【C++】OpenCV初心者が最短で画像処理を習得する基本ステップとサンプルコード集
C++ OpenCV 初心者は、環境構築と画像をcv::Matで扱う感覚に慣れることが最初の壁です。
CMakeでビルドしimshowで結果を即確認できる流れを押さえれば、画素アクセス、色変換、フィルタ、輪郭抽出など主要APIを組み合わせるだけで多様な処理が作れます。
API名は英語ですが日本語資料も豊富なので、公式チュートリアルとサンプルを順に写経しながら小さな成果物を増やすのが習得の近道です。
OpenCVの役割とC++ API特徴
画像処理ライブラリとしての位置づけ
OpenCV(Open Source Computer Vision Library)は、画像処理やコンピュータビジョンの分野で広く使われているオープンソースのライブラリです。
もともとはIntel社が開発を始め、その後オープンソース化されてからは世界中の開発者が参加して機能拡充が進んでいます。
画像の読み込みや表示、フィルタリング、特徴量抽出、物体検出、機械学習、深層学習の推論まで幅広い機能を備えているため、研究から実用アプリケーションまで多様な用途に対応しています。
特にC++での利用が推奨されており、高速な処理が求められるリアルタイム画像処理や組み込みシステムでの活用に適しています。
PythonやJavaなど他の言語バインディングもありますが、C++版は最も機能が充実しており、最新のAPIがいち早く反映される特徴があります。
OpenCVは単なる画像処理ライブラリにとどまらず、カメラキャリブレーション、3D再構築、物体追跡、顔認識などの高度なコンピュータビジョン技術もサポートしています。
これにより、画像処理の基礎から応用まで一貫して学べる環境を提供しています。
C++ APIとC APIの違い
OpenCVは歴史的にC言語で書かれたAPIが最初に提供されましたが、現在はC++向けのAPIが主流となっています。
C APIはOpenCV 1.x系で使われていたもので、関数ベースのインターフェースが中心です。
一方、C++ APIはOpenCV 2.x以降に導入され、クラスや名前空間を活用したオブジェクト指向設計が特徴です。
C++ APIのメリットは以下の通りです。
- 直感的なコード記述
画像や行列を表すcv::Matクラスをはじめ、多くの機能がクラスメソッドとして提供されているため、コードが読みやすくなります。
- メモリ管理の自動化
C APIでは手動でメモリ確保・解放を行う必要がありましたが、C++ APIではスマートポインタ的な仕組みでメモリ管理が自動化されています。
- 拡張性と保守性の向上
名前空間cvにより関数やクラスが整理されており、名前の衝突を避けやすくなっています。
また、将来的な機能追加もC++ API中心に行われています。
- 例外処理のサポート
C++の例外機構を利用できるため、エラー処理が柔軟に行えます。
以下はC APIとC++ APIの簡単な比較例です。
// C API(古いスタイル。最新のOpenCVではおそらく動きません)
IplImage* img = cvLoadImage("sample.jpg", CV_LOAD_IMAGE_COLOR);
cvShowImage("Image", img);
cvReleaseImage(&img);
cvWaitKey(0);// C++ API(推奨)
cv::Mat img = cv::imread("sample.jpg", cv::IMREAD_COLOR);
cv::imshow("Image", img);
cv::waitKey(0);C++ APIのほうがコードがシンプルで安全に書けることがわかります。
現在はC++ APIを使うことが標準的な方法です。
cv::Matの基本
OpenCVのC++ APIで画像や行列を扱う際の中心的なクラスがcv::Matです。
Matは「Matrix(行列)」の略で、画像データを格納するための多次元配列を表現しています。
画像処理のほぼすべての操作はcv::Matを介して行われます。
データ表現の内部構造
cv::Matは画像のピクセルデータを連続したメモリ領域に格納しています。
画像の幅、高さ、チャンネル数、データ型(8ビット符号なし整数、32ビット浮動小数点など)をメンバ変数で管理し、これらの情報をもとに画像の各ピクセルにアクセスします。
例えば、カラー画像は通常3チャンネル(BGR順)で、1ピクセルあたり3バイト(8ビット×3)で表現されます。
グレースケール画像は1チャンネルで1バイトです。
cv::Matは以下のような情報を持っています。
rows:画像の行数(高さ)cols:画像の列数(幅)channels():チャンネル数depth():1チャンネルあたりのデータ型(例:CV_8Uは8ビット符号なし整数)data:実際のピクセルデータへのポインタ
この構造により、Matは画像だけでなく、任意の多次元配列としても利用可能です。
参照カウンタとコピーオンライト
cv::Matの大きな特徴は、コピー時にデータの実体を複製しない「コピーオンライト(Copy-On-Write)」の仕組みを持っていることです。
これは、Matオブジェクトをコピーしても内部のピクセルデータは共有され、実際にデータを書き換えるタイミングで初めて複製が行われるというものです。
この仕組みは参照カウンタで管理されており、複数のMatが同じデータを指している場合、メモリの無駄遣いを防ぎつつ高速にコピーが可能です。
以下のサンプルコードで動作を確認してみましょう。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 画像を読み込む
cv::Mat img1 = cv::imread("sample.jpg", cv::IMREAD_COLOR);
if (img1.empty()) {
std::cerr << "画像が読み込めませんでした。" << std::endl;
return -1;
}
// img1をコピー(データは共有される)
cv::Mat img2 = img1;
// img2の一部のピクセルを書き換える(この時点でデータが複製される)
img2(cv::Rect(0, 0, 100, 100)).setTo(cv::Scalar(0, 0, 255)); // 左上100x100を赤に変更
// 画像を表示
cv::imshow("Original Image (img1)", img1);
cv::imshow("Modified Image (img2)", img2);
cv::waitKey(0);
return 0;
}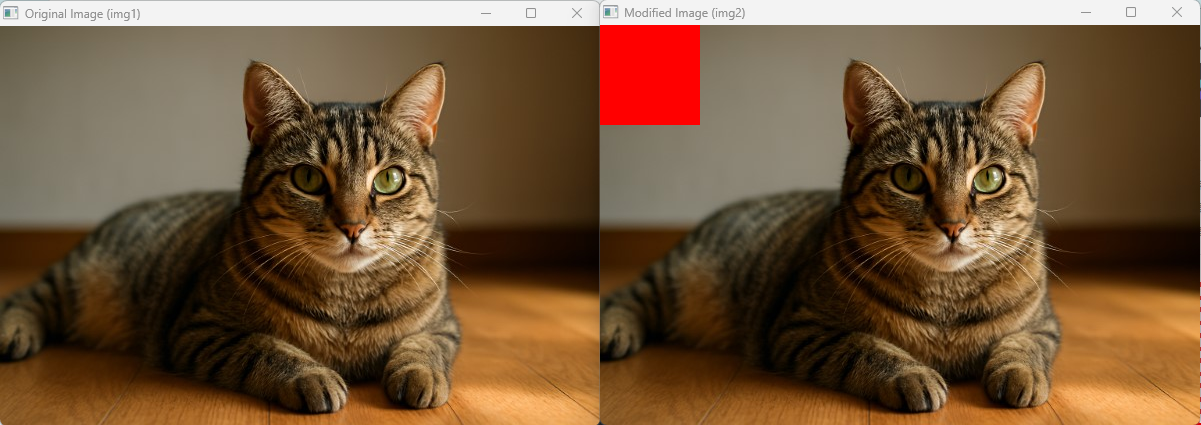
このように、cv::Matは効率的にメモリを使いながら安全に画像データを扱える設計になっています。
画像処理のパフォーマンスを最大限に引き出すために、この仕組みを理解しておくことは非常に重要です。
画像の入出力と基本操作
画像読込 imread
画像を扱う際の最初のステップはファイルから画像を読み込むことです。
OpenCVではcv::imread関数を使います。
ファイルパスと読み込みモードを指定するだけで、簡単に画像をcv::Mat形式で取得できます。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 画像をカラーで読み込む
cv::Mat img = cv::imread("sample.jpg", cv::IMREAD_COLOR);
if (img.empty()) {
std::cerr << "画像が読み込めませんでした。" << std::endl;
return -1;
}
std::cout << "画像サイズ: " << img.cols << "x" << img.rows << std::endl;
return 0;
}画像サイズ: 640x480imreadの第二引数には以下のようなフラグを指定できます。
| フラグ名 | 説明 |
|---|---|
cv::IMREAD_COLOR | カラー画像として読み込む(デフォルト) |
cv::IMREAD_GRAYSCALE | グレースケール画像として読み込む |
cv::IMREAD_UNCHANGED | アルファチャンネルも含めて読み込む |
ファイルが存在しない場合や読み込みに失敗すると、空のMatが返るため、empty()でチェックすることが重要です。
ウィンドウ表示 imshow
読み込んだ画像を画面に表示するにはcv::imshowを使います。
ウィンドウ名と表示したいMatを渡すだけで表示されます。
表示後はcv::waitKeyでキー入力を待つ必要があります。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("sample.jpg");
if (img.empty()) return -1;
cv::imshow("Display Window", img);
cv::waitKey(0); // キー入力待ち(0は無限待機)
return 0;
}waitKeyの引数は待機時間(ミリ秒)で、0を指定すると無限に待ちます。
リアルタイム処理では適切な値を設定してループ制御に使います。
画像保存 imwrite
処理した画像をファイルに保存するにはcv::imwriteを使います。
保存先のパスと保存したいMatを渡すだけです。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat img = cv::imread("sample.jpg");
if (img.empty()) return -1;
bool result = cv::imwrite("output.png", img);
if (result) {
std::cout << "画像を保存しました。" << std::endl;
} else {
std::cerr << "画像の保存に失敗しました。" << std::endl;
}
return 0;
}保存形式は拡張子で自動判別されます。
JPEG、PNG、BMPなど主要なフォーマットに対応しています。
JPEG保存時は画質パラメータも指定可能です。
グレースケール変換
カラー画像をグレースケールに変換するにはcv::cvtColorを使い、変換コードにcv::COLOR_BGR2GRAYを指定します。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat colorImg = cv::imread("sample.jpg");
if (colorImg.empty()) return -1;
cv::Mat grayImg;
cv::cvtColor(colorImg, grayImg, cv::COLOR_BGR2GRAY);
cv::imshow("Gray Image", grayImg);
cv::waitKey(0);
return 0;
}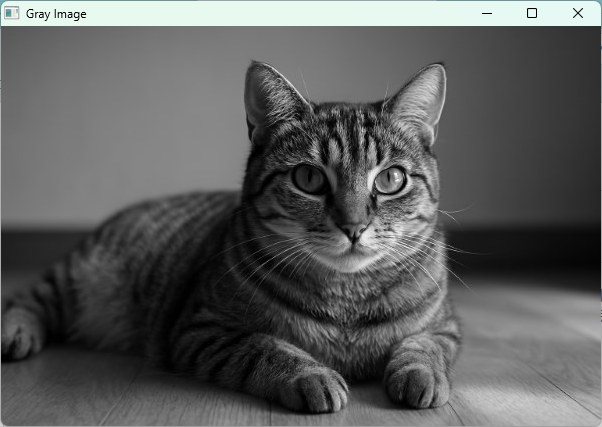
グレースケール画像は1チャンネルのため、画像処理の前処理や特徴抽出でよく使われます。
画像サイズ変更 resize
画像の大きさを変更するにはcv::resizeを使います。
拡大・縮小の両方に対応し、出力サイズや拡大率を指定できます。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("sample.jpg");
if (img.empty()) return -1;
cv::Mat resizedImg;
// 画像サイズを半分に縮小
cv::resize(img, resizedImg, cv::Size(img.cols / 2, img.rows / 2));
cv::imshow("Original", img);
cv::imshow("Resized", resizedImg);
cv::waitKey(0);
return 0;
}補間アルゴリズムごとの比較
resizeでは補間方法を指定できます。
主な補間方法は以下の通りです。
| 補間方法 | 説明 | 用途例 |
|---|---|---|
cv::INTER_NEAREST | 最近傍補間。高速だがギザギザが目立ちます。 | ラフな縮小や高速処理時 |
cv::INTER_LINEAR | バイリニア補間。標準的でバランス良いでしょう。 | 一般的な拡大縮小 |
cv::INTER_CUBIC | バイキュービック補間。滑らかで高品質。 | 高品質な拡大 |
cv::INTER_LANCZOS4 | Lanczos補間。高品質だが計算コスト高いでしょう。 | 高精度な画像処理 |
以下は補間方法の違いを比較するサンプルです。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("sample.jpg");
if (img.empty()) return -1;
cv::Mat nearest, linear, cubic, lanczos;
cv::resize(img, nearest, cv::Size(), 2.0, 2.0, cv::INTER_NEAREST);
cv::resize(img, linear, cv::Size(), 2.0, 2.0, cv::INTER_LINEAR);
cv::resize(img, cubic, cv::Size(), 2.0, 2.0, cv::INTER_CUBIC);
cv::resize(img, lanczos, cv::Size(), 2.0, 2.0, cv::INTER_LANCZOS4);
cv::imshow("Nearest", nearest);
cv::imshow("Linear", linear);
cv::imshow("Cubic", cubic);
cv::imshow("Lanczos", lanczos);
cv::waitKey(0);
return 0;
}INTER_NEARESTはエッジがギザギザしやすく、INTER_CUBICやINTER_LANCZOS4は滑らかで自然な拡大が可能です。
用途に応じて使い分けてください。
ROIの切り出し
画像の一部領域(Region of Interest, ROI)を切り出すには、cv::Matのoperator()にcv::Rectを渡します。
ROIは元画像のデータを参照するビューであり、コピーはされません。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("sample.jpg");
if (img.empty()) return -1;
// 左上から幅100、高さ100の領域を切り出す
cv::Rect roi(0, 0, 100, 100);
cv::Mat roiImg = img(roi);
