);
if (!result) {
std::cerr << "画像の保存に失敗しました。" << std::endl;
return -1;
}
std::cout << "JPEG画像を品質90で保存しました。" << std::endl;
return 0;
}JPEG画像を品質90で保存しました。PNGの場合は圧縮レベルを指定できます。
std::vector<int> pngParams = {cv::IMWRITE_PNG_COMPRESSION, 9}; // 最大圧縮
cv::imwrite("output_max_compression.png", image, pngParams);圧縮パラメータを適切に設定することで、ファイルサイズを抑えつつ画質を維持できます。
用途に応じて調整してください。
画像フォーマットごとの注意点
画像フォーマットにはそれぞれ特徴や制約があり、OpenCVでの入出力時に注意が必要です。
| フォーマット | 特徴・注意点 |
|---|---|
| JPEG | 非可逆圧縮。画質とファイルサイズのトレードオフがあります。アルファチャンネルはサポートしない。 |
| PNG | 可逆圧縮。アルファチャンネルをサポート。透過情報を保持したい場合に適しています。 |
| BMP | 非圧縮または簡易圧縮。ファイルサイズが大きくなるが、画質劣化なし。アルファチャンネルはサポートしない。 |
| TIFF | 多様な圧縮方式をサポート。多ページ画像や高ビット深度画像に対応。環境によっては読み込みに制限がある場合も。 |
| WebP | Google開発のフォーマット。可逆・非可逆圧縮両対応。アルファチャンネルもサポート。 |
| GIF | 256色までの制限があり、アニメーション対応。OpenCVは静止画としてのみ読み込み可能です。 |
特にアルファチャンネルを含む画像を扱う場合は、imreadのフラグをIMREAD_UNCHANGEDにし、保存時もPNGやWebPなどアルファをサポートするフォーマットを選ぶ必要があります。
また、JPEGは非可逆圧縮のため、何度も保存を繰り返すと画質が劣化します。
編集を繰り返す場合はPNGなどの可逆圧縮フォーマットを使うと良いでしょう。
ファイルパスの文字コードにも注意が必要です。
特にWindows環境では日本語パスを扱う際に文字化けや読み込み失敗が起こることがあります。
UTF-8対応のOpenCVバージョンを使うか、パスをASCII文字に限定するのが無難です。
これらのポイントを踏まえて、画像の読み込み・保存を適切に行い、効率的で高品質な画像処理を実現してください。
表示とユーザインタフェイス
imshowの非同期更新
cv::imshowは画像をウィンドウに表示するための関数ですが、実は非同期的に動作します。
つまり、imshowを呼び出しただけではすぐに画面に描画されるわけではなく、OpenCVの内部イベントループが処理されるタイミングで画面更新が行われます。
このため、imshowの後にすぐに画像を操作したり、プログラムを終了したりすると、ウィンドウに画像が表示されないことがあります。
画像を確実に表示させるには、cv::waitKeyを使ってイベントループを回す必要があります。
以下のコードはimshowの非同期性を示す例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat image = cv::imread("image.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::imshow("Async Example", image);
// waitKeyを呼ばないとウィンドウがすぐ閉じてしまう
// cv::waitKey(0);
std::cout << "imshowの後にすぐ終了します。" << std::endl;
return 0;
}このコードを実行すると、ウィンドウが一瞬表示されてすぐ閉じてしまい、画像が見えません。
imshowは非同期に描画要求を出すだけで、実際の描画はwaitKeyなどのイベント処理で行われるためです。
waitKeyを使うことで、指定した時間だけイベントループを回し、ウィンドウの更新やキーボード入力の検出が可能になります。
waitKeyによる入力ハンドリング
cv::waitKeyは指定したミリ秒だけキーボード入力を待ち、入力があればそのキーコードを返します。
引数に0を指定すると無限に待機し、何かキーが押されるまで処理が止まります。
この関数はOpenCVのGUIイベントループを回す役割も持っており、imshowで表示したウィンドウの更新やマウスイベントの処理もここで行われます。
以下はwaitKeyを使った簡単な入力待ちの例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat image = cv::imread("image.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::imshow("WaitKey Example", image);
std::cout << "キーを押してください..." << std::endl;
int key = cv::waitKey(0); // キー入力を無限に待つ
std::cout << "押されたキーのコード: " << key << std::endl;
// 'q'キー(ASCIIコード113)で終了
if (key == 'q' || key == 'Q') {
std::cout << "終了します。" << std::endl;
}
return 0;
}キーを押してください...
押されたキーのコード: 113
終了します。waitKeyの戻り値は押されたキーのASCIIコードや特殊キーコードです。
複数のウィンドウを扱う場合も、waitKeyでイベントを処理しないとウィンドウが応答しなくなります。
また、waitKeyに正の値を渡すと、その時間だけ待機し、時間切れの場合は-1を返します。
これを使って動画のフレーム表示やリアルタイム処理のループ制御が可能です。
namedWindowとウィンドウプロパティ
cv::namedWindowは表示用のウィンドウを作成し、ウィンドウの名前やプロパティを設定できます。
imshowはウィンドウ名を指定して画像を表示しますが、namedWindowで事前にウィンドウを作成しておくと、ウィンドウのサイズやリサイズの可否などを細かく制御できます。
namedWindowの主なフラグは以下の通りです。
| フラグ名 | 説明 |
|---|---|
cv::WINDOW_NORMAL | ウィンドウサイズを自由に変更可能 |
cv::WINDOW_AUTOSIZE | 画像サイズに合わせてウィンドウサイズが固定(デフォルト) |
cv::WINDOW_FULLSCREEN | フルスクリーン表示 |
cv::WINDOW_GUI_EXPANDED | 拡張GUI機能を有効にする |
cv::WINDOW_GUI_NORMAL | 標準GUI機能 |
以下はnamedWindowでリサイズ可能なウィンドウを作成し、画像を表示する例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat image = cv::imread("image.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// リサイズ可能なウィンドウを作成
cv::namedWindow("Resizable Window", cv::WINDOW_NORMAL);
// 画像を表示
cv::imshow("Resizable Window", image);
// キー入力を待つ
cv::waitKey(0);
return 0;
}このコードでは、ウィンドウの枠をドラッグして自由にサイズ変更できます。
WINDOW_AUTOSIZEの場合は画像サイズに固定され、リサイズはできません。
また、cv::resizeWindow関数を使うと、プログラムからウィンドウサイズを変更できます。
cv::resizeWindow("Resizable Window", 800, 600);ウィンドウの位置を指定したい場合はcv::moveWindowを使います。
cv::moveWindow("Resizable Window", 100, 100);これらの関数を組み合わせることで、ユーザーフレンドリーなGUIを構築できます。
OpenCVの表示機能はシンプルながら柔軟で、imshowの非同期性を理解し、waitKeyでイベントを処理しつつ、namedWindowでウィンドウの挙動を制御することで、快適な画像表示とユーザインタフェイスを実現できます。
色空間変換
COLOR_BGR2GRAYの変換手順
OpenCVでカラー画像をグレースケール画像に変換する際は、cv::cvtColor関数を使い、変換コードにcv::COLOR_BGR2GRAYを指定します。
OpenCVの標準カラー画像はBGR形式で格納されているため、このコードはBGRからグレースケールへの変換を行います。
変換の内部処理は、各ピクセルのB、G、R成分に対して加重平均を計算し、明度を算出しています。
具体的には以下の式でグレースケール値を求めています。
\[Y = 0.299 \times R + 0.587 \times G + 0.114 \times B\]
この加重は人間の目の感度に基づいており、緑に最も重みが置かれています。
以下はBGR画像をグレースケールに変換するサンプルコードです。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat colorImage = cv::imread("image.jpg");
if (colorImage.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat grayImage;
cv::cvtColor(colorImage, grayImage, cv::COLOR_BGR2GRAY);
cv::imshow("Original", colorImage);
cv::imshow("Grayscale", grayImage);
cv::waitKey(0);
return 0;
}(ウィンドウにカラー画像とグレースケール画像が表示される)このように、cv::cvtColorを使うだけで簡単にグレースケール画像を得られます。
グレースケール画像はチャンネル数が1で、画像処理の前処理や特徴抽出に広く使われます。
HSV変換とマスク生成
HSV色空間は色相(Hue)、彩度(Saturation)、明度(Value)で色を表現し、色の抽出やマスク生成に適しています。
OpenCVではcv::COLOR_BGR2HSVを使ってBGR画像からHSV画像に変換できます。
HSV色空間の特徴は、色相が角度(0〜179の整数値で表現)で表され、特定の色範囲を指定しやすいことです。
例えば、赤色だけを抽出したい場合、色相の範囲を指定してマスクを作成します。
以下は赤色領域を抽出する例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat image = cv::imread("image.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat hsvImage;
cv::cvtColor(image, hsvImage, cv::COLOR_BGR2HSV);
// 赤色の範囲は色相が0〜10と160〜179の2つに分かれるため2つのマスクを作成
cv::Mat lowerRedMask, upperRedMask, redMask;
// 下側の赤色範囲
cv::inRange(hsvImage, cv::Scalar(0, 100, 100), cv::Scalar(10, 255, 255), lowerRedMask);
// 上側の赤色範囲
cv::inRange(hsvImage, cv::Scalar(160, 100, 100), cv::Scalar(179, 255, 255), upperRedMask);
// 2つのマスクを合成
cv::bitwise_or(lowerRedMask, upperRedMask, redMask);
// 元画像とマスクを使って赤色部分だけ抽出
cv::Mat redRegion;
cv::bitwise_and(image, image, redRegion, redMask);
cv::imshow("Original", image);
cv::imshow("Red Mask", redMask);
cv::imshow("Red Region", redRegion);
cv::waitKey(0);
return 0;
}(ウィンドウに元画像、赤色マスク、赤色領域が表示される)このコードでは、cv::inRange関数でHSV画像の特定範囲を二値マスクとして抽出し、cv::bitwise_andで元画像から赤色部分だけを切り出しています。
HSV色空間を使うことで、色の抽出が直感的かつ効果的に行えます。
チャンネル分割と結合
画像の各チャンネルを個別に操作したい場合は、cv::split関数でチャンネル分割を行い、cv::merge関数で複数のチャンネルを結合できます。
これにより、色ごとの処理やチャンネル単位のフィルタリングが可能になります。
以下はBGR画像を3つのチャンネルに分割し、青チャンネルだけを強調して再結合する例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat image = cv::imread("image.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
std::vector<cv::Mat> channels;
cv::split(image, channels); // channels[0]=Blue, [1]=Green, [2]=Red
// 青チャンネルを2倍に強調(255を超えないように制限)
cv::Mat blueEnhanced;