cv::imshow("ROI", roiImg);
cv::waitKey(0);
return 0;
}ROIは元画像の一部を参照しているため、ROIの画素値を変更すると元画像も変わります。
clone と copyTo の使い分け
ROIやMatのコピーを作成する際、単純な代入は参照を共有するだけです。
実際にデータを複製したい場合はclone()かcopyTo()を使います。
clone()
完全な深いコピーを作成し、新しいメモリ領域にデータを複製します。
copyTo()
コピー先のMatにデータをコピーします。
コピー先が未初期化でも自動的にサイズ・型を合わせて確保します。
以下の例で違いを確認します。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat img = cv::imread("sample.jpg");
if (img.empty()) return -1;
cv::Rect roi(0, 0, 100, 100);
cv::Mat roiRef = img(roi); // 参照のみ
cv::Mat roiClone = roiRef.clone(); // データを複製
cv::Mat roiCopy;
roiRef.copyTo(roiCopy); // データを複製
// roiRefの一部を赤に変更(元画像も変わる)
roiRef.setTo(cv::Scalar(0, 0, 255));
// roiCloneとroiCopyは元画像の変更の影響を受けない
cv::imshow("Original Image", img);
cv::imshow("ROI Reference", roiRef);
cv::imshow("ROI Clone", roiClone);
cv::imshow("ROI Copy", roiCopy);
cv::waitKey(0);
return 0;
}// 実行結果の説明
// 「Original Image」と「ROI Reference」は赤く塗りつぶされた部分が反映されています。
// 「ROI Clone」と「ROI Copy」は元画像の変更前の状態を保持しています。clone()とcopyTo()はほぼ同じ動作ですが、copyTo()はコピー先を指定できるため、既存のMatにコピーしたい場合に便利です。
ROIの独立した画像を作成したいときはどちらかを使いましょう。
色空間処理
BGRとRGBの違い
OpenCVで画像を扱う際、カラー画像のピクセルは通常3チャンネルで表現されますが、その順序は一般的なRGBとは異なり、BGR(Blue, Green, Red)順になっています。
これはOpenCVの設計上の仕様で、画像データの読み込みや表示、処理の際にこの順序が使われます。
例えば、赤色のピクセルはRGBでは(255, 0, 0)ですが、OpenCVのBGRでは(0, 0, 255)となります。
この違いを理解していないと、色の指定や処理結果が意図しない色になることがあるため注意が必要です。
他のライブラリや画像フォーマットではRGB順が多いため、OpenCVと連携する際は色チャンネルの順序変換を行うことがあります。
色空間変換 cvtColor
色空間変換は画像の色表現を別の形式に変換する処理で、OpenCVではcv::cvtColor関数を使います。
変換コードを指定することで、BGRからHSVやLab、YCrCbなど多様な色空間に変換可能です。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("sample.jpg");
if (img.empty()) return -1;
cv::Mat hsvImg;
cv::cvtColor(img, hsvImg, cv::COLOR_BGR2HSV);
cv::imshow("Original", img);
cv::imshow("HSV", hsvImg);
cv::waitKey(0);
return 0;
}HSV
HSV色空間は色相(Hue)、彩度(Saturation)、明度(Value)で色を表現します。
色相は色の種類を角度(0〜179)で表し、彩度は色の鮮やかさ、明度は明るさを示します。
HSVは色の抽出や色調補正に適しており、特定の色をマスクで抽出する際に便利です。
例えば、赤色だけを抽出したい場合、HSVの色相範囲を指定してマスクを作成します。
Lab
Lab色空間は人間の視覚に基づいた色空間で、Lは明度、aは緑〜赤の軸、bは青〜黄の軸を表します。
色の差異を定量的に評価しやすいため、色補正や色比較に使われます。
Labは照明条件の変化に強い特徴があり、画像の色調整や物体認識の前処理で利用されることが多いです。
YCrCb
YCrCb色空間は輝度成分Yと色差成分Cr、Cbに分かれています。
テレビ放送や動画圧縮でよく使われる形式で、輝度と色を分離して処理できるため、圧縮効率が良い特徴があります。
OpenCVではYCrCb変換もサポートしており、肌色検出やノイズ除去などに活用されます。
チャネル分離と統合
画像の各色チャンネルを個別に操作したい場合、cv::splitで分離し、cv::mergeで統合します。
#include <opencv2/opencv.hpp>
#include <vector>
int main() {
cv::Mat img = cv::imread("sample.jpg");
if (img.empty()) return -1;
std::vector<cv::Mat> channels;
cv::split(img, channels); // B, G, Rに分離
// 例:青チャンネルを強調
channels[0] = channels[0] + 50;
cv::Mat merged;
cv::merge(channels, merged);
cv::imshow("Original", img);
cv::imshow("Blue Enhanced", merged);
cv::waitKey(0);
return 0;
}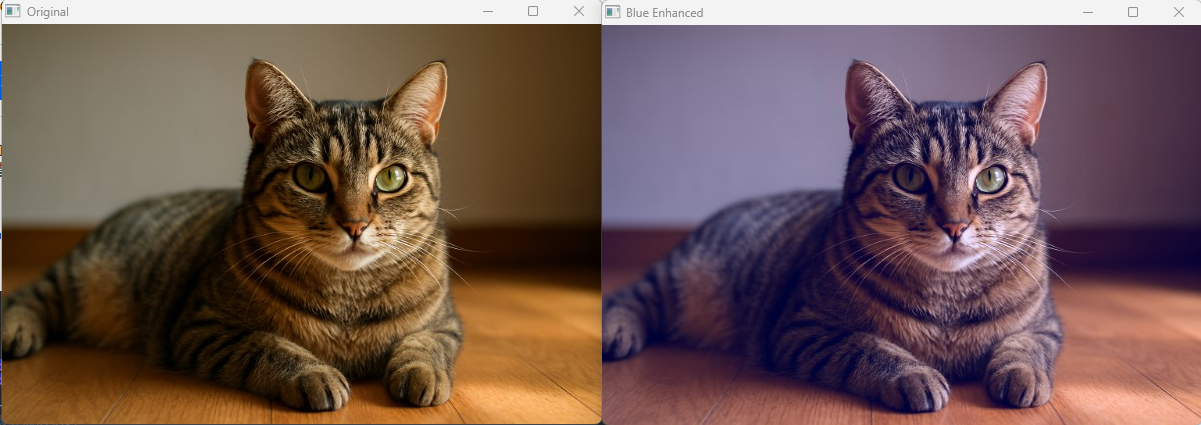
チャンネル分離は色ごとの処理や特徴抽出に役立ちます。
分離後のチャンネルは単一チャンネルのMatとして扱えます。
マスクを用いた色抽出
特定の色範囲を抽出するには、色空間変換後にcv::inRange関数でマスクを作成します。
マスクは指定した範囲内のピクセルを白(255)、それ以外を黒(0)にした二値画像です。
以下はHSV色空間で赤色を抽出する例です。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("sample.jpg");
if (img.empty()) return -1;
cv::Mat hsv;
cv::cvtColor(img, hsv, cv::COLOR_BGR2HSV);
// 赤色の範囲(Hueは0〜10と160〜179の2範囲に分かれる)
cv::Mat mask1, mask2, mask;
cv::inRange(hsv, cv::Scalar(0, 100, 100), cv::Scalar(10, 255, 255), mask1);
cv::inRange(hsv, cv::Scalar(160, 100, 100), cv::Scalar(179, 255, 255), mask2);
cv::bitwise_or(mask1, mask2, mask);
// 元画像にマスクを適用
cv::Mat result;
cv::bitwise_and(img, img, result, mask);
cv::imshow("Original", img);
cv::imshow("Red Mask", mask);
cv::imshow("Extracted Red", result);
cv::waitKey(0);
return 0;
}この方法で特定の色だけを抽出し、物体検出や追跡の前処理に利用できます。
マスク画像は二値画像なので、輪郭抽出やモルフォロジー処理と組み合わせることも多いです。
フィルタリングと平滑化
平均化フィルタ
平均化フィルタは画像のノイズを低減し、滑らかにするための基本的な手法です。
画像の各ピクセルを、その周囲のピクセル値の平均で置き換えます。
OpenCVではcv::blur関数を使って実装します。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("sample.jpg");
if (img.empty()) return -1;
cv::Mat blurred;
// 5x5のカーネルで平均化フィルタを適用
cv::blur(img, blurred, cv::Size(5, 5));
cv::imshow("Original", img);
cv::imshow("Average Blur", blurred);
cv::waitKey(0);
return 0;
}

平均化フィルタはノイズを減らす効果がありますが、エッジもぼやけてしまうため、エッジを保持したい場合は他のフィルタを検討します。
GaussianBlur
ガウシアンフィルタは平均化フィルタの一種ですが、周囲のピクセルに対してガウス関数に基づく重みを付けて平滑化します。
これにより、中心に近いピクセルの影響が大きくなり、より自然なぼかし効果が得られます。
OpenCVではcv::GaussianBlurを使います。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("sample.jpg");
if (img.empty()) return -1;
cv::Mat gaussianBlurred;
// 7x7のカーネル、標準偏差は0(自動計算)
cv::GaussianBlur(img, gaussianBlurred, cv::Size(7, 7), 0);
cv::imshow("Original", img);
cv::imshow("Gaussian Blur", gaussianBlurred);
cv::waitKey(0);
return 0;
}
ガウシアンフィルタはノイズ除去だけでなく、画像の前処理やエッジ検出の前段階としてもよく使われます。
MedianBlur
メディアンフィルタはノイズ除去に優れた非線形フィルタで、特に「塩胡椒ノイズ」と呼ばれるランダムな白黒点ノイズに強い特徴があります。
各ピクセルを周囲のピクセル値の中央値に置き換えます。
OpenCVではcv::medianBlurを使います。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("noisy_sample.jpg");
if (img.empty()) return -1;
cv::Mat medianBlurred;
// カーネルサイズは奇数(例:5)
cv::medianBlur(img, medianBlurred, 5);
cv::imshow("Noisy Image", img);
cv::imshow("Median Blur", medianBlurred);
cv::waitKey(0);
return 0;
}

メディアンフィルタはエッジを比較的保持しつつノイズを除去できるため、医療画像や監視カメラ映像の前処理でよく使われます。
BilateralFilter
バイラテラルフィルタはエッジを保持しながらノイズを除去する高度な平滑化手法です。
空間的な近さと色の類似度の両方を考慮して重み付けを行うため、エッジ部分のぼかしを抑えられます。
OpenCVではcv::bilateralFilterを使います。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("sample.jpg");
if (img.empty()) return -1;
cv::Mat bilateralBlurred;
// d=9:近傍の直径, sigmaColor=75, sigmaSpace=75
cv::bilateralFilter(img, bilateralBlurred, 9, 75, 75);
cv::imshow("Original", img);
cv::imshow("Bilateral Filter", bilateralBlurred);
cv::waitKey(0);
return 0;
}
バイラテラルフィルタは計算コストが高いため、リアルタイム処理では注意が必要ですが、顔画像の美肌処理やノイズ除去に効果的です。
カーネルサイズの選択指針
フィルタリングで使うカーネルサイズ(フィルタの窓の大きさ)は処理結果に大きく影響します。
一般的な指針は以下の通りです。
| カーネルサイズ | 特徴 | 用途例 |
|---|---|---|
| 小さい(3×3〜5×5) | ノイズ除去効果は控えめ。エッジの保持に優れる。 | 軽微なノイズ除去やリアルタイム処理 |
| 中くらい(7×7〜9×9) | ノイズ除去効果とぼかし効果のバランスが良いでしょう。 | 一般的な画像の平滑化 |
| 大きい(11×11以上) | 強いぼかし効果。細部が失われやすい。 | 背景ぼかしやアート効果 |
カーネルサイズは奇数で指定する必要があります。
大きすぎると画像がぼやけすぎるため、目的に応じて適切なサイズを選んでください。
また、ガウシアンフィルタでは標準偏差(sigma)も重要で、カーネルサイズとsigmaの組み合わせでぼかしの強さが決まります。
sigmaを0にすると自動計算されますが、明示的に指定することも可能です。
これらのフィルタを使い分けることで、ノイズ除去やエッジ保持などの目的に応じた画像処理が実現できます。
エッジ検出
SobelとScharr
Sobelフィルタは画像の勾配(輝度変化)を検出するための微分フィルタで、エッジ検出の基本的な手法です。
水平方向(x方向)と垂直方向(y方向)の勾配を計算し、それらを組み合わせてエッジの強さや方向を求めます。
OpenCVではcv::Sobel関数を使います。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("sample.jpg", cv::IMREAD_GRAYSCALE);
if (img.empty()) return -1;
cv::Mat grad_x, grad_y;
cv::Mat abs_grad_x, abs_grad_y, grad;
// x方向の勾配(3x3カーネル)
cv::Sobel(img, grad_x, CV_16S, 1, 0, 3);
// y方向の勾配(3x3カーネル)
cv::Sobel(img, grad_y, CV_16S, 0, 1, 3);
// 絶対値に変換
cv::convertScaleAbs(grad_x, abs_grad_x);
cv::convertScaleAbs(grad_y, abs_grad_y);
// 勾配の合成(重み付け和)
cv::addWeighted(abs_grad_x, 0.5, abs_grad_y, 0.5, 0, grad);
cv::imshow("Original", img);
cv::imshow("Sobel Edge", grad);
cv::waitKey(0);
return 0;
}

Sobelフィルタは3×3のカーネルを使うことが多いですが、より高精度な微分を求めたい場合はScharrフィルタを使います。
ScharrはSobelの改良版で、特に小さいカーネルサイズ(3×3)での微分精度が高いです。
OpenCVではcv::Scharr関数で利用可能です。
cv::Scharr(img, grad_x, CV_16S, 1, 0);
cv::Scharr(img, grad_y, CV_16S, 0, 1);SobelとScharrはどちらもエッジの方向や強さを計算するために使われ、画像の輪郭検出や特徴抽出の前処理として有効です。
Canny
Cannyエッジ検出はエッジ検出アルゴリズムの中でも特に有名で、高精度かつノイズに強い特徴があります。
以下のステップで処理が行われます。
- ガウシアンフィルタでノイズ除去
- Sobelフィルタで勾配の強さと方向を計算
- 非最大抑制でエッジの細線化
- ヒステリシスしきい値処理でエッジを確定
OpenCVではcv::Canny関数で簡単に実装できます。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("sample.jpg", cv::IMREAD_GRAYSCALE);
if (img.empty()) return -1;
cv::Mat edges;
// 低閾値50、高閾値150でCannyエッジ検出
cv::Canny(img, edges, 50, 150);
cv::imshow("Original", img);
cv::imshow("Canny Edges", edges);
cv::waitKey(0);
return 0;
}
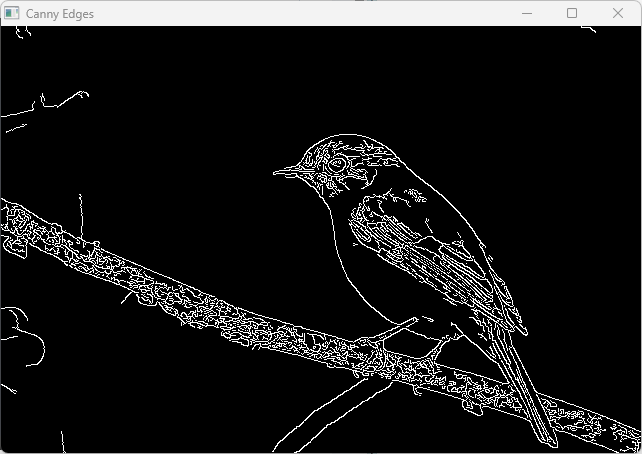
適切な閾値の決定
Cannyエッジ検出では2つの閾値(低閾値と高閾値)を設定します。
高閾値以上の勾配は強いエッジとみなされ、低閾値以上かつ高閾値未満の勾配は強いエッジに隣接している場合にエッジとして扱われます。
これによりノイズの影響を抑えつつ細いエッジを検出できます。
閾値の選び方は画像の特性によりますが、一般的には高閾値を低閾値の約2〜3倍に設定することが多いです。
閾値が低すぎるとノイズが多く検出され、高すぎるとエッジが抜け落ちるため、試行錯誤が必要です。
自動的に閾値を決める方法としては、画像のヒストグラムや勾配強度の統計を利用する手法もありますが、OpenCV標準では手動設定が基本です。
Laplacian
Laplacianフィルタは2階微分を用いたエッジ検出手法で、画像の輝度の急激な変化を検出します。
SobelやScharrが1階微分でエッジの方向を考慮するのに対し、Laplacianは方向を持たず、エッジの存在を強調します。
OpenCVではcv::Laplacian関数を使います。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("sample.jpg", cv::IMREAD_GRAYSCALE);
if (img.empty()) return -1;
cv::Mat laplacian, abs_laplacian;
cv::Laplacian(img, laplacian, CV_16S, 3);
cv::convertScaleAbs(laplacian, abs_laplacian);
cv::imshow("Original", img);
cv::imshow("Laplacian", abs_laplacian);
cv::waitKey(0);
return 0;
}

Laplacianはエッジの強調に使われますが、ノイズに敏感なため、前段階でガウシアンブラーなどの平滑化を行うことが推奨されます。
エッジ画像の後処理
エッジ検出後の画像はノイズや細かい断片が含まれることが多いため、後処理で精度を高めることが一般的です。
代表的な後処理手法は以下の通りです。
- モルフォロジー処理
cv::morphologyExを使い、膨張(dilate)や収縮(erode)でエッジの断片をつなげたりノイズを除去したりします。
- 輪郭抽出
cv::findContoursでエッジの輪郭を抽出し、面積や形状で不要な部分を除去できます。
- 平滑化
エッジ画像に対して平滑化を行い、細かいノイズを減らすこともあります。
以下はモルフォロジー処理の例です。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("sample.jpg", cv::IMREAD_GRAYSCALE);
if (img.empty()) return -1;
cv::Mat edges;
cv::Canny(img, edges, 50, 150);
// モルフォロジー膨張でエッジを太くする
cv::Mat dilated;
cv::dilate(edges, dilated, cv::Mat(), cv::Point(-1, -1), 1);
cv::imshow("Canny Edges", edges);
cv::imshow("Dilated Edges", dilated);
cv::waitKey(0);
return 0;
}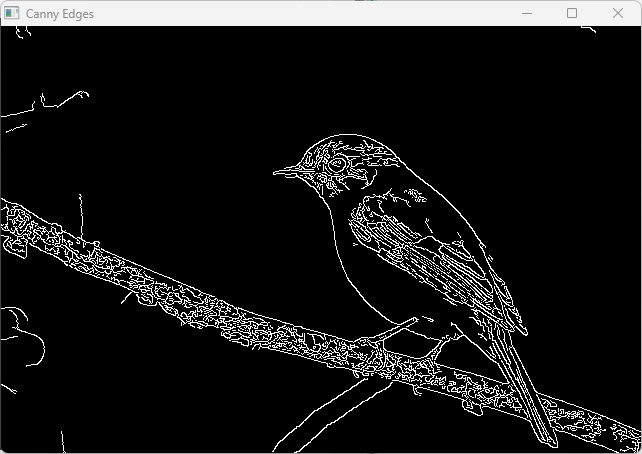

このように後処理を組み合わせることで、エッジ検出の結果をより扱いやすくできます。
用途に応じて適切な処理を選択してください。
二値化としきい値処理
グローバルしきい値 threshold
グローバルしきい値処理は、画像全体に対して一定の閾値を設定し、ピクセルの輝度値をその閾値と比較して二値化する方法です。
OpenCVではcv::threshold関数を使います。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat img = cv::imread("sample.jpg", cv::IMREAD_GRAYSCALE);
if (img.empty()) {
std::cerr << "画像が読み込めませんでした。" << std::endl;
return -1;
}
cv::Mat binary;
double thresh = 128; // 閾値
double maxValue = 255; // 最大値(白)
// 閾値処理(バイナリ)
cv::threshold(img, binary, thresh, maxValue, cv::THRESH_BINARY);
cv::imshow("Original", img);
cv::imshow("Binary Threshold", binary);
cv::waitKey(0);
return 0;
}
threshold関数の主なパラメータは以下の通りです。
- 入力画像(グレースケール推奨)
- 出力画像
- 閾値
thresh - 最大値(閾値を超えたピクセルに設定される値)
- しきい値タイプ(例:
THRESH_BINARY、THRESH_BINARY_INVなど)
グローバルしきい値は画像全体に同じ閾値を適用するため、照明ムラや影がある画像ではうまく二値化できないことがあります。
大津の方法 THRESH_OTSU
大津の方法は、画像のヒストグラムを解析して自動的に最適なしきい値を決定するアルゴリズムです。
OpenCVではcv::thresholdのフラグにTHRESH_OTSUを指定することで利用できます。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat img = cv::imread("sample.jpg", cv::IMREAD_GRAYSCALE);
if (img.empty()) {
std::cerr << "画像が読み込めませんでした。" << std::endl;
return -1;
}
cv::Mat binary;
double thresh = cv::threshold(img, binary, 0, 255, cv::THRESH_BINARY | cv::THRESH_OTSU);
std::cout << "大津の方法で決定された閾値: " << thresh << std::endl;
cv::imshow("Original", img);
cv::imshow("Otsu Binary", binary);
cv::waitKey(0);
return 0;
}大津の方法は画像のヒストグラムが二峰性(二つのピークを持つ)である場合に特に効果的で、手動で閾値を設定しなくても良い点がメリットで
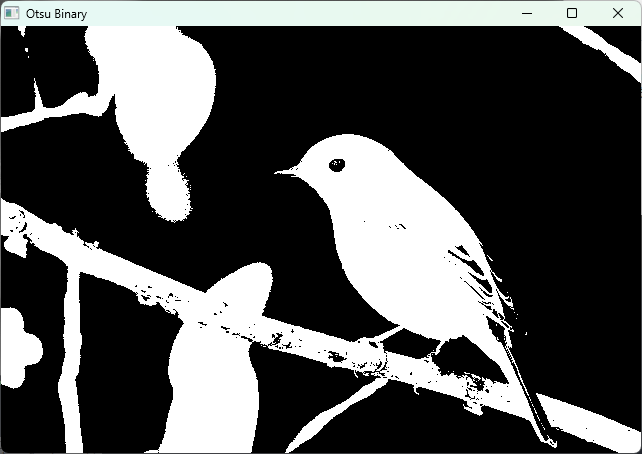
す。
適応的二値化
適応的二値化は、画像の局所的な領域ごとに異なる閾値を計算して二値化する方法です。
照明ムラや影がある画像でも効果的に二値化できます。
OpenCVではcv::adaptiveThreshold関数を使います。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("uneven_lighting.jpg", cv::IMREAD_GRAYSCALE);
if (img.empty()) return -1;
cv::Mat adaptiveBinary;
// ブロックサイズは奇数、Cは閾値から引く定数
cv::adaptiveThreshold(img, adaptiveBinary, 255,
cv::ADAPTIVE_THRESH_MEAN_C,
cv::THRESH_BINARY, 11, 2);
cv::imshow("Original", img);
cv::imshow("Adaptive Threshold", adaptiveBinary);
cv::waitKey(0);
return 0;
}

主なパラメータは以下の通りです。
- 最大値(通常255)
- 適応方法
ADAPTIVE_THRESH_MEAN_C:局所領域の平均値を閾値に使用ADAPTIVE_THRESH_GAUSSIAN_C:局所領域の加重平均(ガウシアン)を閾値に使用
- しきい値タイプ(
THRESH_BINARYなど) - ブロックサイズ(閾値計算に使う局所領域のサイズ、奇数)
- 定数C(閾値から引く値)
適応的二値化は文字認識や文書画像処理でよく使われます。
ヒストグラム平坦化
ヒストグラム平坦化は画像のコントラストを強調し、二値化の前処理として有効です。
OpenCVではcv::equalizeHist関数を使い、グレースケール画像のヒストグラムを均一化します。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("low_contrast.jpg", cv::IMREAD_GRAYSCALE);
if (img.empty()) return -1;
cv::Mat equalized;
cv::equalizeHist(img, equalized);
cv::imshow("Original", img);
cv::imshow("Equalized", equalized);
cv::waitKey(0);
return 0;
}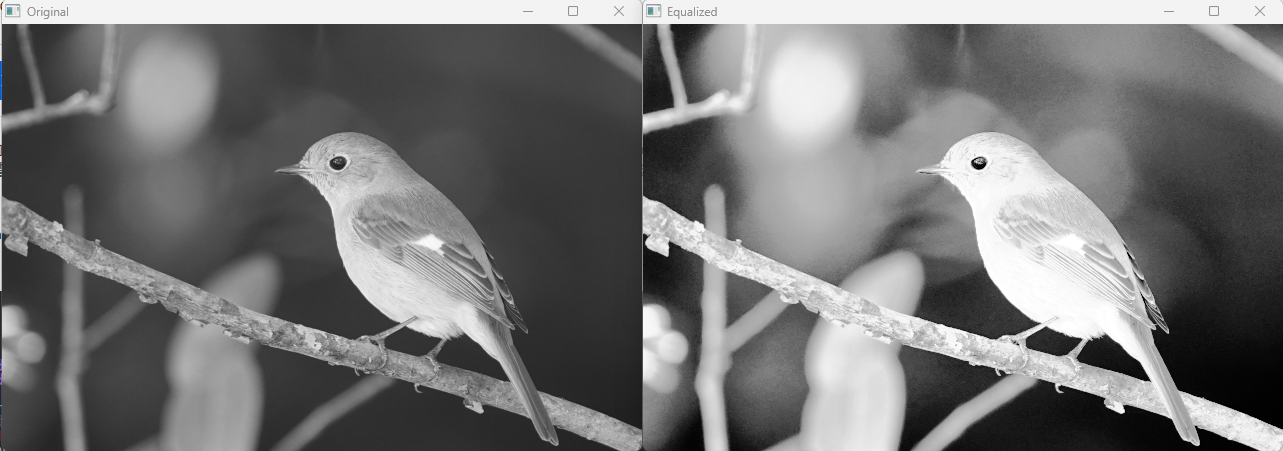
ヒストグラム平坦化により、画像の明暗差が強調され、しきい値処理の精度が向上します。
特に暗い画像やコントラストが低い画像で効果的です。
これらの二値化・しきい値処理を組み合わせて使うことで、様々な画像の特徴抽出や前処理が可能になります。
輪郭抽出と図形解析
findContours と drawContours
輪郭抽出は画像内の物体の境界線を検出する処理で、OpenCVではcv::findContours関数を使います。
二値化画像を入力として、輪郭の点列を取得できます。
取得した輪郭はcv::drawContoursで描画可能です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat img = cv::imread("shapes.png", cv::IMREAD_GRAYSCALE);
if (img.empty()) return -1;
// 二値化(大津の方法)
cv::Mat binary;
cv::threshold(img, binary, 0, 255, cv::THRESH_BINARY | cv::THRESH_OTSU);
std::vector<std::vector<cv::Point>> contours;
std::vector<cv::Vec4i> hierarchy;
// 輪郭抽出
cv::findContours(binary, contours, hierarchy, cv::RETR_TREE, cv::CHAIN_APPROX_SIMPLE);
// 輪郭描画用のカラー画像を作成
cv::Mat contourImg = cv::Mat::zeros(img.size(), CV_8UC3);
// 輪郭をランダムな色で描画
for (size_t i = 0; i < contours.size(); i++) {
cv::Scalar color(rand() % 256, rand() % 256, rand() % 256);
cv::drawContours(contourImg, contours, static_cast<int>(i), color, 2, cv::LINE_8, hierarchy, 0);
}
cv::imshow("Original", img);
cv::imshow("Contours", contourImg);
cv::waitKey(0);
return 0;
}
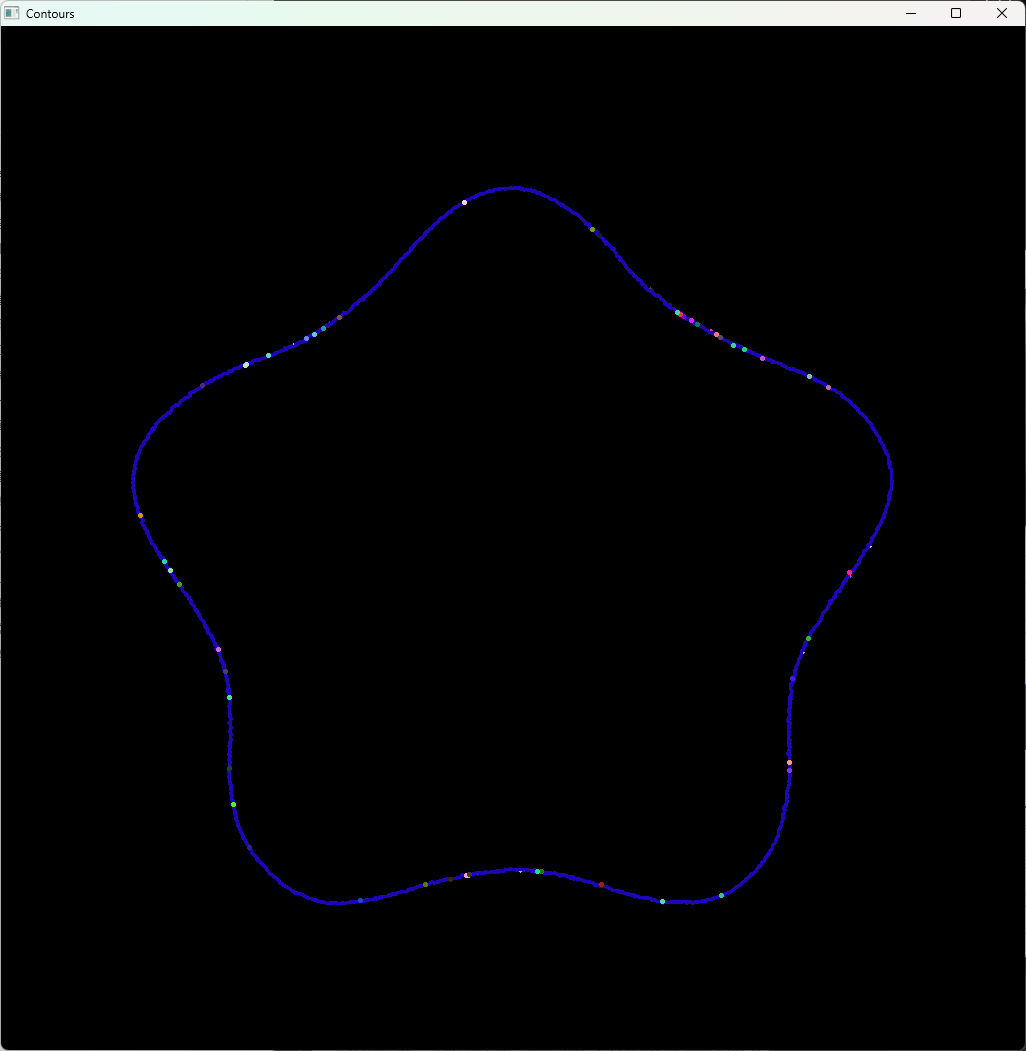
findContoursの主な引数は以下の通りです。
- 入力画像(二値化済み)
- 輪郭の格納先(点列のベクター)
- 輪郭の階層情報(オプション)
- 輪郭検出モード(例:
RETR_TREEは階層構造を取得) - 輪郭近似方法(例:
CHAIN_APPROX_SIMPLEは直線近似)
drawContoursは輪郭の描画に使い、色や線の太さを指定できます。
輪郭階層の理解
findContoursで取得できる階層情報は、輪郭同士の親子関係を表します。
階層はstd::vector<cv::Vec4i>で格納され、各要素は4つの整数で構成されます。