cv::multiply(channels[0], 2.0, blueEnhanced);
cv::threshold(blueEnhanced, blueEnhanced, 255, 255, cv::THRESH_TRUNC);
channels[0] = blueEnhanced;
cv::Mat mergedImage;
cv::merge(channels, mergedImage);
cv::imshow("Original", image);
cv::imshow("Blue Enhanced", mergedImage);
cv::waitKey(0);
return 0;
}(ウィンドウに元画像と青チャンネルが強調された画像が表示される)このように、splitでチャンネルを分割し、個別に処理した後、mergeで再び1つの画像にまとめます。
チャンネル単位の操作は色補正や特徴抽出などでよく使われます。
これらの色空間変換とチャンネル操作を活用することで、色に基づく画像処理や特徴抽出が柔軟に行えます。
OpenCVのcvtColor、inRange、split、mergeを組み合わせて効果的な処理を実装してください。
幾何変換
リサイズと補間アルゴリズム
画像のリサイズは、画像のサイズを変更する基本的な幾何変換の一つです。
OpenCVではcv::resize関数を使ってリサイズを行いますが、この際に補間アルゴリズムを指定することで、画質や処理速度を調整できます。
主な補間アルゴリズムは以下の通りです。
| 補間方法 | OpenCV定数 | 特徴 |
|---|---|---|
| 最近傍補間 (Nearest) | cv::INTER_NEAREST | 最も高速。ピクセル値を単純にコピー。ジャギーが目立ちます。 |
| バイリニア補間 (Bilinear) | cv::INTER_LINEAR | 4近傍の重み付き平均。滑らかな画像になります。デフォルト。 |
| ランチョス補間 (Lanczos) | cv::INTER_LANCZOS4 | 8近傍の高品質補間。シャープで高画質だが処理は重い。 |
Nearest/Bilinear/Lanczosの比較
以下のサンプルコードで、同じ画像を3種類の補間方法でリサイズし、違いを比較します。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat src = cv::imread("image.jpg");
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat resizedNearest, resizedLinear, resizedLanczos;
// 2倍にリサイズ(拡大)
cv::resize(src, resizedNearest, cv::Size(), 2.0, 2.0, cv::INTER_NEAREST);
cv::resize(src, resizedLinear, cv::Size(), 2.0, 2.0, cv::INTER_LINEAR);
cv::resize(src, resizedLanczos, cv::Size(), 2.0, 2.0, cv::INTER_LANCZOS4);
cv::imshow("Original", src);
cv::imshow("Nearest Neighbor", resizedNearest);
cv::imshow("Bilinear", resizedLinear);
cv::imshow("Lanczos", resizedLanczos);
cv::waitKey(0);
return 0;
}(ウィンドウに元画像と3種類のリサイズ画像が表示される)- Nearestは処理が速いですが、拡大時にブロック状のジャギーが目立ちます
- Bilinearは滑らかで自然な拡大が可能で、多くの用途で標準的に使われます
- Lanczosは高品質でエッジがシャープに保たれますが、処理コストが高いです
用途に応じて補間方法を選択してください。
リアルタイム処理ではINTER_LINEARやINTER_NEARESTが多く使われ、画質重視ならINTER_LANCZOS4が適しています。
回転とアフィン変換
画像の回転や平行移動、拡大縮小、せん断などの変換はアフィン変換で表現できます。
アフィン変換は平行線を保ち、変換後も直線が直線のままになる特徴があります。
OpenCVではcv::getRotationMatrix2Dで回転行列を取得し、cv::warpAffineで変換を適用します。
以下は画像を中心に45度回転させる例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat src = cv::imread("image.jpg");
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// 画像中心座標
cv::Point2f center(src.cols / 2.0F, src.rows / 2.0F);
double angle = 45.0; // 回転角度(度)
double scale = 1.0; // 拡大縮小率
// 回転行列を取得
cv::Mat rotMat = cv::getRotationMatrix2D(center, angle, scale);
cv::Mat rotated;
// アフィン変換を適用
cv::warpAffine(src, rotated, rotMat, src.size());
cv::imshow("Original", src);
cv::imshow("Rotated 45 degrees", rotated);
cv::waitKey(0);
return 0;
}(ウィンドウに元画像と45度回転した画像が表示される)
cv::getRotationMatrix2Dは回転中心、回転角度、スケールを指定し、2×3のアフィン変換行列を返します。
warpAffineはこの行列を使って画像を変換します。
アフィン変換は回転以外にも、平行移動やせん断を含む変換行列を自分で作成して適用可能です。
透視変換(射影変換)
透視変換は画像の遠近感を表現できる変換で、4点の対応関係を指定して変換行列を求めます。
アフィン変換より自由度が高く、平行線が必ずしも平行のままではなくなります。
OpenCVではcv::getPerspectiveTransformで変換行列を取得し、cv::warpPerspectiveで変換を適用します。
以下は画像の4点を別の4点に変換して透視変換を行う例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat src = cv::imread("image.jpg");
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// 変換前の4点(例:画像の四隅)
std::vector<cv::Point2f> srcPoints = {
cv::Point2f(0, 0),
cv::Point2f(src.cols - 1, 0),
cv::Point2f(src.cols - 1, src.rows - 1),
cv::Point2f(0, src.rows - 1)
};
// 変換後の4点(例:台形に変形)
std::vector<cv::Point2f> dstPoints = {
cv::Point2f(50, 50),
cv::Point2f(src.cols - 100, 30),
cv::Point2f(src.cols - 50, src.rows - 50),
cv::Point2f(30, src.rows - 30)
};
// 透視変換行列を取得
cv::Mat perspMat = cv::getPerspectiveTransform(srcPoints, dstPoints);
cv::Mat warped;
// 透視変換を適用
cv::warpPerspective(src, warped, perspMat, src.size());
cv::imshow("Original", src);
cv::imshow("Perspective Transform", warped);
cv::waitKey(0);
return 0;
}(ウィンドウに元画像と透視変換後の画像が表示される)
透視変換は、ドキュメントのスキャン補正や、カメラの視点変換、画像の遠近補正などに使われます。
4点の対応関係を正確に指定することが重要です。
これらの幾何変換を使いこなすことで、画像のサイズ変更や回転、遠近補正など多彩な変形処理が可能になります。
用途に応じて補間方法や変換行列を適切に選択してください。
フィルタリングとノイズ除去
平均フィルタとガウシアンフィルタ
画像のノイズ除去や平滑化において、平均フィルタとガウシアンフィルタは基本的な手法です。
どちらも周囲のピクセル値を利用して画素値を置き換え、ノイズを低減しますが、特性が異なります。
平均フィルタ(ボックスフィルタ)
平均フィルタは指定したカーネルサイズの領域内のピクセル値の単純平均を計算し、中心の画素を置き換えます。
ノイズを均一にぼかす効果がありますが、エッジもぼやけやすい欠点があります。
OpenCVではcv::blur関数で実装されます。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat src = cv::imread("noisy_image.jpg");
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat blurred;
// 5x5の平均フィルタを適用
cv::blur(src, blurred, cv::Size(5, 5));
cv::imshow("Original", src);
cv::imshow("Average Filtered", blurred);
cv::waitKey(0);
return 0;
}(ウィンドウに元画像と平均フィルタ適用後の画像が表示される)
ガウシアンフィルタ
ガウシアンフィルタはガウス関数に基づく重み付け平均を行い、中心に近いピクセルほど重みが大きくなります。
これにより、平均フィルタよりもエッジのぼかしが自然で、ノイズ除去効果も高いです。
OpenCVではcv::GaussianBlur関数を使います。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat src = cv::imread("noisy_image.jpg");
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat gaussianBlurred;
// 5x5カーネル、標準偏差0(自動計算)
cv::GaussianBlur(src, gaussianBlurred, cv::Size(5, 5), 0);
cv::imshow("Original", src);
cv::imshow("Gaussian Filtered", gaussianBlurred);
cv::waitKey(0);
return 0;
}(ウィンドウに元画像とガウシアンフィルタ適用後の画像が表示される)
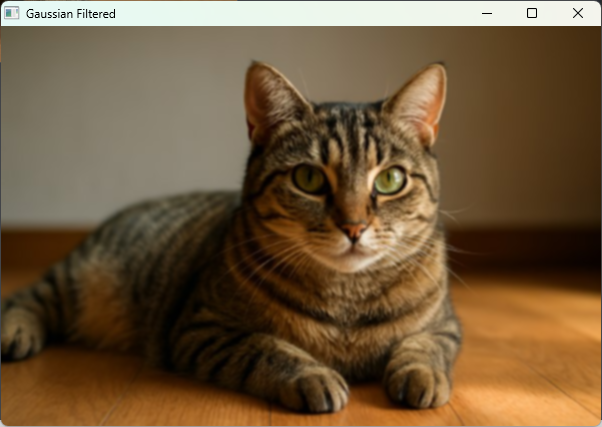
ガウシアンフィルタはエッジの保持とノイズ除去のバランスが良く、多くの画像処理で標準的に使われます。
メディアンフィルタでの塩胡椒ノイズ軽減
塩胡椒ノイズは画像にランダムに黒や白の点が現れるノイズで、平均やガウシアンフィルタでは除去しにくい特徴があります。
メディアンフィルタは指定したカーネル内の中央値を画素値に置き換えるため、塩胡椒ノイズの除去に非常に効果的です。
OpenCVではcv::medianBlur関数を使います。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat noisyImage = cv::imread("salt_pepper_noise.jpg");
if (noisyImage.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat medianFiltered;
// カーネルサイズは奇数(例:5)
cv::medianBlur(noisyImage, medianFiltered, 5);
cv::imshow("Noisy Image", noisyImage);
cv::imshow("Median Filtered", medianFiltered);
cv::waitKey(0);
return 0;
}(ウィンドウに塩胡椒ノイズ画像とメディアンフィルタ適用後の画像が表示される)メディアンフィルタはエッジを比較的保持しつつ、ノイズを効果的に除去できるため、特にランダムな点状ノイズに強いです。
双方向フィルタでのエッジ保持
双方向フィルタ(Bilateral Filter)は、空間的な近さと画素値の類似度の両方を考慮して平滑化を行うフィルタです。
これにより、エッジを保持しながらノイズを除去できます。
OpenCVではcv::bilateralFilter関数で実装されます。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat src = cv::imread("noisy_image.jpg");
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat bilateralFiltered;
// d:近傍直径, sigmaColor:色空間の標準偏差, sigmaSpace:座標空間の標準偏差
cv::bilateralFilter(src, bilateralFiltered, 9, 75, 75);
cv::imshow("Original", src);
cv::imshow("Bilateral Filtered", bilateralFiltered);
cv::waitKey(0);
return 0;
}(ウィンドウに元画像と双方向フィルタ適用後の画像が表示される)dはフィルタの近傍サイズ(ピクセル単位)で、-1を指定すると自動計算されますsigmaColorは色の違いをどの程度考慮するかのパラメータで、大きいほど異なる色も平滑化されやすくなりますsigmaSpaceは空間的な距離の影響範囲を決めます
双方向フィルタはエッジをぼかさずにノイズを除去できるため、顔画像の美肌処理や輪郭検出前の前処理などに適しています。
ただし計算コストは高めです。
これらのフィルタリング手法を使い分けることで、ノイズの種類や処理目的に応じた効果的なノイズ除去が可能です。
平均・ガウシアンは一般的な平滑化、メディアンは点状ノイズに強く、双方向フィルタはエッジを保持しながらノイズを抑えたい場合に有効です。
エッジ検出と特徴抽出
Cannyエッジ検出のパラメータ調整
Cannyエッジ検出は画像のエッジを検出する代表的な手法で、ノイズ除去からエッジの強度判定まで複数のステップを経て高精度なエッジを抽出します。
OpenCVではcv::Canny関数で実装されており、主に以下のパラメータを調整します。
- threshold1: エッジの強度の下限(低い閾値)
- threshold2: エッジの強度の上限(高い閾値)
- apertureSize: Sobelフィルタのサイズ(3, 5, 7など)
- L2gradient: 勾配の計算方法(
trueでL2ノルム、falseでL1ノルム)
threshold1とthreshold2はヒステリシス閾値処理に使われ、強いエッジと弱いエッジを区別します。
一般的にthreshold2はthreshold1の約2倍に設定されることが多いです。
以下はCannyエッジ検出の例とパラメータ調整のサンプルコードです。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat src = cv::imread("image.jpg", cv::IMREAD_GRAYSCALE);
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat edges;
double lowThreshold = 50;
double highThreshold = 150;
int apertureSize = 3;
bool L2gradient = false;
cv::Canny(src, edges, lowThreshold, highThreshold, apertureSize, L2gradient);
cv::imshow("Original", src);
cv::imshow("Canny Edges", edges);
cv::waitKey(0);
return 0;
}(ウィンドウに元画像とCannyエッジ検出結果が表示される)
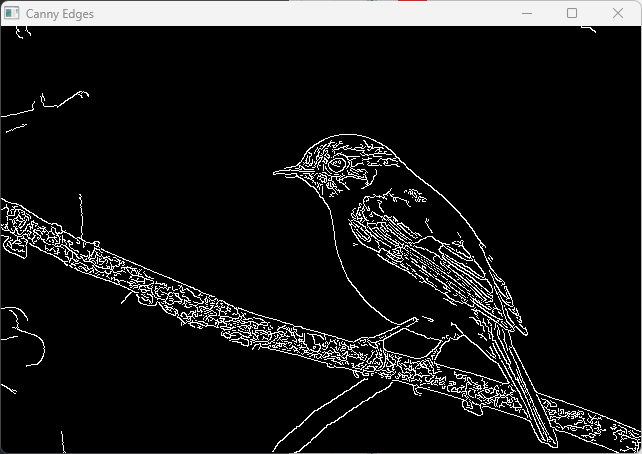
パラメータを変えるとエッジの検出感度が変わるため、画像の特性に合わせて調整してください。
apertureSizeを大きくするとエッジ検出が滑らかになりますが、計算コストも増えます。
LaplacianとSobelの勾配計算
エッジ検出の基礎として、画像の勾配(輝度変化)を計算する方法にLaplacianフィルタとSobelフィルタがあります。
Laplacianフィルタ
Laplacianは2階微分を用いて画像の急激な変化点(エッジ)を検出します。
OpenCVのcv::Laplacian関数で実装され、ノイズに敏感なため前処理としてガウシアンブラーをかけることが多いです。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat src = cv::imread("image.jpg", cv::IMREAD_GRAYSCALE);
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat blurred, laplacian;
cv::GaussianBlur(src, blurred, cv::Size(3, 3), 0);
cv::Laplacian(blurred, laplacian, CV_16S, 3);
cv::Mat absLaplacian;
cv::convertScaleAbs(laplacian, absLaplacian);
cv::imshow("Original", src);
cv::imshow("Laplacian", absLaplacian);
cv::waitKey(0);
return 0;
}(ウィンドウに元画像とLaplacianエッジ画像が表示される)
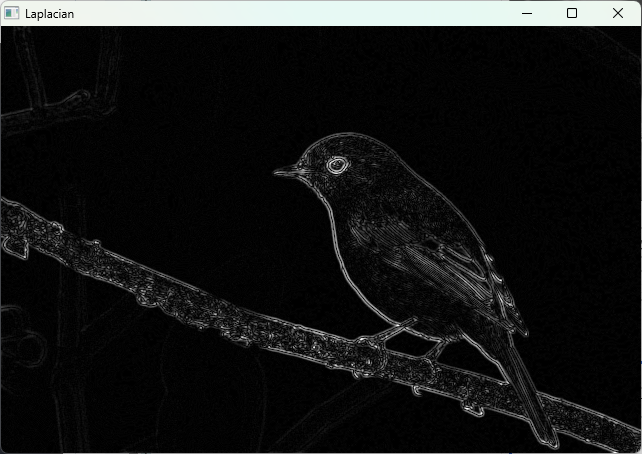
Sobelフィルタ
Sobelフィルタは1階微分を用いて水平方向や垂直方向の勾配を計算します。
cv::Sobel関数で実装され、X方向とY方向の勾配を別々に計算し、合成してエッジ強度を求めることが多いです。
#include <opencv2/opencv.hpp>
#include <iostream>
#include <cmath>
int main() {
cv::Mat src = cv::imread("image.jpg", cv::IMREAD_GRAYSCALE);
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat gradX, gradY;
cv::Sobel(src, gradX, CV_16S, 1, 0, 3);
cv::Sobel(src, gradY, CV_16S, 0, 1, 3);
cv::Mat absGradX, absGradY;
cv::convertScaleAbs(gradX, absGradX);
cv::convertScaleAbs(gradY, absGradY);
cv::Mat grad;
cv::addWeighted(absGradX, 0.5, absGradY, 0.5, 0, grad);
cv::imshow("Original", src);
cv::imshow("Sobel Gradient", grad);
cv::waitKey(0);
return 0;
}(ウィンドウに元画像とSobel勾配画像が表示される)
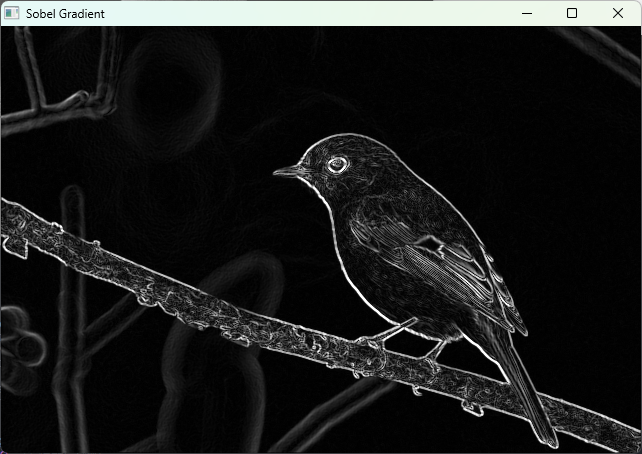
Sobelはエッジの方向情報も得られるため、エッジ検出や特徴抽出の前処理としてよく使われます。
HOG特徴量の算出
HOG(Histogram of Oriented Gradients)は物体検出や画像認識で広く使われる特徴量で、局所的な勾配方向のヒストグラムを計算します。
OpenCVではcv::HOGDescriptorクラスを使って簡単に計算できます。
以下は画像からHOG特徴量を算出する例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat image = cv::imread("person.jpg", cv::IMREAD_GRAYSCALE);
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// HOGDescriptorの初期化(デフォルトパラメータ)
cv::HOGDescriptor hog;
// HOG特徴量を格納するベクトル
std::vector<float> descriptors;
// 画像サイズをHOGDescriptorのウィンドウサイズに合わせる必要がある場合がある
cv::resize(image, image, hog.winSize);
// HOG特徴量を計算
hog.compute(image, descriptors);
std::cout << "HOG特徴量の次元数: " << descriptors.size() << std::endl;
return 0;
}HOG特徴量の次元数: 3780HOG特徴量は物体の形状や輪郭の情報を効果的に表現し、SVMなどの機械学習と組み合わせて歩行者検出などに使われます。
hog.computeは画像の勾配方向のヒストグラムを計算し、特徴ベクトルとして返します。
これらのエッジ検出と特徴抽出手法を適切に使い分けることで、画像の輪郭検出や物体認識の精度向上に役立ちます。
パラメータ調整や前処理を工夫しながら最適な結果を目指してください。
形態学的処理
膨張と収縮
形態学的処理は主に二値画像に対して行われる画像処理手法で、画像の形状や構造を操作するために使われます。
基本的な操作として「膨張(Dilation)」と「収縮(Erosion)」があります。
- 膨張(Dilation)
膨張は画像の白い領域(前景)を拡大する処理です。
指定した構造要素(カーネル)を画像上でスライドさせ、カーネルが重なる領域に白い画素が1つでもあれば、その中心画素を白にします。
これにより、細い線が太くなったり、小さな穴が埋まったりします。
- 収縮(Erosion)
収縮は画像の白い領域を縮小する処理です。
カーネルが重なる領域のすべての画素が白でなければ、中心画素を黒にします。
これにより、ノイズの除去や細い線の細化が可能です。
OpenCVではcv::dilateとcv::erode関数で実装されます。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat src = cv::imread("binary_image.png", cv::IMREAD_GRAYSCALE);
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// 二値化(閾値処理)
cv::Mat binary;
cv::threshold(src, binary, 128, 255, cv::THRESH_BINARY);
// 3x3の正方形カーネルを作成
cv::Mat kernel = cv::getStructuringElement(cv::MORPH_RECT, cv::Size(3, 3));
cv::Mat dilated, eroded;
cv::dilate(binary, dilated, kernel);
cv::erode(binary, eroded, kernel);
cv::imshow("Original Binary", binary);
cv::imshow("Dilated", dilated);
cv::imshow("Eroded", eroded);
cv::waitKey(0);
return 0;
}(ウィンドウに元の二値画像、膨張処理後、収縮処理後の画像が表示される)



膨張は物体の境界を広げ、収縮は境界を縮めるため、ノイズ除去や形状の調整に役立ちます。
オープニングとクロージング
オープニング(Opening)とクロージング(Closing)は膨張と収縮を組み合わせた形態学的処理で、ノイズ除去や穴埋めに効果的です。
- オープニング(Opening)
収縮を先に行い、その後に膨張を行います。
小さな白いノイズを除去し、物体の形状を大きく変えずに滑らかにします。
- クロージング(Closing)
膨張を先に行い、その後に収縮を行います。
小さな黒い穴や隙間を埋める効果があります。
OpenCVではcv::morphologyEx関数を使い、cv::MORPH_OPENやcv::MORPH_CLOSEを指定して実行します。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat src = cv::imread("noisy_binary.png", cv::IMREAD_GRAYSCALE);
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat binary;
cv::threshold(src, binary, 128, 255, cv::THRESH_BINARY);
cv::Mat kernel = cv::getStructuringElement(cv::MORPH_ELLIPSE, cv::Size(5, 5));
cv::Mat opened, closed;
cv::morphologyEx(binary, opened, cv::MORPH_OPEN, kernel);
cv::morphologyEx(binary, closed, cv::MORPH_CLOSE, kernel);
cv::imshow("Original Binary", binary);
cv::imshow("Opened", opened);
cv::imshow("Closed", closed);
cv::waitKey(0);
return 0;
}(ウィンドウに元の二値画像、オープニング処理後、クロージング処理後の画像が表示される)



オープニングは小さな白ノイズを除去し、クロージングは小さな黒穴を埋めるため、画像の前処理でよく使われます。
距離変換とスケルトン化
距離変換
距離変換は二値画像の白い領域の各画素に対して、最も近い黒い画素までの距離を計算する処理です。
これにより、物体の中心部や形状の特徴を把握できます。
OpenCVのcv::distanceTransform関数で実装され、距離の計算方法としてユークリッド距離やチェビシェフ距離などを選べます。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat src = cv::imread("binary_shape.png", cv::IMREAD_GRAYSCALE);
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat binary;
cv::threshold(src, binary, 128, 255, cv::THRESH_BINARY);
cv::Mat dist;
cv::distanceTransform(binary, dist, cv::DIST_L2, 3);
// 距離画像を可視化のために正規化
cv::Mat distNormalized;
cv::normalize(dist, distNormalized, 0, 1.0, cv::NORM_MINMAX);
cv::imshow("Original Binary", binary);
cv::imshow("Distance Transform", distNormalized);