| インデックス | 意味 |
|---|---|
| 0 | 次の輪郭のインデックス(同じ階層) |
| 1 | 前の輪郭のインデックス(同じ階層) |
| 2 | 子の輪郭のインデックス |
| 3 | 親の輪郭のインデックス |
この情報を使うと、穴のある物体や入れ子構造の輪郭を正しく扱えます。
例えば、ドーナツ形状の輪郭は外側の輪郭が親、内側の穴の輪郭が子になります。
面積・周囲長の計算
輪郭の面積や周囲長(周囲の長さ)はcv::contourAreaとcv::arcLengthで計算できます。
これらは物体の大きさや形状解析に役立ちます。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat img = cv::imread("shapes.png", cv::IMREAD_GRAYSCALE);
if (img.empty()) return -1;
cv::Mat binary;
cv::threshold(img, binary, 0, 255, cv::THRESH_BINARY | cv::THRESH_OTSU);
std::vector<std::vector<cv::Point>> contours;
cv::findContours(binary, contours, cv::RETR_EXTERNAL, cv::CHAIN_APPROX_SIMPLE);
for (size_t i = 0; i < contours.size(); i++) {
double area = cv::contourArea(contours[i]);
double perimeter = cv::arcLength(contours[i], true);
std::cout << "Contour " << i << ": 面積 = " << area << ", 周囲長 = " << perimeter << std::endl;
}
return 0;
}Contour 0: 面積 = 0, 周囲長 = 0
Contour 1: 面積 = 0, 周囲長 = 0
Contour 2: 面積 = 0, 周囲長 = 0
Contour 3: 面積 = 0, 周囲長 = 0
Contour 4: 面積 = 0, 周囲長 = 0
Contour 5: 面積 = 0, 周囲長 = 0
Contour 6: 面積 = 0, 周囲長 = 2
Contour 7: 面積 = 0, 周囲長 = 0
Contour 8: 面積 = 0, 周囲長 = 0
Contour 9: 面積 = 372906, 周囲長 = 3018.66arcLengthの第2引数は輪郭が閉じているかどうかを示し、通常はtrueを指定します。
多角形近似 approxPolyDP
輪郭の点列は多くの点で構成されることが多いため、cv::approxPolyDPを使って多角形近似を行い、点数を減らして形状を単純化できます。
近似の精度はパラメータepsilonで調整します。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat img = cv::imread("shapes.png", cv::IMREAD_GRAYSCALE);
if (img.empty()) return -1;
cv::Mat binary;
cv::threshold(img, binary, 0, 255, cv::THRESH_BINARY | cv::THRESH_OTSU);
std::vector<std::vector<cv::Point>> contours;
cv::findContours(binary, contours, cv::RETR_EXTERNAL, cv::CHAIN_APPROX_SIMPLE);
cv::Mat approxImg = cv::Mat::zeros(img.size(), CV_8UC3);
for (size_t i = 0; i < contours.size(); i++) {
std::vector<cv::Point> approx;
double epsilon = 0.02 * cv::arcLength(contours[i], true);
cv::approxPolyDP(contours[i], approx, epsilon, true);
cv::Scalar color(0, 255, 0);
cv::polylines(approxImg, approx, true, color, 2);
std::cout << "Contour " << i << ": 元の点数 = " << contours[i].size()
<< ", 近似点数 = " << approx.size() << std::endl;
}
cv::imshow("Approximated Contours", approxImg);
cv::waitKey(0);
return 0;
}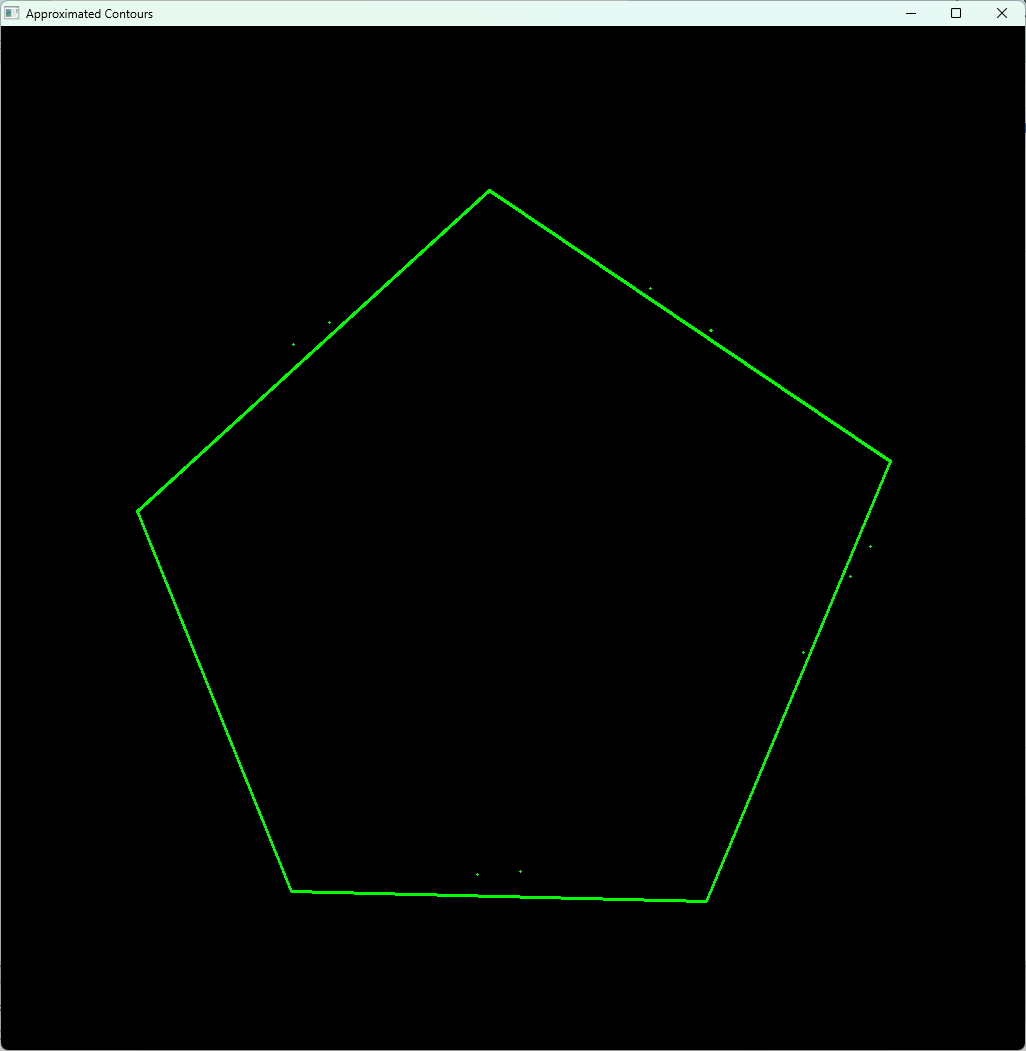
多角形近似は形状認識や物体分類の前処理に使われ、例えば四角形や三角形の検出に役立ちます。
最小外接矩形と外接円
輪郭を囲む最小の矩形や円を求めることもよくあります。
OpenCVではcv::minAreaRectで最小外接矩形、cv::minEnclosingCircleで最小外接円を計算できます。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat img = cv::imread("shapes.png");
if (img.empty()) return -1;
cv::Mat gray;
cv::cvtColor(img, gray, cv::COLOR_BGR2GRAY);
cv::Mat binary;
cv::threshold(gray, binary, 0, 255, cv::THRESH_BINARY | cv::THRESH_OTSU);
std::vector<std::vector<cv::Point>> contours;
cv::findContours(binary, contours, cv::RETR_EXTERNAL, cv::CHAIN_APPROX_SIMPLE);
cv::Mat result = img.clone();
for (size_t i = 0; i < contours.size(); i++) {
// 最小外接矩形
cv::RotatedRect minRect = cv::minAreaRect(contours[i]);
cv::Point2f rectPoints[4];
minRect.points(rectPoints);
for (int j = 0; j < 4; j++) {
cv::line(result, rectPoints[j], rectPoints[(j + 1) % 4], cv::Scalar(0, 255, 0), 2);
}
// 最小外接円
cv::Point2f center;
float radius;
cv::minEnclosingCircle(contours[i], center, radius);
cv::circle(result, center, static_cast<int>(radius), cv::Scalar(255, 0, 0), 2);
}
cv::imshow("Min Area Rect and Enclosing Circle", result);
cv::waitKey(0);
return 0;
}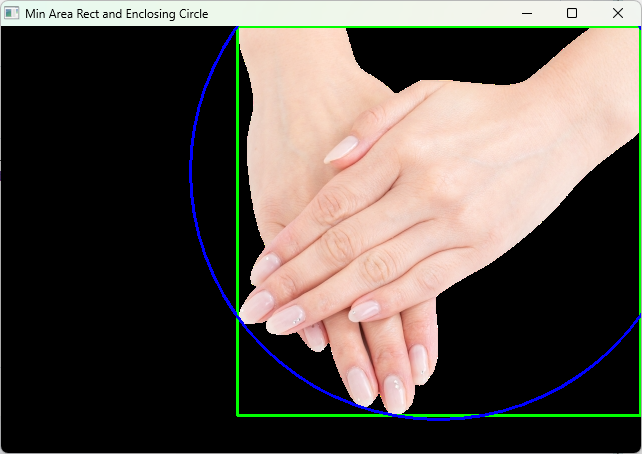
最小外接矩形は回転角度を持つため、物体の向き推定にも使えます。
外接円は物体の大きさや位置の簡易的な把握に便利です。
これらの図形解析は物体認識やトラッキングの基礎となります。
幾何変換
平行移動と拡大縮小
画像の平行移動や拡大縮小は、アフィン変換の一種であり、変換行列を用いて実現します。
OpenCVではcv::warpAffine関数を使い、2×3の変換行列を渡して画像を変換します。
平行移動と拡大縮小の変換行列は以下のように作成します。
\[M = \begin{bmatrix}s_x & 0 & t_x \\0 & s_y & t_y\end{bmatrix}\]
- \(s_x, s_y\):拡大縮小率(スケール)
- \(t_x, t_y\):平行移動量(ピクセル単位)
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("sample.jpg");
if (img.empty()) return -1;
double scale_x = 1.5; // 横方向1.5倍
double scale_y = 1.5; // 縦方向1.5倍
double translate_x = 50; // 右に50ピクセル移動
double translate_y = 30; // 下に30ピクセル移動
cv::Mat M = (cv::Mat_<double>(2, 3) << scale_x, 0, translate_x,
0, scale_y, translate_y);
cv::Mat transformed;
cv::warpAffine(img, transformed, M, img.size());
cv::imshow("Original", img);
cv::imshow("Scaled and Translated", transformed);
cv::waitKey(0);
return 0;
}
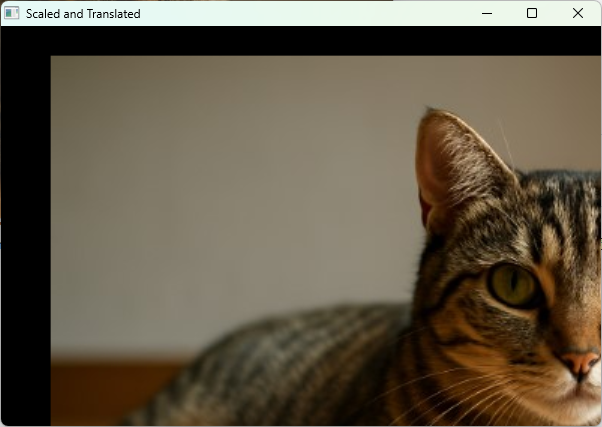
このコードでは画像を1.5倍に拡大し、右下方向に平行移動しています。
warpAffineの第4引数は出力画像のサイズで、元画像と同じサイズを指定しています。
回転 getRotationMatrix2D
画像の回転は、回転中心、回転角度、拡大縮小率を指定して変換行列を作成し、cv::warpAffineで適用します。
OpenCVにはcv::getRotationMatrix2D関数があり、簡単に回転行列を取得できます。
回転行列は以下の形式です。
\[M = \begin{bmatrix}\alpha & \beta & (1-\alpha) \cdot c_x – \beta \cdot c_y \\-\beta & \alpha & \beta \cdot c_x + (1-\alpha) \cdot c_y\end{bmatrix}\]
ここで、
- \(\alpha = s \cos \theta\)
- \(\beta = s \sin \theta\)
- \(s\):スケール(拡大縮小率)
- \(\theta\):回転角度(ラジアン)
- \((c_x, c_y)\):回転中心座標
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("sample.jpg");
if (img.empty()) return -1;
cv::Point2f center(img.cols / 2.0f, img.rows / 2.0f);
double angle = 45.0; // 45度回転
double scale = 1.0; // 拡大縮小なし
cv::Mat rotMat = cv::getRotationMatrix2D(center, angle, scale);
cv::Mat rotated;
cv::warpAffine(img, rotated, rotMat, img.size());
cv::imshow("Original", img);
cv::imshow("Rotated", rotated);
cv::waitKey(0);
return 0;
}
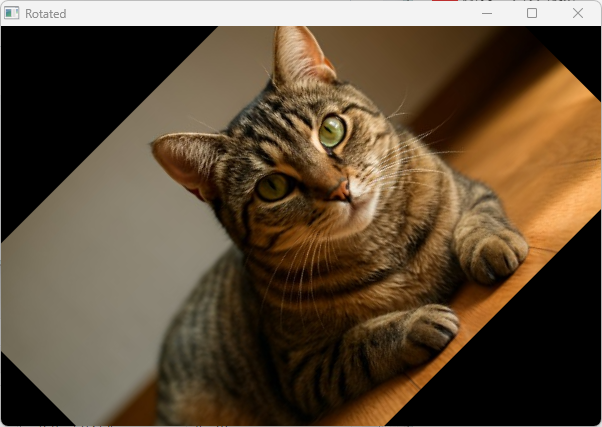
この例では画像の中心を軸に45度回転しています。
回転中心を変えることで任意の点を軸に回転可能です。
アフィン変換
アフィン変換は平行移動、回転、拡大縮小、せん断(シアー)を含む線形変換で、3点の対応関係から変換行列を求めて画像に適用します。
OpenCVではcv::getAffineTransformで3点の対応点を指定し、2×3の変換行列を取得します。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("sample.jpg");
if (img.empty()) return -1;
// 元画像の3点
std::vector<cv::Point2f> srcTri;
srcTri.push_back(cv::Point2f(0, 0));
srcTri.push_back(cv::Point2f(img.cols - 1, 0));
srcTri.push_back(cv::Point2f(0, img.rows - 1));
// 変換後の3点
std::vector<cv::Point2f> dstTri;
dstTri.push_back(cv::Point2f(0, img.rows*0.33f));
dstTri.push_back(cv::Point2f(img.cols*0.85f, img.rows*0.25f));
dstTri.push_back(cv::Point2f(img.cols*0.15f, img.rows*0.7f));
cv::Mat warpMat = cv::getAffineTransform(srcTri, dstTri);
cv::Mat warped;
cv::warpAffine(img, warped, warpMat, img.size());
cv::imshow("Original", img);
cv::imshow("Affine Transformed", warped);
cv::waitKey(0);
return 0;
}
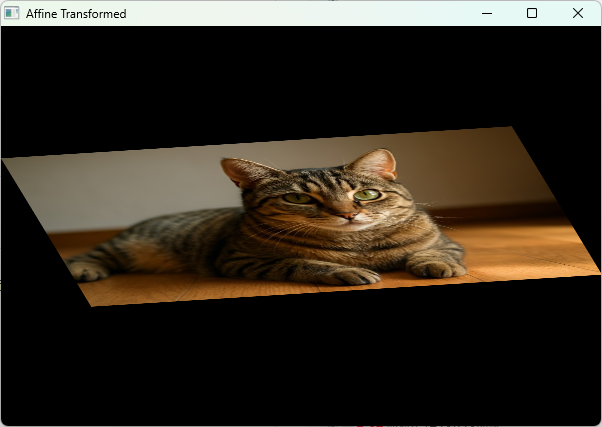
3点の対応関係を指定することで、画像の回転や拡大縮小、せん断など複合的な変換が可能です。
射影変換 perspectiveTransform
射影変換(ホモグラフィ変換)は、平面上の4点の対応関係から変換行列を求め、画像の遠近感を含む変換を行います。
OpenCVではcv::getPerspectiveTransformで4点の対応点から3×3の変換行列を取得し、cv::warpPerspectiveで変換します。
#include <iostream>
#include <opencv2/opencv.hpp>
// 4点を左上、右上、右下、左下の順に並べ替える関数
std::vector<cv::Point2f> sortPoints(const std::vector<cv::Point>& points) {