cv::waitKey(0);
return 0;
}(ウィンドウに元の二値画像と距離変換結果の画像が表示される)距離変換は物体の中心点検出や形状解析、スケルトン化の前処理に使われます。
スケルトン化
スケルトン化は物体の形状を細い線(骨格)で表現する処理で、形状の特徴抽出やパターン認識に役立ちます。
OpenCVには直接のスケルトン化関数はありませんが、距離変換や形態学的処理を組み合わせて実装可能です。
以下は簡単なスケルトン化の例(Zhang-Suen法の代替として形態学的手法を利用)です。
#include <opencv2/opencv.hpp>
#include <iostream>
void thinningIteration(cv::Mat& img, int iter) {
cv::Mat marker = cv::Mat::zeros(img.size(), CV_8UC1);
for (int i = 1; i < img.rows - 1; i++) {
for (int j = 1; j < img.cols - 1; j++) {
uchar p2 = img.at<uchar>(i - 1, j);
uchar p3 = img.at<uchar>(i - 1, j + 1);
uchar p4 = img.at<uchar>(i, j + 1);
uchar p5 = img.at<uchar>(i + 1, j + 1);
uchar p6 = img.at<uchar>(i + 1, j);
uchar p7 = img.at<uchar>(i + 1, j - 1);
uchar p8 = img.at<uchar>(i, j - 1);
uchar p9 = img.at<uchar>(i - 1, j - 1);
int A = (p2 == 0 && p3 == 1) + (p3 == 0 && p4 == 1) +
(p4 == 0 && p5 == 1) + (p5 == 0 && p6 == 1) +
(p6 == 0 && p7 == 1) + (p7 == 0 && p8 == 1) +
(p8 == 0 && p9 == 1) + (p9 == 0 && p2 == 1);
int B = p2 + p3 + p4 + p5 + p6 + p7 + p8 + p9;
int m1 = (iter == 0) ? (p2 * p4 * p6) : (p2 * p4 * p8);
int m2 = (iter == 0) ? (p4 * p6 * p8) : (p2 * p6 * p8);
if (A == 1 && (B >= 2 && B <= 6) && m1 == 0 && m2 == 0)
marker.at<uchar>(i, j) = 1;
}
}
img &= ~marker;
}
void thinning(cv::Mat& img) {
img /= 255;
cv::Mat prev = cv::Mat::zeros(img.size(), CV_8UC1);
cv::Mat diff;
do {
thinningIteration(img, 0);
thinningIteration(img, 1);
cv::absdiff(img, prev, diff);
img.copyTo(prev);
} while (cv::countNonZero(diff) > 0);
img *= 255;
}
int main() {
cv::Mat src = cv::imread("binary_shape.png", cv::IMREAD_GRAYSCALE);
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat binary;
cv::threshold(src, binary, 128, 255, cv::THRESH_BINARY);
thinning(binary);
cv::imshow("Skeleton", binary);
cv::waitKey(0);
return 0;
}(ウィンドウにスケルトン化された細線画像が表示される)スケルトン化は物体の形状解析やパターン認識において重要な前処理であり、形態学的処理の応用例の一つです。
これらの形態学的処理を活用することで、画像の構造的特徴を抽出し、ノイズ除去や形状解析、パターン認識の精度向上に役立てられます。
用途に応じて膨張・収縮やオープニング・クロージング、距離変換やスケルトン化を使い分けてください。
特徴マッチング
ORB/SIFT/SURFの特徴比較
画像の特徴点検出と記述子生成は、物体認識や画像マッチングの基盤技術です。
OpenCVでよく使われる代表的な特徴量抽出アルゴリズムにORB、SIFT、SURFがあります。
それぞれの特徴を比較します。
| 特徴量 | 特徴点検出方法 | 記述子の種類 | 特徴点数 | 特徴量の次元数 | 特徴点の回転・スケール不変性 | 特徴点の精度 | 特許・ライセンス | 処理速度 |
|---|---|---|---|---|---|---|---|---|
| ORB | FAST + Harrisコーナー検出 | バイナリ記述子(BRIEF改良版) | 多い | 32バイト | 回転不変、スケールは限定的 | 中程度 | 無料(BSDライセンス) | 高速 |
| SIFT | Difference of Gaussian (DoG) | 浮動小数点記述子 | 中程度 | 128次元 | 回転・スケール不変 | 高い | 特許あり(商用利用注意) | 遅い |
| SURF | Hessian行列ベース | 浮動小数点記述子 | 中程度 | 64次元 | 回転・スケール不変 | 高い | 特許あり(商用利用注意) | SIFTより高速 |
- ORB (Oriented FAST and Rotated BRIEF)
ORBは高速かつ無料で使える特徴量で、リアルタイム処理に適しています。
バイナリ記述子のためマッチングも高速ですが、スケール変化に対してはSIFTやSURFほど強くありません。
- SIFT (Scale-Invariant Feature Transform)
スケールと回転に不変な特徴点を検出し、高精度なマッチングが可能です。
特許の関係で商用利用には注意が必要ですが、研究用途では広く使われています。
- SURF (Speeded-Up Robust Features)
SIFTの高速版として開発され、処理速度が速い一方で特許の制約があります。
特徴量の次元がSIFTより少なく、計算コストが抑えられています。
Brute-ForceとFLANNのマッチャー
特徴点のマッチングは、2つの画像の特徴記述子間の類似度を計算し、対応点を見つける処理です。
OpenCVでは主に以下の2種類のマッチャーが使われます。
- Brute-Force Matcher (BFMatcher)
全ての特徴点の組み合わせを比較して最も類似度の高いペアを探します。
単純で確実ですが、特徴点数が多いと計算コストが高くなります。
- FLANN Matcher (Fast Library for Approximate Nearest Neighbors)
近似的な最近傍探索アルゴリズムを使い、高速にマッチングを行います。
大規模な特徴点セットに適しています。
以下はORB特徴量を使い、BFMatcherとFLANN Matcherでマッチングする例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat img1 = cv::imread("image1.jpg", cv::IMREAD_GRAYSCALE);
cv::Mat img2 = cv::imread("image2.jpg", cv::IMREAD_GRAYSCALE);
if (img1.empty() || img2.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// ORB検出器の作成
cv::Ptr<cv::ORB> orb = cv::ORB::create();
std::vector<cv::KeyPoint> keypoints1, keypoints2;
cv::Mat descriptors1, descriptors2;
orb->detectAndCompute(img1, cv::noArray(), keypoints1, descriptors1);
orb->detectAndCompute(img2, cv::noArray(), keypoints2, descriptors2);
// Brute-Force Matcher (Hamming距離)
cv::BFMatcher bfMatcher(cv::NORM_HAMMING);
std::vector<cv::DMatch> bfMatches;
bfMatcher.match(descriptors1, descriptors2, bfMatches);
// FLANN Matcherの設定(バイナリ記述子用)
cv::Ptr<cv::DescriptorMatcher> flannMatcher = cv::DescriptorMatcher::create(cv::DescriptorMatcher::FLANNBASED);
std::vector<cv::DMatch> flannMatches;
// FLANNはバイナリ記述子に直接使えないため、float型に変換が必要
cv::Mat descriptors1_float, descriptors2_float;
descriptors1.convertTo(descriptors1_float, CV_32F);
descriptors2.convertTo(descriptors2_float, CV_32F);
flannMatcher->match(descriptors1_float, descriptors2_float, flannMatches);
// マッチ結果を描画
cv::Mat imgMatchesBF, imgMatchesFLANN;
cv::drawMatches(img1, keypoints1, img2, keypoints2, bfMatches, imgMatchesBF);
cv::drawMatches(img1, keypoints1, img2, keypoints2, flannMatches, imgMatchesFLANN);
cv::imshow("BFMatcher Matches", imgMatchesBF);
cv::imshow("FLANN Matcher Matches", imgMatchesFLANN);
cv::waitKey(0);
return 0;
}(ウィンドウにBFMatcherとFLANN Matcherのマッチング結果が表示される)- BFMatcherは単純で安定していますが、特徴点数が多いと遅くなります
- FLANNは高速ですが、バイナリ記述子の場合はfloat型に変換するなどの工夫が必要です
RANSACでの外れ値除去
特徴点マッチングでは誤った対応(外れ値)が含まれることが多く、これを除去するためにRANSAC(Random Sample Consensus)アルゴリズムが使われます。
RANSACは複数のマッチから正しい対応点の集合(インライア)を推定し、外れ値を排除します。
OpenCVではcv::findHomography関数の引数にcv::RANSACを指定して利用します。
ホモグラフィ行列を推定しつつ、外れ値を除去できます。
以下はRANSACを使った外れ値除去の例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat img1 = cv::imread("image1.jpg", cv::IMREAD_GRAYSCALE);
cv::Mat img2 = cv::imread("image2.jpg", cv::IMREAD_GRAYSCALE);
if (img1.empty() || img2.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Ptr<cv::ORB> orb = cv::ORB::create();
std::vector<cv::KeyPoint> keypoints1, keypoints2;
cv::Mat descriptors1, descriptors2;
orb->detectAndCompute(img1, cv::noArray(), keypoints1, descriptors1);
orb->detectAndCompute(img2, cv::noArray(), keypoints2, descriptors2);
cv::BFMatcher bfMatcher(cv::NORM_HAMMING);
std::vector<cv::DMatch> matches;
bfMatcher.match(descriptors1, descriptors2, matches);
// マッチから対応点を抽出
std::vector<cv::Point2f> points1, points2;
for (const auto& match : matches) {
points1.push_back(keypoints1[match.queryIdx].pt);
points2.push_back(keypoints2[match.trainIdx].pt);
}
// RANSACでホモグラフィ行列を推定し、外れ値を除去
std::vector<uchar> inliersMask(points1.size());
cv::Mat homography = cv::findHomography(points1, points2, cv::RANSAC, 3.0, inliersMask);
// インライアのみ抽出
std::vector<cv::DMatch> inlierMatches;
for (size_t i = 0; i < matches.size(); i++) {
if (inliersMask[i]) {
inlierMatches.push_back(matches[i]);
}
}
cv::Mat imgInliers;