std::vector<cv::Point2f> sorted(4);
// x + y が最小が左上、最大が右下に近い
std::vector<int> sumPts;
for (const auto& p : points) sumPts.push_back(p.x + p.y);
int minSumIdx = std::distance(
sumPts.begin(), std::min_element(sumPts.begin(), sumPts.end()));
int maxSumIdx = std::distance(
sumPts.begin(), std::max_element(sumPts.begin(), sumPts.end()));
sorted[0] = points[minSumIdx]; // 左上
sorted[2] = points[maxSumIdx]; // 右下
// x - y が最小が左下、最大が右上に近い
std::vector<int> diffPts;
for (const auto& p : points) diffPts.push_back(p.x - p.y);
int minDiffIdx = std::distance(
diffPts.begin(), std::min_element(diffPts.begin(), diffPts.end()));
int maxDiffIdx = std::distance(
diffPts.begin(), std::max_element(diffPts.begin(), diffPts.end()));
sorted[3] = points[minDiffIdx]; // 左下
sorted[1] = points[maxDiffIdx]; // 右上
return sorted;
}
int main() {
cv::Mat img = cv::imread("document.png");
if (img.empty()) {
std::cerr << "画像が読み込めません" << std::endl;
return -1;
}
cv::Mat gray, blur, edges;
// グレースケール化
cv::cvtColor(img, gray, cv::COLOR_BGR2GRAY);
// ぼかしでノイズ除去
cv::GaussianBlur(gray, blur, cv::Size(5, 5), 0);
// Cannyエッジ検出
cv::Canny(blur, edges, 75, 200);
// 輪郭検出
std::vector<std::vector<cv::Point>> contours;
cv::findContours(edges, contours, cv::RETR_LIST, cv::CHAIN_APPROX_SIMPLE);
std::vector<cv::Point> approx;
double maxArea = 0;
std::vector<cv::Point> pageContour;
// 最大の4点輪郭を探す
for (const auto& contour : contours) {
double area = cv::contourArea(contour);
if (area < 1000) continue; // 小さい輪郭は無視
cv::approxPolyDP(contour, approx, 0.02 * cv::arcLength(contour, true),
true);
if (approx.size() == 4 && area > maxArea &&
cv::isContourConvex(approx)) {
maxArea = area;
pageContour = approx;
}
}
if (pageContour.empty()) {
std::cerr << "用紙の輪郭が検出できませんでした\n";
return -1;
}
// 順番を左上、右上、右下、左下に整列
std::vector<cv::Point2f> srcPoints = sortPoints(pageContour);
// 変換後の四隅座標(A4サイズピクセル相当)
cv::Size outputSize(420, 594);
std::vector<cv::Point2f> dstPoints{
cv::Point2f(0, 0), cv::Point2f(outputSize.width - 1, 0),
cv::Point2f(outputSize.width - 1, outputSize.height - 1),
cv::Point2f(0, outputSize.height - 1)};
// 射影変換行列取得
cv::Mat perspectiveMat = cv::getPerspectiveTransform(srcPoints, dstPoints);
cv::Mat warped;
cv::warpPerspective(img, warped, perspectiveMat, outputSize);
cv::imshow("Original", img);
cv::imshow("Detected Edges", edges);
cv::imshow("Warped Document", warped);
cv::waitKey(0);
return 0;
}

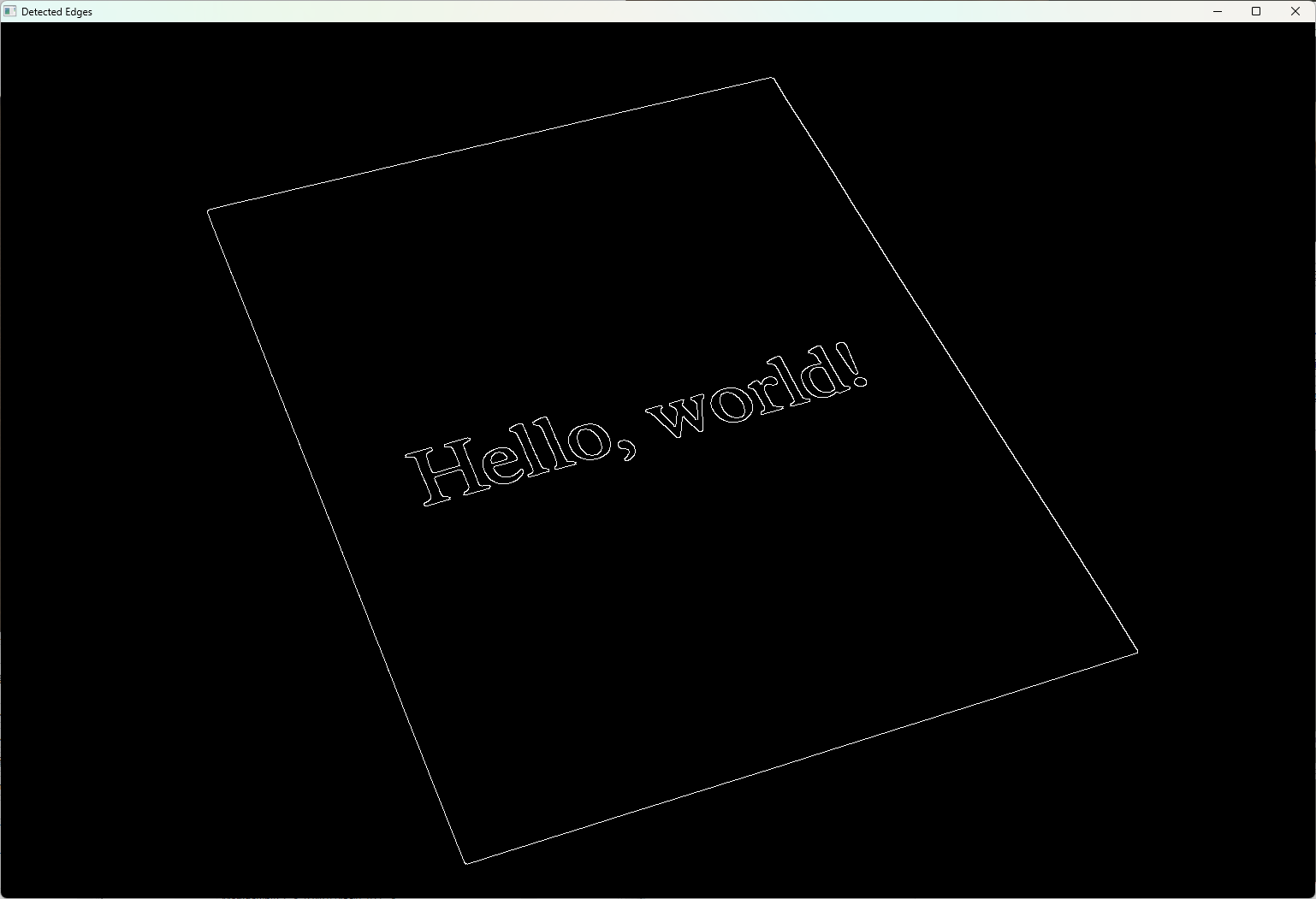

四点変換の典型例
四点変換は、写真で撮影した歪んだドキュメントやホワイトボードの画像を、真上から撮影したように補正する際に使われます。
上記の例では、歪んだ四隅の座標を指定し、A4サイズの長方形に変換しています。
画像ワーピングの応用
画像ワーピングは幾何変換の応用で、画像の形状を変形させる技術です。
アフィン変換や射影変換を使って、画像の一部を引き伸ばしたり、回転・歪み補正を行ったりします。
例えば、顔認識後に目や口の位置を基準に顔の向きを補正したり、パノラマ画像の合成で複数画像をつなぎ合わせる際にワーピングを使います。
また、cv::remap関数を使うと、任意の座標マップを指定してピクセル単位で画像を変形できます。
これにより魚眼補正や特殊効果の実装も可能です。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::imread("sample.jpg");
if (img.empty()) return -1;
cv::Mat map_x(img.size(), CV_32FC1);
cv::Mat map_y(img.size(), CV_32FC1);
// 簡単な左右反転マップを作成
for (int y = 0; y < img.rows; y++) {
for (int x = 0; x < img.cols; x++) {
map_x.at<float>(y, x) = static_cast<float>(img.cols - x - 1);
map_y.at<float>(y, x) = static_cast<float>(y);
}
}
cv::Mat warped;
cv::remap(img, warped, map_x, map_y, cv::INTER_LINEAR);
cv::imshow("Original", img);
cv::imshow("Warped (Flip)", warped);
cv::waitKey(0);
return 0;
}
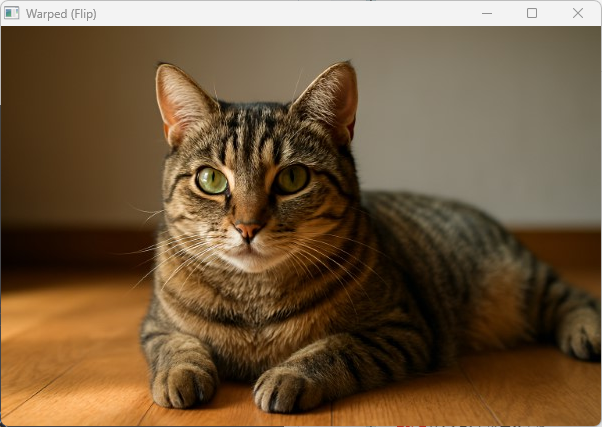
この例では画像を左右反転していますが、座標マップを工夫することで様々な変形が可能です。
画像ワーピングは画像編集やコンピュータビジョンの多くの応用で重要な技術です。
画像の合成
addWeighted によるブレンド
画像の合成でよく使われる手法の一つが、cv::addWeighted関数を使ったブレンド(加重平均)です。
これは2枚の画像を指定した重みで合成し、透過的な重ね合わせやフェード効果を簡単に実現できます。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img1 = cv::imread("image1.jpg");
cv::Mat img2 = cv::imread("image2.jpg");
if (img1.empty() || img2.empty()) return -1;
// 画像サイズを合わせる(img2をimg1のサイズにリサイズ)
cv::resize(img2, img2, img1.size());
cv::Mat blended;
double alpha = 0.7; // img1の重み
double beta = 1.0 - alpha; // img2の重み
// ブレンド処理
cv::addWeighted(img1, alpha, img2, beta, 0.0, blended);
cv::imshow("Image 1", img1);
cv::imshow("Image 2", img2);
cv::imshow("Blended", blended);
cv::waitKey(0);
return 0;
}このコードでは、img1とimg2を70%と30%の割合で合成しています。
addWeightedの第5引数はガンマ補正のオフセットで、通常は0を指定します。
ブレンドは画像のフェードイン・フェードアウトや、複数画像の合成、透過効果のシミュレーションに使われます。
透過PNGの扱い
透過PNGはアルファチャンネルを持つ4チャンネル画像(BGRA)で、透明度情報を含みます。
OpenCVで透過PNGを読み込むにはcv::IMREAD_UNCHANGEDフラグを使い、アルファチャンネルを保持したまま読み込みます。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat img = cv::imread("transparent.png", cv::IMREAD_UNCHANGED);
if (img.empty()) {
std::cerr << "画像が読み込めませんでした。" << std::endl;
return -1;
}
std::cout << "チャンネル数: " << img.channels() << std::endl; // 4ならアルファチャンネルあり
cv::imshow("Transparent PNG", img);
cv::waitKey(0);
return 0;
}アルファチャンネルがある場合、img.channels()は4になります。
通常のIMREAD_COLORではアルファチャンネルは無視され3チャンネルのBGR画像として読み込まれます。
透過PNGを他の画像に合成する際は、アルファチャンネルを利用して透明部分を考慮した合成処理を行う必要があります。
アルファチャンネルとマスク
アルファチャンネルはピクセルごとの透明度を表し、0が完全透明、255が不透明を意味します。
アルファチャンネルを使って画像を合成するには、マスクとして利用し、元画像と背景画像を適切にブレンドします。
以下は透過PNGを背景画像に合成する例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat background = cv::imread("background.jpg");
cv::Mat foreground = cv::imread("transparent.png", cv::IMREAD_UNCHANGED);
if (background.empty() || foreground.empty()) {
std::cerr << "画像が読み込めませんでした。" << std::endl;
return -1;
}
// 背景画像を前景画像のサイズにリサイズ
cv::resize(background, background, foreground.size());
// 前景画像のアルファチャンネルを分離
std::vector<cv::Mat> channels;
cv::split(foreground, channels);
cv::Mat alpha = channels[3]; // アルファチャンネル
// アルファチャンネルを0〜1の範囲に正規化
cv::Mat alpha_f;
alpha.convertTo(alpha_f, CV_32FC1, 1.0 / 255.0);
// 前景のBGRチャネルをfloat型に変換
cv::Mat foreground_rgb;
cv::merge(std::vector<cv::Mat>{channels[0], channels[1], channels[2]}, foreground_rgb);
foreground_rgb.convertTo(foreground_rgb, CV_32FC3, 1.0 / 255.0);
// 背景画像をfloat型に変換
cv::Mat background_f;
background.convertTo(background_f, CV_32FC3, 1.0 / 255.0);
// アルファブレンド
cv::Mat blended = cv::Mat::zeros(foreground.size(), CV_32FC3);
for (int y = 0; y < blended.rows; y++) {
for (int x = 0; x < blended.cols; x++) {
float alpha_val = alpha_f.at<float>(y, x);
cv::Vec3f fg_pixel = foreground_rgb.at<cv::Vec3f>(y, x);
cv::Vec3f bg_pixel = background_f.at<cv::Vec3f>(y, x);
blended.at<cv::Vec3f>(y, x) = fg_pixel * alpha_val + bg_pixel * (1.0f - alpha_val);
}
}
// 表示用に8ビットに変換
blended.convertTo(blended, CV_8UC3, 255.0);
cv::imshow("Background", background);
cv::imshow("Foreground (with alpha)", foreground);
cv::imshow("Blended Image", blended);
cv::waitKey(0);
return 0;
}このコードでは、透過PNGのアルファチャンネルをマスクとして使い、前景と背景をピクセルごとに加重平均しています。
アルファ値が高い部分は前景が強く、低い部分は背景が強く表示されます。