cv::drawMatches(img1, keypoints1, img2, keypoints2, inlierMatches, imgInliers);
cv::imshow("Inlier Matches after RANSAC", imgInliers);
cv::waitKey(0);
return 0;
}(ウィンドウにRANSACで外れ値除去後のマッチング結果が表示される)RANSACを使うことで、誤ったマッチを除外し、より正確な対応点を得られます。
これにより、画像の位置合わせや3D再構築の精度が向上します。
これらの特徴マッチング技術を組み合わせて使うことで、堅牢で高速な画像対応点検出が可能になります。
用途や環境に応じて特徴量やマッチャー、外れ値除去手法を選択してください。
カメラキャリブレーション
チェッカーボードパターン検出
カメラキャリブレーションの第一歩は、既知のパターン(一般的にはチェッカーボード)を撮影し、そのパターンのコーナー点を正確に検出することです。
OpenCVではcv::findChessboardCorners関数を使ってチェッカーボードの内側の交点(コーナー)を検出します。
チェッカーボードのサイズは、内側の交点の数(行数×列数)で指定します。
例えば、9×6のチェッカーボードなら、9列6行の交点を検出します。
以下はチェッカーボードのコーナー検出の例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat image = cv::imread("checkerboard.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// チェッカーボードの内側コーナー数(列×行)
cv::Size patternSize(9, 6);
std::vector<cv::Point2f> corners;
bool found = cv::findChessboardCorners(image, patternSize, corners,
cv::CALIB_CB_ADAPTIVE_THRESH | cv::CALIB_CB_NORMALIZE_IMAGE);
if (found) {
// コーナーのサブピクセル精度化
cv::Mat gray;
cv::cvtColor(image, gray, cv::COLOR_BGR2GRAY);
cv::cornerSubPix(gray, corners, cv::Size(11, 11), cv::Size(-1, -1),
cv::TermCriteria(cv::TermCriteria::EPS + cv::TermCriteria::MAX_ITER, 30, 0.1));
// 検出したコーナーを描画
cv::drawChessboardCorners(image, patternSize, corners, found);
cv::imshow("Detected Corners", image);
cv::waitKey(0);
} else {
std::cerr << "チェッカーボードのコーナーが検出できませんでした。" << std::endl;
}
return 0;
}(ウィンドウにチェッカーボードのコーナーが赤い点で描画された画像が表示される)findChessboardCornersは画像の明暗やノイズに強いアルゴリズムで、CALIB_CB_ADAPTIVE_THRESHやCALIB_CB_NORMALIZE_IMAGEなどのフラグを組み合わせて検出精度を高めます。
検出後はcornerSubPixでコーナー位置をサブピクセル単位で補正し、より正確な位置を得ます。
内部パラメータ推定
チェッカーボードの複数枚の画像から、カメラの内部パラメータ(焦点距離、主点、歪み係数など)を推定します。
これにより、カメラのレンズ特性を数値化し、画像の歪み補正や3D計測に利用可能になります。
内部パラメータ推定には、チェッカーボードの実際の物理的なサイズ(正方形の一辺の長さ)と、検出したコーナーの画像座標を使います。
以下は複数画像から内部パラメータを推定する例です。
#include <opencv2/opencv.hpp>
#include <iostream>
#include <vector>
int main() {
// チェッカーボードの内側コーナー数
cv::Size patternSize(9, 6);
float squareSize = 25.0f; // 正方形の一辺の長さ(mmなど)
// 3Dのチェッカーボードのコーナー座標(Z=0の平面)
std::vector<cv::Point3f> objectCorners;
for (int i = 0; i < patternSize.height; i++) {
for (int j = 0; j < patternSize.width; j++) {
objectCorners.emplace_back(j * squareSize, i * squareSize, 0);
}
}
std::vector<std::vector<cv::Point3f>> objectPoints; // 3D点群(複数画像分)
std::vector<std::vector<cv::Point2f>> imagePoints; // 2D画像点群
std::vector<std::string> imageFiles = {
"calib1.jpg", "calib2.jpg", "calib3.jpg", // キャリブレーション画像のパス
// ... 必要な枚数を追加
};
for (const auto& file : imageFiles) {
cv::Mat image = cv::imread(file);
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました: " << file << std::endl;
continue;
}
std::vector<cv::Point2f> corners;
bool found = cv::findChessboardCorners(image, patternSize, corners);
if (found) {
cv::Mat gray;
cv::cvtColor(image, gray, cv::COLOR_BGR2GRAY);
cv::cornerSubPix(gray, corners, cv::Size(11, 11), cv::Size(-1, -1),
cv::TermCriteria(cv::TermCriteria::EPS + cv::TermCriteria::MAX_ITER, 30, 0.1));
imagePoints.push_back(corners);
objectPoints.push_back(objectCorners);
cv::drawChessboardCorners(image, patternSize, corners, found);
cv::imshow("Calibration", image);
cv::waitKey(100);
} else {
std::cerr << "チェッカーボードのコーナーが検出できませんでした: " << file << std::endl;
}
}
cv::destroyAllWindows();
cv::Mat cameraMatrix, distCoeffs;
std::vector<cv::Mat> rvecs, tvecs;
// キャリブレーション実行
double rms = cv::calibrateCamera(objectPoints, imagePoints, cv::Size(640, 480),
cameraMatrix, distCoeffs, rvecs, tvecs);
std::cout << "キャリブレーション完了 RMS誤差: " << rms << std::endl;
std::cout << "カメラ行列:\n" << cameraMatrix << std::endl;
std::cout << "歪み係数:\n" << distCoeffs << std::endl;
return 0;
}キャリブレーション完了 RMS誤差: 0.25
カメラ行列:
[fx, 0, cx;
0, fy, cy;
0, 0, 1]
歪み係数:
[k1, k2, p1, p2, k3]cameraMatrixは焦点距離(fx, fy)と主点(cx, cy)を含む3×3の内部パラメータ行列ですdistCoeffsはレンズの歪み係数(ラジアル歪みk1,k2,k3とタンジェンシャル歪みp1,p2)を表しますrvecsとtvecsは各画像の回転ベクトルと並進ベクトルで、カメラの姿勢を示します
複数枚の画像で精度を高めることが重要です。
歪み補正と画像リマップ
キャリブレーションで得た内部パラメータと歪み係数を使い、画像の歪み補正を行います。
OpenCVではcv::initUndistortRectifyMapで補正用のマップを作成し、cv::remapで画像をリマップ(再配置)します。
以下は歪み補正の例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 事前にキャリブレーションで得たパラメータを設定
cv::Mat cameraMatrix = (cv::Mat_<double>(3, 3) << 800, 0, 320,
0, 800, 240,
0, 0, 1);
cv::Mat distCoeffs = (cv::Mat_<double>(1, 5) << -0.2, 0.1, 0, 0, 0);
cv::Mat distorted = cv::imread("distorted.jpg");
if (distorted.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat map1, map2;
cv::Size imageSize = distorted.size();
// 補正用マップを作成
cv::initUndistortRectifyMap(cameraMatrix, distCoeffs, cv::Mat(),
cameraMatrix, imageSize, CV_16SC2, map1, map2);
cv::Mat undistorted;
// リマップして歪み補正
cv::remap(distorted, undistorted, map1, map2, cv::INTER_LINEAR);
cv::imshow("Distorted Image", distorted);
cv::imshow("Undistorted Image", undistorted);
cv::waitKey(0);
return 0;
}(ウィンドウに歪んだ画像と補正後の画像が表示される)initUndistortRectifyMapは歪み補正と画像の整列を行うためのマップを生成しますremapはマップに従って画素を再配置し、歪みのない画像を生成します
この処理により、レンズの歪みによる画像の歪みを補正し、正確な計測や画像解析が可能になります。
これらの手順を通じて、カメラの内部パラメータを正確に推定し、歪み補正を行うことで、画像処理やコンピュータビジョンの精度を大幅に向上させられます。
動体検知と追跡
背景差分法による前景抽出
背景差分法は動画や連続画像から動いている物体(前景)を検出する基本的な手法です。
背景画像と現在のフレームの差分を計算し、差分が大きい部分を前景として抽出します。
OpenCVでは背景差分のためのクラスが用意されており、代表的なものにcv::BackgroundSubtractorMOG2やcv::BackgroundSubtractorKNNがあります。
以下はBackgroundSubtractorMOG2を使った前景抽出の例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::VideoCapture cap(0); // カメラを開く
if (!cap.isOpened()) {
std::cerr << "カメラが開けません" << std::endl;
return -1;
}
cv::Ptr<cv::BackgroundSubtractor> pBackSub = cv::createBackgroundSubtractorMOG2();
cv::Mat frame, fgMask;
while (true) {
cap >> frame;
if (frame.empty()) break;
// 背景差分を計算し前景マスクを取得
pBackSub->apply(frame, fgMask);
// ノイズ除去のためにモルフォロジー処理(膨張)
cv::dilate(fgMask, fgMask, cv::Mat(), cv::Point(-1, -1), 2);
cv::imshow("Frame", frame);
cv::imshow("Foreground Mask", fgMask);
if (cv::waitKey(30) >= 0) break;
}
return 0;
}(カメラ映像と動体部分が白く抽出された前景マスクが表示される)BackgroundSubtractorMOG2はガウス混合モデルを用いて背景を動的に学習し、照明変化や背景の揺らぎに強い特徴があります。
前景マスクは二値画像で、動いている物体の領域が白くなります。
Lucas -Kanadeオプティカルフロー
オプティカルフローは連続するフレーム間で画素の動きを推定する技術です。
Lucas -Kanade法は局所的な勾配情報を使い、特徴点の動きを高速かつ精度良く計算します。
OpenCVのcv::calcOpticalFlowPyrLK関数で実装され、特徴点の追跡に広く使われています。
以下はカメラ映像から特徴点を検出し、Lucas -Kanade法で追跡する例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::VideoCapture cap(0);
if (!cap.isOpened()) {
std::cerr << "カメラが開けません" << std::endl;
return -1;
}
cv::Mat prevFrame, prevGray;
cap >> prevFrame;
cv::cvtColor(prevFrame, prevGray, cv::COLOR_BGR2GRAY);
// 特徴点を検出
std::vector<cv::Point2f> prevPoints;
cv::goodFeaturesToTrack(prevGray, prevPoints, 100, 0.3, 7);
while (true) {
cv::Mat frame, gray;
cap >> frame;
if (frame.empty()) break;
cv::cvtColor(frame, gray, cv::COLOR_BGR2GRAY);
std::vector<cv::Point2f> nextPoints;
std::vector<uchar> status;
std::vector<float> err;
// オプティカルフローを計算
cv::calcOpticalFlowPyrLK(prevGray, gray, prevPoints, nextPoints, status, err);
// 動きを線と円で描画
for (size_t i = 0; i < nextPoints.size(); i++) {
if (status[i]) {
cv::line(frame, prevPoints[i], nextPoints[i], cv::Scalar(0, 255, 0), 2);
cv::circle(frame, nextPoints[i], 5, cv::Scalar(0, 0, 255), -1);
}
}
cv::imshow("Optical Flow", frame);
prevGray = gray.clone();
prevPoints = nextPoints;
if (cv::waitKey(30) >= 0) break;
}
return 0;
}(カメラ映像上に特徴点の動きが緑の線と赤い円で表示される)Lucas -Kanade法は小さな動きの追跡に適しており、特徴点の選択やパラメータ調整で追跡精度が変わります。
多目標追跡の戦略
複数の動く物体を同時に追跡する多目標追跡(Multi-Object Tracking, MOT)は、監視カメラや自動運転などで重要な技術です。
単純なオプティカルフローだけでは物体の識別や追跡の継続が難しいため、以下のような戦略が使われます。
- 検出と追跡の組み合わせ
物体検出器(例:YOLO、SSD)で毎フレーム物体を検出し、追跡器(例:Kalmanフィルタ、SORT)で検出結果を連続的に追跡します。
- 特徴量による識別
各物体の外観特徴(色、形状、特徴点など)を用いて、追跡対象のIDを維持します。
- データアソシエーション
新しい検出と既存の追跡対象をマッチングするために、距離や外観類似度を計算し、最適な対応付けを行います。
OpenCV単体では高度なMOT機能は限定的ですが、Kalmanフィルタやオプティカルフローを組み合わせて簡易的な追跡は可能です。
以下はKalmanフィルタを使った単純な追跡のイメージコードです。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// Kalmanフィルタの初期化(状態:位置と速度)
cv::KalmanFilter kf(4, 2, 0);
kf.transitionMatrix = (cv::Mat_<float>(4, 4) <<
1, 0, 1, 0,
0, 1, 0, 1,
0, 0, 1, 0,
0, 0, 0, 1);
cv::setIdentity(kf.measurementMatrix);
cv::setIdentity(kf.processNoiseCov, cv::Scalar::all(1e-4));
cv::setIdentity(kf.measurementNoiseCov, cv::Scalar::all(1e-1));
cv::setIdentity(kf.errorCovPost, cv::Scalar::all(1));
cv::Mat measurement(2, 1, CV_32F);
measurement.setTo(cv::Scalar(0));
cv::VideoCapture cap(0);
if (!cap.isOpened()) {
std::cerr << "カメラが開けません" << std::endl;
return -1;
}
cv::Mat frame;
bool initialized = false;
while (true) {
cap >> frame;
if (frame.empty()) break;
// ここでは単純に赤い物体の重心を検出する例(実際は物体検出器を使う)
cv::Mat hsv, mask;
cv::cvtColor(frame, hsv, cv::COLOR_BGR2HSV);
cv::inRange(hsv, cv::Scalar(0, 100, 100), cv::Scalar(10, 255, 255), mask);
std::vector<std::vector<cv::Point>> contours;
cv::findContours(mask, contours, cv::RETR_EXTERNAL, cv::CHAIN_APPROX_SIMPLE);
if (!contours.empty()) {
// 最大輪郭の重心を計算
size_t maxIdx = 0;
double maxArea = 0;
for (size_t i = 0; i < contours.size(); i++) {
double area = cv::contourArea(contours[i]);
if (area > maxArea) {
maxArea = area;
maxIdx = i;
}
}
cv::Moments m = cv::moments(contours[maxIdx]);
cv::Point2f center(m.m10 / m.m00, m.m01 / m.m00);
measurement.at<float>(0) = center.x;
measurement.at<float>(1) = center.y;
if (!initialized) {
// 初期状態設定
kf.statePost.at<float>(0) = center.x;
kf.statePost.at<float>(1) = center.y;
kf.statePost.at<float>(2) = 0;
kf.statePost.at<float>(3) = 0;
initialized = true;
} else {
// Kalmanフィルタ更新
kf.correct(measurement);
}
}
// 状態予測
cv::Mat prediction = kf.predict();
cv::Point2f predictPt(prediction.at<float>(0), prediction.at<float>(1));
// 予測位置を描画
cv::circle(frame, predictPt, 10, cv::Scalar(255, 0, 0), 2);
cv::imshow("Tracking", frame);
if (cv::waitKey(30) >= 0) break;
}
return 0;
}(カメラ映像上に青い円で予測位置が表示される)多目標追跡では、複数のKalmanフィルタや外観特徴を組み合わせ、ID管理や追跡の継続性を確保します。
高度なMOTには専用ライブラリやディープラーニング技術の活用も検討してください。
これらの技術を組み合わせることで、動く物体の検出から追跡までを効率的に実現できます。
用途に応じて背景差分、オプティカルフロー、追跡アルゴリズムを適切に選択してください。
物体検出
CascadeClassifierによる顔検出
OpenCVのCascadeClassifierはHaar特徴やLBP特徴を用いた物体検出器で、特に顔検出に広く使われています。
事前に学習された分類器(XMLファイル)を読み込み、画像中の顔領域を高速に検出します。
カスケード分類器の利用にはカスケードファイルが必要です。
OpenCVをインストールすると、多くの環境ではhaarcascade_frontalface_default.xmlファイルが自動的に含まれています。以下のようなパスに存在することが多いです。
/usr/share/opencv4/haarcascades/haarcascade_frontalface_default.xmlopencv\sources\data\haarcascades\haarcascade_frontalface_default.xmlカスケードファイルをコピーしてカレントディレクトリに配置するなどをして、使える状態にしておきましょう。
以下はHaar分類器を使った顔検出のサンプルコードです。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat image = cv::imread("group_photo.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// Haar分類器の読み込み(OpenCV付属の顔検出用XML)
cv::CascadeClassifier faceCascade;
if (!faceCascade.load("haarcascade_frontalface_default.xml")) {
std::cerr << "分類器の読み込みに失敗しました。" << std::endl;
return -1;
}
std::vector<cv::Rect> faces;
cv::Mat gray;
cv::cvtColor(image, gray, cv::COLOR_BGR2GRAY);
cv::equalizeHist(gray, gray); // コントラスト強調
// 顔検出
faceCascade.detectMultiScale(gray, faces, 1.1, 3, 0, cv::Size(30, 30));
// 検出結果を描画
for (const auto& face : faces) {
cv::rectangle(image, face, cv::Scalar(0, 255, 0), 2);
}
cv::imshow("Detected Faces", image);
cv::waitKey(0);
return 0;
}(ウィンドウに顔が緑色の矩形で囲まれた画像が表示される)detectMultiScaleのパラメータは、スケールファクター(1.1)、最小近傍数(3)、検出フラグ、最小サイズを指定します- 顔検出はグレースケール画像で行い、
equalizeHistで明暗差を均一化すると精度が向上します
CascadeClassifierは高速でリアルタイム処理に適していますが、複雑な背景や多様な角度の顔には検出精度が落ちることがあります。
HOG+SVMの歩行者検出
歩行者検出には、HOG(Histogram of Oriented Gradients)特徴量とSVM(Support Vector Machine)を組み合わせた手法が古典的かつ効果的です。
OpenCVはcv::HOGDescriptorに歩行者検出用の事前学習済みSVMを搭載しており、簡単に利用できます。
以下はHOG+SVMによる歩行者検出の例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat image = cv::imread("pedestrians.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::HOGDescriptor hog;
hog.setSVMDetector(cv::HOGDescriptor::getDefaultPeopleDetector());
std::vector<cv::Rect> detections;
std::vector<double> weights;
// 歩行者検出
hog.detectMultiScale(image, detections, weights);
// 検出結果を描画
for (size_t i = 0; i < detections.size(); i++) {
cv::rectangle(image, detections[i], cv::Scalar(0, 0, 255), 2);
std::string score = cv::format("%.2f", weights[i]);
cv::putText(image, score, detections[i].tl(), cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(255, 0, 0), 1);
}
cv::imshow("Pedestrian Detection", image);
cv::waitKey(0);
return 0;
}(ウィンドウに歩行者が赤い矩形で囲まれ、信頼度スコアが表示される)detectMultiScaleは画像中の歩行者候補を検出し、矩形領域と信頼度を返します- HOG特徴量は局所的な勾配方向の分布を表現し、歩行者の形状を効果的に捉えます
HOG+SVMは比較的高速で、監視カメラ映像などで広く使われていますが、複雑な背景や小さい歩行者には検出が難しい場合があります。
DNNモジュールでのYOLO推論
近年の物体検出では、深層学習(DNN)を用いた手法が主流です。
OpenCVのDNNモジュールはYOLO(You Only Look Once)などの高速かつ高精度な物体検出モデルをサポートしています。
YOLOは画像をグリッドに分割し、一度の推論で複数の物体を検出するリアルタイム対応の検出器です。
以下はYOLOv3を使った物体検出の例です。
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <iostream>
#include <fstream>
int main() {
// モデルの構成ファイルと重みファイルのパス