アルファチャンネルを使った合成は、画像編集やAR(拡張現実)アプリケーションで重要な技術です。
OpenCVでの扱い方を理解しておくと、透明度を考慮した自然な画像合成が可能になります。
ドローイング機能
線・円・矩形・ポリライン
OpenCVでは画像上に様々な図形を描画することができます。
主に使われる関数は以下の通りです。
cv::line:線分を描画cv::circle:円を描画cv::rectangle:矩形を描画cv::polylines:複数の点を結ぶポリライン(折れ線)を描画
これらの関数は描画先の画像、座標、色、線の太さなどを指定して使います。
#include <opencv2/opencv.hpp>
int main() {
// 黒い背景の画像を作成
cv::Mat img = cv::Mat::zeros(400, 600, CV_8UC3);
// 線を描画(青色、太さ3)
cv::line(img, cv::Point(50, 50), cv::Point(550, 50), cv::Scalar(255, 0, 0), 3);
// 円を描画(緑色、太さ-1で塗りつぶし)
cv::circle(img, cv::Point(300, 150), 50, cv::Scalar(0, 255, 0), -1);
// 矩形を描画(赤色、太さ2)
cv::rectangle(img, cv::Point(100, 250), cv::Point(500, 350), cv::Scalar(0, 0, 255), 2);
// ポリラインを描画(黄色、閉じた多角形、太さ2)
std::vector<cv::Point> pts = {cv::Point(200, 370), cv::Point(300, 370), cv::Point(350, 390), cv::Point(250, 410)};
cv::polylines(img, pts, true, cv::Scalar(0, 255, 255), 2);
cv::imshow("Drawing", img);
cv::waitKey(0);
return 0;
}このコードでは、青い線、緑の塗りつぶし円、赤い矩形、黄色の閉じたポリラインを描画しています。
cv::ScalarはBGR順で色を指定します。
テキスト描画とフォント設定
画像にテキストを描画するにはcv::putText関数を使います。
フォントの種類やサイズ、色、太さ、線の種類を指定可能です。
#include <opencv2/opencv.hpp>
int main() {
cv::Mat img = cv::Mat::zeros(200, 600, CV_8UC3);
std::string text = "OpenCV Text";
// テキストを描画
cv::putText(img, text, cv::Point(50, 100), cv::FONT_HERSHEY_SIMPLEX,
2.0, cv::Scalar(255, 255, 255), 3, cv::LINE_AA);
cv::imshow("Text", img);
cv::waitKey(0);
return 0;
}主なパラメータは以下の通りです。
- 描画先画像
- 描画する文字列
- 文字列の左下の座標
- フォントタイプ(例:
FONT_HERSHEY_SIMPLEX) - フォントスケール(サイズ)
- 色(BGR)
- 線の太さ
- 線の種類(アンチエイリアスなど)
OpenCV標準のフォントは英数字や一部記号に対応していますが、日本語などのマルチバイト文字はサポートしていません。
日本語テキストの対処法
OpenCVのputTextは日本語を直接描画できないため、以下のような方法で対応します。
- 外部ライブラリを使う
FreeTypeライブラリを利用したcv::freetype::FreeType2モジュールを使うと、TrueTypeフォントで日本語を描画可能です。
ただし、OpenCVのビルド時にFreeTypeサポートを有効にする必要があります。
- OpenCV以外の描画で画像を作成し、合成する
例えば、WindowsのGDI+やQt、Cairoなどで日本語テキストを描画した画像を作成し、OpenCVで読み込んで合成します。
- Pillow(Python)など他言語のライブラリを使う
Python環境ならPillowで日本語テキストを描画し、OpenCVで処理する方法もあります。
- ビットマップフォントを自作して描画
日本語文字をビットマップ化し、OpenCVの画像に手動で描画する方法もありますが手間がかかります。
以下はFreeTypeモジュールを使った例(OpenCVが対応している場合)。
#include <opencv2/opencv.hpp>
#include <opencv2/freetype.hpp>
int main() {
cv::Mat img = cv::Mat::zeros(200, 600, CV_8UC3);
// FreeType2オブジェクトの作成
cv::Ptr<cv::freetype::FreeType2> ft2 = cv::freetype::createFreeType2();
ft2->loadFontData("C:/Windows/Fonts/msgothic.ttc", 0); // フォントファイルのパス
std::string text = "こんにちは、OpenCV!";
// 日本語テキストを描画
ft2->putText(img, text, cv::Point(50, 100), 40, cv::Scalar(255, 255, 255), -1, cv::LINE_AA, true);
cv::imshow("Japanese Text", img);
cv::waitKey(0);
return 0;
}この方法で日本語を含む多言語テキストを自然に描画できます。
環境によってはFreeTypeモジュールのビルドやフォントファイルのパス設定が必要です。
日本語テキスト描画はOpenCV単体では難しいため、用途に応じて外部ツールやライブラリの利用を検討してください。
動画処理
VideoCapture でのファイル読込
OpenCVのcv::VideoCaptureクラスは動画ファイルやカメラデバイスから映像を読み込むために使います。
動画ファイルを読み込む場合は、ファイルパスをコンストラクタやopenメソッドに渡します。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 動画ファイルのパスを指定してVideoCaptureを作成
cv::VideoCapture cap("sample_video.mp4");
if (!cap.isOpened()) {
std::cerr << "動画ファイルを開けませんでした。" << std::endl;
return -1;
}
cv::Mat frame;
while (true) {
// フレームを1枚読み込む
bool ret = cap.read(frame);
if (!ret || frame.empty()) break; // 動画終了または読み込み失敗
cv::imshow("Video Playback", frame);
// 30ms待機し、キー入力があれば終了
if (cv::waitKey(30) >= 0) break;
}
cap.release();
cv::destroyAllWindows();
return 0;
}VideoCaptureは動画のフレームを順に読み込み、readメソッドでcv::Matに格納します。
isOpenedで正常に開けたか確認し、readがfalseを返すと動画の終端に達したことを意味します。
VideoWriter での書き出し
動画の書き出しはcv::VideoWriterクラスを使います。
出力ファイル名、コーデック、フレームレート、フレームサイズを指定して初期化し、writeメソッドでフレームを順に書き込みます。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::VideoCapture cap("sample_video.mp4");
if (!cap.isOpened()) {
std::cerr << "動画ファイルを開けませんでした。" << std::endl;
return -1;
}
int frame_width = static_cast<int>(cap.get(cv::CAP_PROP_FRAME_WIDTH));
int frame_height = static_cast<int>(cap.get(cv::CAP_PROP_FRAME_HEIGHT));
double fps = cap.get(cv::CAP_PROP_FPS);
// 出力ファイル名、コーデック(例:MJPG)、fps、フレームサイズを指定
cv::VideoWriter writer("output.avi", cv::VideoWriter::fourcc('M','J','P','G'), fps, cv::Size(frame_width, frame_height));
if (!writer.isOpened()) {
std::cerr << "動画ファイルの書き込みを開始できませんでした。" << std::endl;
return -1;
}
cv::Mat frame;
while (true) {
bool ret = cap.read(frame);
if (!ret || frame.empty()) break;
// ここでフレーム処理が可能(例:グレースケール変換など)
writer.write(frame); // フレームを書き込み
cv::imshow("Video Playback", frame);
if (cv::waitKey(30) >= 0) break;
}
cap.release();
writer.release();
cv::destroyAllWindows();
return 0;
}fourccは動画コーデックを指定する4文字コードで、MJPGやXVID、H264などがよく使われます。
環境によって対応コーデックが異なるため注意してください。
フレーム処理ループ
動画処理ではフレームごとに画像処理を行うループが基本です。
VideoCaptureでフレームを読み込み、処理し、表示や保存を行います。
while (true) {
bool ret = cap.read(frame);
if (!ret || frame.empty()) break;
// 例:グレースケール変換
cv::Mat gray;
cv::cvtColor(frame, gray, cv::COLOR_BGR2GRAY);
cv::imshow("Processed Frame", gray);
if (cv::waitKey(30) >= 0) break;
}FPS制御と遅延調整
動画の再生速度を制御するためにwaitKeyの待機時間を調整します。
理想的には動画のFPSに合わせて待機時間を設定します。
int fps = static_cast<int>(cap.get(cv::CAP_PROP_FPS));
int delay = 1000 / fps; // ミリ秒単位の待機時間
while (true) {
bool ret = cap.read(frame);
if (!ret || frame.empty()) break;
cv::imshow("Video", frame);
if (cv::waitKey(delay) >= 0) break;
}ただし、処理時間が長い場合は実際のFPSが落ちるため、処理時間を計測して待機時間を調整する方法もあります。
#include <chrono>
while (true) {
auto start = std::chrono::high_resolution_clock::now();
bool ret = cap.read(frame);
if (!ret || frame.empty()) break;
cv::imshow("Video", frame);
auto end = std::chrono::high_resolution_clock::now();
int elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
int wait_time = delay - elapsed;
if (wait_time < 1) wait_time = 1;
if (cv::waitKey(wait_time) >= 0) break;
}この方法で処理時間を考慮したFPS制御が可能です。
カメラ入力のリアルタイム処理
VideoCaptureはカメラデバイスの映像も扱えます。
デバイス番号(通常0が内蔵カメラ)を指定して開き、リアルタイムにフレームを取得・処理します。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::VideoCapture cap(0); // カメラデバイス0を開く
if (!cap.isOpened()) {
std::cerr << "カメラを開けませんでした。" << std::endl;
return -1;
}
cv::Mat frame;
while (true) {
bool ret = cap.read(frame);
if (!ret || frame.empty()) {
std::cerr << "フレームの取得に失敗しました。" << std::endl;
break;
}
// 例:リアルタイムでグレースケール変換
cv::Mat gray;
cv::cvtColor(frame, gray, cv::COLOR_BGR2GRAY);
cv::imshow("Camera", gray);
if (cv::waitKey(30) >= 0) break;
}
cap.release();
cv::destroyAllWindows();
return 0;
}リアルタイム処理では、処理速度が重要です。
重い処理はFPS低下の原因になるため、必要に応じて処理の軽量化やマルチスレッド化を検討してください。
オブジェクト検出の基礎
HaarCascade分類器
HaarCascade分類器は、顔検出などで広く使われている古典的な物体検出手法です。
AdaBoost学習により特徴量を選択し、カスケード構造で高速に検出を行います。
OpenCVには学習済みのXMLファイルが多数用意されており、簡単に利用可能です。
XML分類器の使用手順
- 分類器の読み込み
OpenCVのcv::CascadeClassifierクラスを使い、学習済みのXMLファイルを読み込みます。
カスケード分類器の利用にはカスケードファイルが必要です。
OpenCVをインストールすると、多くの環境ではhaarcascade_frontalface_default.xmlファイルが自動的に含まれています。以下のようなパスに存在することが多いです。
/usr/share/opencv4/haarcascades/haarcascade_frontalface_default.xmlopencv\sources\data\haarcascades\haarcascade_frontalface_default.xmlカスケードファイルをコピーしてカレントディレクトリに配置するなどをして、使える状態にしておきましょう。
- 画像の前処理
入力画像はグレースケールに変換し、検出精度を上げるためにヒストグラム均一化を行うことが多いです。
- 物体検出
detectMultiScaleメソッドで物体の位置を検出します。
検出結果は矩形のリストとして返されます。
- 検出結果の描画
検出した矩形を画像に描画して可視化します。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat img = cv::imread("group_photo.jpg");
if (img.empty()) {
std::cerr << "画像が読み込めませんでした。" << std::endl;
return -1;
}
cv::CascadeClassifier face_cascade;
if (!face_cascade.load("haarcascade_frontalface_default.xml")) {
std::cerr << "分類器の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat gray;
cv::cvtColor(img, gray, cv::COLOR_BGR2GRAY);
cv::equalizeHist(gray, gray);
std::vector<cv::Rect> faces;
face_cascade.detectMultiScale(gray, faces, 1.1, 3, 0, cv::Size(30, 30));
for (const auto& face : faces) {
cv::rectangle(img, face, cv::Scalar(0, 255, 0), 2);
}
cv::imshow("Detected Faces", img);
cv::waitKey(0);
return 0;
}このコードは画像中の顔を検出し、緑色の矩形で囲みます。
detectMultiScaleのパラメータはスケールファクターや最小検出数などで、検出精度と速度のバランスを調整します。
HOG + SVMによる歩行者検出
HOG(Histogram of Oriented Gradients)は画像の局所的な勾配方向の分布を特徴量として抽出し、SVM(Support Vector Machine)で分類する手法です。
OpenCVには学習済みの歩行者検出用HOG+SVMモデルが組み込まれており、簡単に利用できます。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat img = cv::imread("pedestrians.jpg");
if (img.empty()) return -1;
cv::HOGDescriptor hog;
hog.setSVMDetector(cv::HOGDescriptor::getDefaultPeopleDetector());
std::vector<cv::Rect> detections;
hog.detectMultiScale(img, detections);
for (const auto& rect : detections) {
cv::rectangle(img, rect, cv::Scalar(0, 0, 255), 2);
}
cv::imshow("Pedestrian Detection", img);
cv::waitKey(0);
return 0;
}detectMultiScaleは複数スケールで検出を行い、歩行者の位置を矩形で返します。
HOG+SVMは顔検出よりも大きな物体検出に適しており、監視カメラや自動運転の歩行者検出に使われます。
テンプレートマッチング
テンプレートマッチングは、画像中から指定したテンプレート画像と類似する領域を探す手法です。
OpenCVのcv::matchTemplate関数で実装し、類似度マップを作成して最大値や最小値の位置を検出します。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat img = cv::imread("scene.jpg");
cv::Mat templ = cv::imread("template.jpg");
if (img.empty() || templ.empty()) return -1;
cv::Mat result;
cv::matchTemplate(img, templ, result, cv::TM_CCOEFF_NORMED);
double minVal, maxVal;
cv::Point minLoc, maxLoc;
cv::minMaxLoc(result, &minVal, &maxVal, &minLoc, &maxLoc);
// 類似度が最大の位置に矩形を描画
cv::rectangle(img, maxLoc, cv::Point(maxLoc.x + templ.cols, maxLoc.y + templ.rows), cv::Scalar(0, 255, 0), 2);
cv::imshow("Template Matching", img);
cv::waitKey(0);
return 0;
}matchTemplateのメソッドには複数種類があり、TM_CCOEFF_NORMEDは正規化相関係数で類似度を計算します。
テンプレートマッチングは物体の位置検出やパターン認識に使われますが、回転やスケール変化には弱い点があります。
簡易追跡 KalmanFilter
Kalmanフィルタはノイズのある観測データから状態を推定するアルゴリズムで、物体追跡に利用されます。
OpenCVのcv::KalmanFilterクラスで実装可能です。
以下は2次元位置を追跡する簡単な例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
int stateSize = 4; // [x, y, vx, vy]
int measSize = 2; // [x, y]
int contrSize = 0;
cv::KalmanFilter kf(stateSize, measSize, contrSize, CV_32F);
// 状態遷移行列
kf.transitionMatrix = (cv::Mat_<float>(4, 4) <<
1, 0, 1, 0,
0, 1, 0, 1,
0, 0, 1, 0,
0, 0, 0, 1);
cv::setIdentity(kf.measurementMatrix);
cv::setIdentity(kf.processNoiseCov, cv::Scalar::all(1e-4));
cv::setIdentity(kf.measurementNoiseCov, cv::Scalar::all(1e-1));
cv::setIdentity(kf.errorCovPost, cv::Scalar::all(1));
// 初期状態
cv::Mat state(stateSize, 1, CV_32F);
cv::Mat measurement(measSize, 1, CV_32F);
measurement.setTo(cv::Scalar(0));
// 仮の観測データ(例として直線的に移動)
for (int i = 0; i < 50; i++) {
// 予測
cv::Mat prediction = kf.predict();
cv::Point predictPt(prediction.at<float>(0), prediction.at<float>(1));
// 観測値(ノイズ付き)
measurement.at<float>(0) = i + static_cast<float>(rand() % 5 - 2);
measurement.at<float>(1) = i + static_cast<float>(rand() % 5 - 2);
// 更新
kf.correct(measurement);
std::cout << "予測位置: (" << predictPt.x << ", " << predictPt.y << "), "
<< "観測位置: (" << measurement.at<float>(0) << ", " << measurement.at<float>(1) << ")" << std::endl;
}
return 0;
}この例では、物体の位置と速度を状態として持ち、ノイズのある観測値から状態を推定しています。
Kalmanフィルタはリアルタイム追跡やセンサーデータの補正に広く使われています。
深層学習を利用した推論
cv::dnn モジュール概要
OpenCVのcv::dnnモジュールは、深層学習(Deep Neural Network)モデルの読み込みと推論を行うための機能を提供しています。
TensorFlow、Caffe、Darknet、ONNXなど様々なフレームワークで学習されたモデルを読み込み、画像認識や物体検出、セグメンテーションなどのタスクに利用可能です。
cv::dnnはCPUだけでなく、OpenCLやCUDAを利用したGPUアクセラレーションにも対応しており、高速な推論が可能です。
モデルの読み込みから前処理、推論、後処理まで一連の流れをサポートしているため、深層学習を用いた画像処理をC++で手軽に実装できます。
ONNXモデルの読み込み
ONNX(Open Neural Network Exchange)は異なる深層学習フレームワーク間でモデルを共有するための標準フォーマットです。
OpenCVのcv::dnnモジュールはONNXモデルの読み込みに対応しており、以下のようにしてモデルをロードします。
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <iostream>
int main() {
// ONNXモデルのパス
std::string modelPath = "model.onnx";
// モデルの読み込み
cv::dnn::Net net = cv::dnn::readNetFromONNX(modelPath);
if (net.empty()) {
std::cerr << "モデルの読み込みに失敗しました。" << std::endl;
return -1;
}
std::cout << "モデルが正常に読み込まれました。" << std::endl;
return 0;
}モデルの読み込み後、netオブジェクトを使って推論を行います。
GPUを使いたい場合は、net.setPreferableBackendやnet.setPreferableTargetでバックエンドやターゲットを指定できます。
net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);これによりCUDA対応GPUで高速推論が可能になります。
推論結果の後処理
推論結果は通常、cv::Mat形式の出力テンソルとして得られますが、そのままでは意味のある情報になっていないことが多いため、後処理が必要です。
後処理の内容はモデルの種類やタスクによって異なりますが、代表的な例を紹介します。
画像分類の場合
分類モデルの出力はクラスごとのスコア(確率)であることが多いです。
最大スコアのインデックスを取得して予測クラスを決定します。
cv::Mat inputBlob = cv::dnn::blobFromImage(inputImage, 1.0/255.0, cv::Size(224, 224), cv::Scalar(), true, false);
net.setInput(inputBlob);
cv::Mat prob = net.forward(); // 出力は1xNの行列
// 最大スコアのインデックスを取得
cv::Point classIdPoint;
double confidence;
cv::minMaxLoc(prob.reshape(1,1), 0, &confidence, 0, &classIdPoint);
int classId = classIdPoint.x;
std::cout << "予測クラスID: " << classId << ", 確信度: " << confidence << std::endl;物体検出の場合
物体検出モデル(例:YOLO、SSD)の出力は複数の検出結果(バウンディングボックス、クラスID、信頼度)を含みます。
出力テンソルからこれらを抽出し、信頼度の閾値でフィルタリング、非最大抑制(NMS)で重複検出を除去します。
// 推論結果の例(モデルによって異なる)
cv::Mat detections = net.forward();
// detectionsの形状や内容はモデル依存
// ここでは例として、各検出は[batch_id, class_id, confidence, x, y, width, height]の形式と仮定
float confidenceThreshold = 0.5f;
std::vector<int> classIds;
std::vector<float> confidences;
std::vector<cv::Rect> boxes;
for (int i = 0; i < detections.rows; ++i) {
float conf = detections.at<float>(i, 2);
if (conf > confidenceThreshold) {
int classId = static_cast<int>(detections.at<float>(i, 1));
int left = static_cast<int>(detections.at<float>(i, 3) * inputImage.cols);
int top = static_cast<int>(detections.at<float>(i, 4) * inputImage.rows);
int width = static_cast<int>(detections.at<float>(i, 5) * inputImage.cols);