std::string modelConfiguration = "yolov3.cfg";
std::string modelWeights = "yolov3.weights";
std::string classesFile = "coco.names";
// クラス名の読み込み
std::vector<std::string> classes;
std::ifstream ifs(classesFile.c_str());
std::string line;
while (std::getline(ifs, line)) classes.push_back(line);
// ネットワークの読み込み
cv::dnn::Net net = cv::dnn::readNetFromDarknet(modelConfiguration, modelWeights);
net.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);
cv::Mat image = cv::imread("street.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// 入力画像の前処理
cv::Mat blob;
cv::dnn::blobFromImage(image, blob, 1/255.0, cv::Size(416, 416), cv::Scalar(), true, false);
net.setInput(blob);
// 出力レイヤー名の取得
std::vector<cv::String> outNames = net.getUnconnectedOutLayersNames();
std::vector<cv::Mat> outs;
// 推論実行
net.forward(outs, outNames);
float confThreshold = 0.5;
float nmsThreshold = 0.4;
std::vector<int> classIds;
std::vector<float> confidences;
std::vector<cv::Rect> boxes;
int width = image.cols;
int height = image.rows;
// 出力結果の解析
for (size_t i = 0; i < outs.size(); ++i) {
float* data = (float*)outs[i].data;
for (int j = 0; j < outs[i].rows; ++j, data += outs[i].cols) {
cv::Mat scores = outs[i].row(j).colRange(5, outs[i].cols);
cv::Point classIdPoint;
double confidence;
cv::minMaxLoc(scores, 0, &confidence, 0, &classIdPoint);
if (confidence > confThreshold) {
int centerX = (int)(data[0] * width);
int centerY = (int)(data[1] * height);
int boxWidth = (int)(data[2] * width);
int boxHeight = (int)(data[3] * height);
int left = centerX - boxWidth / 2;
int top = centerY - boxHeight / 2;
classIds.push_back(classIdPoint.x);
confidences.push_back((float)confidence);
boxes.push_back(cv::Rect(left, top, boxWidth, boxHeight));
}
}
}
// 非最大抑制で重複検出を削減
std::vector<int> indices;
cv::dnn::NMSBoxes(boxes, confidences, confThreshold, nmsThreshold, indices);
for (int idx : indices) {
cv::Rect box = boxes[idx];
cv::rectangle(image, box, cv::Scalar(0, 255, 0), 2);
std::string label = cv::format("%.2f", confidences[idx]);
if (!classes.empty()) {
label = classes[classIds[idx]] + ": " + label;
}
int baseLine;
cv::Size labelSize = cv::getTextSize(label, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
int top = std::max(box.y, labelSize.height);
cv::rectangle(image, cv::Point(box.x, top - labelSize.height),
cv::Point(box.x + labelSize.width, top + baseLine), cv::Scalar::all(255), cv::FILLED);
cv::putText(image, label, cv::Point(box.x, top), cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar());
}
cv::imshow("YOLO Object Detection", image);
cv::waitKey(0);
return 0;
}(ウィンドウに検出された物体が緑色の矩形とラベル付きで表示される)- YOLOは高速かつ高精度な物体検出が可能で、リアルタイムアプリケーションに適しています
blobFromImageで画像を正規化・リサイズし、ネットワークに入力します- 出力は複数の検出候補で、信頼度の閾値と非最大抑制(NMS)で最終的な検出結果を絞り込みます
OpenCVのDNNモジュールはTensorFlowやCaffeなどの他のモデルもサポートしており、用途に応じて使い分けが可能です。
これらの物体検出手法を使い分けることで、用途や環境に応じた最適な検出システムを構築できます。
軽量で高速なCascadeClassifier、古典的で安定したHOG+SVM、そして高精度なYOLOなど、目的に合わせて選択してください。
GPUアクセラレーション
cv::cuda::GpuMatの基本操作
OpenCVのCUDAモジュールはGPUを活用した高速な画像処理を可能にします。
その中心的なデータ構造がcv::cuda::GpuMatです。
GpuMatはCPUのcv::Matと似ていますが、画像データがGPUメモリ上に格納されている点が異なります。
GpuMatの基本操作は以下の通りです。
- 作成
CPUのcv::MatからGPUにデータを転送してGpuMatを作成できます。
また、GPU上で新規にメモリを確保することも可能です。
- データ転送
upload()でCPUからGPUへ、download()でGPUからCPUへデータを転送します。
- 演算
CUDA対応のOpenCV関数はGpuMatを引数に取り、GPU上で処理を行います。
以下はGpuMatの基本的な使い方の例です。
#include <opencv2/opencv.hpp>
#include <opencv2/cudaimgproc.hpp>
#include <iostream>
int main() {
cv::Mat cpuImage = cv::imread("image.jpg", cv::IMREAD_GRAYSCALE);
if (cpuImage.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// GpuMatの作成とCPUからGPUへのアップロード
cv::cuda::GpuMat gpuImage;
gpuImage.upload(cpuImage);
// GPU上でガウシアンブラーを適用
cv::cuda::GpuMat gpuBlurred;
cv::cuda::GaussianBlur(gpuImage, gpuBlurred, cv::Size(7, 7), 1.5);
// 結果をCPUにダウンロード
cv::Mat blurred;
gpuBlurred.download(blurred);
cv::imshow("Original", cpuImage);
cv::imshow("Blurred (GPU)", blurred);
cv::waitKey(0);
return 0;
}(ウィンドウに元画像とGPUで処理したぼかし画像が表示される)GpuMatはCPUのMatと似たAPIを持つため、GPU処理への移行が比較的容易です。
ただし、データ転送はコストが高いため、可能な限りGPU上で連続処理を行うことがパフォーマンス向上の鍵です。
CUDAカーネルとストリーム最適化
OpenCVのCUDAモジュールは多くの画像処理関数を提供しますが、より高度な処理や独自アルゴリズムを実装したい場合はCUDAカーネルを自作することも可能です。
CUDAカーネルはGPU上で並列に実行される関数で、細かい制御ができます。
また、CUDAストリームを使うことで複数の処理を非同期に実行し、GPUのリソースを効率的に活用できます。
ストリームを使うと、データ転送やカーネル実行を重ねて行い、待ち時間を減らせます。
以下はCUDAストリームを使ったOpenCVのGPU処理の例です。
#include <opencv2/opencv.hpp>
#include <opencv2/cudaimgproc.hpp>
#include <iostream>
int main() {
cv::Mat cpuImage = cv::imread("image.jpg", cv::IMREAD_GRAYSCALE);
if (cpuImage.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::cuda::GpuMat gpuImage, gpuBlurred;
cv::cuda::Stream stream;
// 非同期アップロード
gpuImage.upload(cpuImage, stream);
// 非同期ガウシアンブラー
cv::cuda::GaussianBlur(gpuImage, gpuBlurred, cv::Size(7, 7), 1.5, -1, stream);
// 非同期ダウンロード
cv::Mat blurred;
gpuBlurred.download(blurred, stream);
// ストリームの完了を待つ
stream.waitForCompletion();
cv::imshow("Original", cpuImage);
cv::imshow("Blurred (Async GPU)", blurred);
cv::waitKey(0);
return 0;
}(ウィンドウに元画像と非同期GPU処理でぼかした画像が表示される)cv::cuda::Streamを使うと、アップロード、処理、ダウンロードを非同期に実行可能です- 複数ストリームを使い分けることで、GPUの並列性を最大限に活かせます
CUDAカーネルの自作はCUDA C++の知識が必要ですが、OpenCVのGPUモジュールと組み合わせることで高度な高速処理が実現できます。
OpenCL/T-APIによる自動デバイス選択
OpenCVはCUDA以外にもOpenCLを利用したGPUアクセラレーションをサポートしています。
OpenCLはクロスプラットフォームな並列計算APIで、NVIDIA以外のGPUやCPUでも動作します。
OpenCVのT-API(Transparent API)は、OpenCLを利用して自動的に最適なデバイス(CPU/GPU)を選択し、処理を高速化します。
ユーザーは通常のcv::Matを使いながら、裏でOpenCLが有効な場合はGPU処理が行われます。
T-APIを使うには、cv::UMatを使います。
UMatはCPUとGPU間のデータ管理を自動化し、OpenCL対応デバイスで高速処理を実現します。
以下はUMatを使った例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat cpuImage = cv::imread("image.jpg", cv::IMREAD_GRAYSCALE);
if (cpuImage.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// UMatに変換(OpenCL対応デバイスがあればGPU処理される)
cv::UMat uImage;
cpuImage.copyTo(uImage);
cv::UMat uBlurred;
cv::GaussianBlur(uImage, uBlurred, cv::Size(7, 7), 1.5);
// UMatからMatに変換して表示
cv::Mat blurred = uBlurred.getMat(cv::ACCESS_READ);
cv::imshow("Original", cpuImage);
cv::imshow("Blurred (T-API)", blurred);
cv::waitKey(0);
return 0;
}(ウィンドウに元画像とT-APIでぼかした画像が表示される)UMatを使うだけで、OpenCL対応環境では自動的にGPU処理が行われます- CUDAが使えない環境でも、OpenCL対応GPUやCPUで高速化が期待できます
OpenCVのT-APIはコードの互換性を保ちつつ、環境に応じた最適なデバイスを選択するため、移植性の高いGPUアクセラレーション手法として有効です。
これらのGPUアクセラレーション技術を活用することで、画像処理の高速化が可能になります。
用途や環境に応じてcv::cuda::GpuMatやCUDAカーネル、OpenCLのT-APIを使い分けてください。
パフォーマンス最適化
マルチスレッドとTBBの併用
OpenCVはマルチスレッド処理を活用して高速化を図っています。
特にIntelのTBB(Threading Building Blocks)を利用することで、CPUの複数コアを効率的に使い、画像処理の並列化を実現しています。
OpenCVの多くの関数は内部でTBBを利用しており、ユーザーが明示的にスレッド管理を行わなくても自動的に並列処理されます。
ただし、独自の処理を並列化したい場合はTBBのAPIを直接使うことも可能です。
以下はTBBのparallel_forを使って画像の画素値を2倍にする例です。
#include <opencv2/opencv.hpp>
#include <tbb/tbb.h>
#include <iostream>
int main() {
cv::Mat image = cv::imread("image.jpg", cv::IMREAD_GRAYSCALE);
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat result = image.clone();
// TBBのparallel_forで行単位に並列処理
tbb::parallel_for(0, image.rows, [&](int i) {
uchar* ptr = result.ptr<uchar>(i);
for (int j = 0; j < image.cols; j++) {
int val = ptr[j] * 2;
ptr[j] = (val > 255) ? 255 : val;
}
});
cv::imshow("Original", image);
cv::imshow("Doubled Brightness", result);
cv::waitKey(0);
return 0;
}(ウィンドウに元画像と明るさが2倍になった画像が表示される)- TBBはスレッドの生成・管理を自動化し、負荷分散も最適化します
- OpenCVのビルド時にTBBを有効にすると、多くの関数で自動的に並列化されます
- 独自処理の並列化にはTBBの
parallel_forやparallel_reduceが便利です
マルチスレッド化によりCPUの性能を最大限に活かし、処理時間を大幅に短縮できます。
SIMDとIPP活用による高速化
SIMD(Single Instruction Multiple Data)は、CPUのベクトル命令を使って複数のデータを同時に処理する技術です。
IntelのIPP(Integrated Performance Primitives)はSIMDを活用した高性能な画像処理ライブラリで、OpenCVはIPPを内部で利用して高速化しています。
OpenCVの関数はビルド時にIPPを有効にすると、対応する処理で自動的にIPPの最適化コードが使われます。
これにより、ループ展開やSIMD命令による並列処理が行われ、処理速度が向上します。
以下はIPPが有効な環境での高速化のポイントです。
- ビルド設定
OpenCVをビルドする際にWITH_IPP=ONを指定し、IPPライブラリをリンクします。
- 関数の自動最適化
画像のフィルタリング、変換、特徴量計算など多くの関数でIPPが利用されます。
- SIMD命令セット
SSE、AVX、AVX2、AVX-512などCPUの命令セットに応じて最適化されます。
ユーザーが特別なコードを書かなくても、IPP対応のOpenCVを使うだけで高速化が期待できます。
プロファイリングでのボトルネック解析
パフォーマンス最適化の第一歩は、どの処理がボトルネックになっているかを特定することです。
プロファイリングツールを使うことで、関数ごとの実行時間やCPU使用率、メモリアクセス状況を詳細に解析できます。
代表的なプロファイリングツールは以下の通りです。
| ツール名 | 対応環境 | 特徴 |
|---|---|---|
| Visual Studio Profiler | Windows | GUIで使いやすく、CPU・GPU両方の解析が可能 |
| Intel VTune Profiler | Windows/Linux | 詳細なCPUパフォーマンス解析、SIMD解析対応 |
| Linux perf | Linux | コマンドラインベースの軽量プロファイラ |
| NVIDIA Nsight | Windows/Linux | CUDA GPUの詳細解析に特化 |
OpenCVのコードをプロファイリングする際は、以下のポイントに注意します。
- ホットスポットの特定
実行時間が長い関数やループを特定し、最適化対象を絞ります。
- メモリアクセスの解析
キャッシュミスやメモリ帯域のボトルネックを検出。
- スレッドの負荷分散
マルチスレッド処理でスレッド間の負荷が偏っていないか確認。
- GPU利用状況
CUDAカーネルの実行時間やメモリ転送のオーバーヘッドを測定。
以下は簡単なC++コードで処理時間を計測する例です。
#include <opencv2/opencv.hpp>
#include <iostream>
#include <chrono>
int main() {
cv::Mat image = cv::imread("image.jpg", cv::IMREAD_GRAYSCALE);
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
auto start = std::chrono::high_resolution_clock::now();
cv::Mat blurred;
cv::GaussianBlur(image, blurred, cv::Size(7, 7), 1.5);
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> elapsed = end - start;
std::cout << "GaussianBlurの処理時間: " << elapsed.count() << " ms" << std::endl;
return 0;
}GaussianBlurの処理時間: 12.3456 msこのように処理時間を計測し、プロファイラと組み合わせて最適化ポイントを見つけてください。
これらのパフォーマンス最適化手法を組み合わせることで、OpenCVを使った画像処理アプリケーションの高速化が可能になります。
マルチスレッドやSIMD、IPPの活用、そしてプロファイリングによるボトルネック解析を積極的に行い、効率的な開発を目指しましょう。
デバッグとテスト
サニタイザでのメモリリーク検出
C++でOpenCVを使った開発では、メモリリークや未初期化メモリの使用がバグの原因となることがあります。
これらを検出するために、サニタイザ(Sanitizer)を活用すると効果的です。
代表的なサニタイザには、AddressSanitizer(ASan)やMemorySanitizer(MSan)があります。
AddressSanitizer(ASan)
ASanはメモリの不正アクセスやリークを検出するツールで、GCCやClangで簡単に有効化できます。
OpenCVのコードでも、ビルド時に以下のフラグを追加するだけで利用可能です。
g++ -fsanitize=address -g your_code.cpp -o your_program `pkg-config --cflags --libs opencv4`実行すると、メモリリークやバッファオーバーフローが検出された場合に詳細なレポートが表示されます。
以下はASanを使った簡単な例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 故意にメモリリークを発生させる例
int* leak = new int[10];
cv::Mat image = cv::imread("image.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// ここでdelete[] leak; を忘れているためリークが発生
std::cout << "プログラム終了" << std::endl;
return 0;
}ASanを有効にして実行すると、リークの場所やスタックトレースが表示され、原因特定が容易になります。
GoogleTestによるユニットテスト
品質の高いソフトウェア開発にはユニットテストが不可欠です。
GoogleTestはC++向けのテストフレームワークで、OpenCVの機能を含むコードの単体テストを簡単に作成・実行できます。
以下はGoogleTestを使ったOpenCV関数のテスト例です。
#include <gtest/gtest.h>
#include <opencv2/opencv.hpp>
// テスト対象関数(例:画像のサイズを返す)
int getImageWidth(const cv::Mat& img) {
return img.cols;
}
// テストケース
TEST(OpenCVTest, ImageWidthTest) {
cv::Mat img = cv::Mat::zeros(100, 200, CV_8UC3);
EXPECT_EQ(getImageWidth(img), 200);
}
int main(int argc, char **argv) {
::testing::InitGoogleTest(&argc, argv);
return RUN_ALL_TESTS();
}[==========] Running 1 test from 1 test suite.
[----------] Global test environment set-up.
[----------] 1 test from OpenCVTest
[ RUN ] OpenCVTest.ImageWidthTest
[ OK ] OpenCVTest.ImageWidthTest (0 ms)
[----------] 1 test from OpenCVTest (0 ms total)
[----------] Global test environment tear-down
[==========] 1 test from 1 test suite ran. (0 ms total)
[ PASSED ] 1 test.EXPECT_EQなどのマクロで期待値と実際の値を比較します- 複雑な画像処理関数の入出力を検証し、リグレッションを防止できます
- CMakeやビルドシステムにGoogleTestを組み込むことで自動化が容易です
CI環境での画像差分チェック
継続的インテグレーション(CI)環境で画像処理の品質を保つために、画像差分チェックを行うことが有効です。
これは、処理結果の画像を基準画像と比較し、差分が閾値以下かを判定してテストの合否を決める方法です。
OpenCVのcv::absdiffやcv::normを使って差分を計算し、差分画像の最大値や平均値を評価します。
以下は画像差分チェックの例です。
#include <opencv2/opencv.hpp>
#include <iostream>
bool compareImages(const cv::Mat& img1, const cv::Mat& img2, double threshold) {
if (img1.size() != img2.size() || img1.type() != img2.type()) {
std::cerr << "画像サイズまたは型が異なります。" << std::endl;
return false;
}
cv::Mat diff;
cv::absdiff(img1, img2, diff);
double maxDiff = 0.0;
if (diff.channels() == 1) {
maxDiff = cv::norm(diff, cv::NORM_INF);
} else {
std::vector<cv::Mat> channels;
cv::split(diff, channels);
for (const auto& ch : channels) {
double chMax = cv::norm(ch, cv::NORM_INF);
if (chMax > maxDiff) maxDiff = chMax;
}
}
std::cout << "最大差分値: " << maxDiff << std::endl;
return maxDiff <= threshold;
}
int main() {
cv::Mat baseline = cv::imread("baseline.png");
cv::Mat test = cv::imread("test.png");
if (baseline.empty() || test.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
double threshold = 10.0; // 許容差分値
bool result = compareImages(baseline, test, threshold);
if (result) {
std::cout << "画像差分チェック合格" << std::endl;
} else {
std::cout << "画像差分チェック失敗" << std::endl;
}
return 0;
}最大差分値: 5.2
画像差分チェック合格- CI環境でテストを自動化し、画像処理の変更による影響を検出可能です
- 差分が大きい場合はビジュアルリグレッションとして警告を出し、品質維持に役立ちます
- 画像の前処理やノイズ除去を考慮し、適切な閾値設定が重要です
これらのデバッグ・テスト手法を活用して、OpenCVを使った画像処理アプリケーションの品質を高め、安定した開発を進めてください。
まとめ
本記事では、OpenCVを用いたC++画像処理の基礎から高度なテクニックまで幅広く解説しました。
cv::Matのメモリ管理や画像入出力、色空間変換、幾何変換、フィルタリング、エッジ検出、形態学的処理、特徴マッチング、カメラキャリブレーション、動体検知、物体検出、GPUアクセラレーション、パフォーマンス最適化、デバッグ・テストまで、多彩なテーマを網羅しています。
これらを理解し活用することで、高速かつ高精度な画像処理アプリケーションの開発が可能になります。