int height = static_cast<int>(detections.at<float>(i, 6) * inputImage.rows);
classIds.push_back(classId);
confidences.push_back(conf);
boxes.push_back(cv::Rect(left, top, width, height));
}
}
// 非最大抑制で重複を除去
std::vector<int> indices;
cv::dnn::NMSBoxes(boxes, confidences, confidenceThreshold, 0.4, indices);
for (int idx : indices) {
cv::rectangle(inputImage, boxes[idx], cv::Scalar(0, 255, 0), 2);
std::string label = "Class " + std::to_string(classIds[idx]) + ": " + cv::format("%.2f", confidences[idx]);
cv::putText(inputImage, label, boxes[idx].tl(), cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 255, 0), 1);
}
cv::imshow("Detections", inputImage);
cv::waitKey(0);このように、推論結果の後処理はモデルの出力形式に合わせて実装する必要があります。
OpenCVのcv::dnnモジュールはNMSなどの便利な関数も提供しているため、活用すると効率的です。
特徴量抽出とマッチング
SIFT・SURF・ORBの比較
画像の特徴量抽出は、物体認識や画像マッチング、ステッチングなど多くのコンピュータビジョン応用で重要な役割を果たします。
代表的な特徴量検出器・記述子としてSIFT、SURF、ORBがあります。
それぞれの特徴と違いを比較します。
| 特徴量 | 特徴・利点 | 欠点・制約 |
|---|---|---|
| SIFT | スケール不変性、回転不変性に優れ、高精度な特徴量。 | 特許問題があり、OpenCVの非無料モジュールに含まれます。計算コストが高いでしょう。 |
| SURF | SIFTより高速で、スケール・回転不変性を持ちます。 | こちらも特許問題あり。SIFTより高速だがORBより遅い。 |
| ORB | 無料で高速。回転不変性あり。バイナリ記述子でマッチングが高速。 | スケール不変性は限定的。SIFT/SURFほど精度は高くない。 |
OpenCVではSIFTとSURFはxfeatures2dモジュールにあり、別途インストールが必要です。
ORBは標準モジュールで利用可能です。
以下はORBを使った特徴量検出と記述子計算の例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat img = cv::imread("image.jpg", cv::IMREAD_GRAYSCALE);
if (img.empty()) return -1;
// ORB検出器の作成
cv::Ptr<cv::ORB> orb = cv::ORB::create();
std::vector<cv::KeyPoint> keypoints;
cv::Mat descriptors;
// 特徴点検出と記述子計算
orb->detectAndCompute(img, cv::noArray(), keypoints, descriptors);
// 特徴点を描画
cv::Mat outImg;
cv::drawKeypoints(img, keypoints, outImg, cv::Scalar::all(-1), cv::DrawMatchesFlags::DRAW_RICH_KEYPOINTS);
cv::imshow("ORB Keypoints", outImg);
cv::waitKey(0);
return 0;
}BFMatcher と FLANN
特徴量のマッチングは、2つの画像間で対応する特徴点を見つける処理です。
OpenCVでは主にBFMatcher(Brute-Force Matcher)とFlannBasedMatcher(FLANN)を使います。
- BFMatcher
全ての特徴点の組み合わせを比較し、最も近い特徴点を探します。
距離計算は記述子の種類に応じてNORM_L2(SIFT/SURF)やNORM_HAMMING(ORB)を指定します。
単純で確実ですが、大量の特徴点では計算コストが高くなります。
- FlannBasedMatcher
高速近似最近傍探索アルゴリズムを使い、大規模な特徴点集合でも高速にマッチング可能です。
SIFTやSURFのような浮動小数点記述子に適しています。
ORBのようなバイナリ記述子には適さない場合があります。
以下はORB特徴量のBFMatcherによるマッチング例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat img1 = cv::imread("image1.jpg", cv::IMREAD_GRAYSCALE);
cv::Mat img2 = cv::imread("image2.jpg", cv::IMREAD_GRAYSCALE);
if (img1.empty() || img2.empty()) return -1;
cv::Ptr<cv::ORB> orb = cv::ORB::create();
std::vector<cv::KeyPoint> kp1, kp2;
cv::Mat desc1, desc2;
orb->detectAndCompute(img1, cv::noArray(), kp1, desc1);
orb->detectAndCompute(img2, cv::noArray(), kp2, desc2);
// BFMatcherの作成(Hamming距離)
cv::BFMatcher matcher(cv::NORM_HAMMING);
std::vector<cv::DMatch> matches;
matcher.match(desc1, desc2, matches);
// 距離でソートし上位50件を抽出
std::sort(matches.begin(), matches.end(), [](const cv::DMatch& a, const cv::DMatch& b) {
return a.distance < b.distance;
});
matches.resize(50);
cv::Mat imgMatches;
cv::drawMatches(img1, kp1, img2, kp2, matches, imgMatches);
cv::imshow("Matches", imgMatches);
cv::waitKey(0);
return 0;
}画像ステッチングの基本
画像ステッチングは複数の画像をつなぎ合わせてパノラマ画像を作成する技術です。
特徴量抽出とマッチングを用いて画像間の対応点を求め、幾何変換(ホモグラフィ)を推定して画像を合成します。
基本的な流れは以下の通りです。
- 特徴量検出と記述子計算
各画像でSIFTやORBなどを使い特徴点を抽出。
- 特徴点マッチング
BFMatcherやFLANNで画像間の対応点を見つける。
- 外れ値除去とホモグラフィ推定
RANSACアルゴリズムで外れたマッチングを除去し、画像間の射影変換行列(ホモグラフィ)を計算。
- 画像のワーピングと合成
ホモグラフィを使い画像を変形し、重なり部分をブレンドしてつなぎ合わせます。
OpenCVにはcv::Stitcherクラスがあり、これらの処理をまとめて簡単に実行できます。
#include <opencv2/opencv.hpp>
#include <iostream>
#include <vector>
int main() {
std::vector<cv::Mat> images;
images.push_back(cv::imread("img1.jpg"));
images.push_back(cv::imread("img2.jpg"));
if (images[0].empty() || images[1].empty()) return -1;
cv::Mat pano;
cv::Ptr<cv::Stitcher> stitcher = cv::Stitcher::create(cv::Stitcher::PANORAMA);
cv::Stitcher::Status status = stitcher->stitch(images, pano);
if (status != cv::Stitcher::OK) {
std::cerr << "ステッチングに失敗しました。エラーコード: " << int(status) << std::endl;
return -1;
}
cv::imshow("Panorama", pano);
cv::waitKey(0);
return 0;
}このコードは2枚の画像をパノラマ合成し、結果を表示します。
cv::Stitcherは内部で特徴量抽出、マッチング、ホモグラフィ推定、ブレンディングを自動で行います。
特徴量抽出とマッチングは画像ステッチングの基盤技術であり、精度や速度の向上が高品質なパノラマ作成に直結します。
パフォーマンス向上策
Releaseビルド最適化とOpenCL
C++でOpenCVを使う際、パフォーマンスを最大限に引き出すためには、まずReleaseビルドでのコンパイルが必須です。
Debugビルドはデバッグ情報や安全チェックが多く含まれるため、処理速度が大幅に低下します。
Visual StudioやCMakeなどのビルド環境で必ずReleaseモードを選択してください。
さらにOpenCVはOpenCLを利用したハードウェアアクセラレーションをサポートしています。
OpenCLはCPUやGPU、その他のアクセラレータ上で並列処理を行うためのフレームワークで、OpenCVの多くの関数はOpenCL対応版が用意されています。
OpenCLを有効にするには、OpenCVをビルドする際にWITH_OPENCL=ONを指定し、実行時にOpenCLが利用可能な環境であれば自動的にアクセラレーションが有効になります。
プログラム内で明示的にOpenCLの利用を制御することも可能です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
if (cv::ocl::haveOpenCL()) {
cv::ocl::Context context;
if (context.create(cv::ocl::Device::TYPE_GPU)) {
std::cout << "OpenCL GPUデバイスが利用可能です: " << context.device(0).name() << std::endl;
cv::ocl::setUseOpenCL(true);
} else {
std::cout << "OpenCL GPUデバイスが見つかりません。" << std::endl;
cv::ocl::setUseOpenCL(false);
}
} else {
std::cout << "OpenCLはサポートされていません。" << std::endl;
cv::ocl::setUseOpenCL(false);
}
// 以降のOpenCV関数はOpenCL対応版があれば自動的に高速化される
return 0;
}OpenCL対応関数はcv::UMat型を使うとより効果的です。
UMatは内部でOpenCLメモリを管理し、CPUとGPU間のデータ転送を最適化します。
cv::UMat src, dst;
cv::imread("image.jpg").copyTo(src);
cv::GaussianBlur(src, dst, cv::Size(5,5), 1.5);
cv::imshow("Blurred", dst);
cv::waitKey(0);このようにUMatを使うだけでOpenCLアクセラレーションが利用されるため、パフォーマンス向上に繋がります。
G-APIによる並列化
OpenCVのG-API(Graph API)は、画像処理パイプラインをグラフ構造で表現し、最適化・並列化を自動で行う新しいAPIです。
複雑な処理を効率的に実行でき、CPUやGPU、FPGAなど複数のハードウェアに対応しています。
G-APIの特徴は以下の通りです。
- 遅延評価:処理グラフを構築し、必要なタイミングでまとめて実行
- 最適化:不要な中間データの削減や計算の統合を自動で行います
- 並列化:複数コアやGPUを活用し高速化
- ハードウェア抽象化:同じコードで異なるデバイスに対応
簡単なG-APIの例を示します。
#include <opencv2/opencv.hpp>
#include <opencv2/gapi.hpp>
#include <opencv2/gapi/core.hpp>
#include <opencv2/gapi/imgproc.hpp>
int main() {
cv::Mat img = cv::imread("image.jpg");
if (img.empty()) return -1;
// G-APIの入力と出力を定義
cv::GMat in;
cv::GMat blurred = cv::gapi::blur(in, cv::Size(5,5));
// グラフをコンパイル
auto pipeline = cv::GComputation(in, blurred).compile();
cv::Mat out;
pipeline.apply(img, out);
cv::imshow("G-API Blurred", out);
cv::waitKey(0);
return 0;
}この例では、blur処理をG-APIで定義し、最適化されたパイプラインとして実行しています。
複数の処理を組み合わせることで、より大きなパフォーマンス向上が期待できます。
メモリコピー削減の工夫
画像処理のパフォーマンスを上げるには、不要なメモリコピーを減らすことが非常に重要です。
OpenCVのcv::Matは参照カウント方式でコピー時にデータを共有しますが、明示的なコピーや変換でメモリ転送が発生することがあります。
以下のポイントに注意してください。
- 参照共有を活用する
cv::Matの代入は浅いコピー(参照共有)なので、コピーコストはほぼゼロです。
不要なclone()やcopyTo()は避けます。
- ROIやサブマトリクスは参照で扱う
画像の一部を切り出す際はMat roi = img(cv::Rect(...));のように参照を使い、コピーを減らす。
UMatを使ったOpenCLアクセラレーション
UMatはCPUとGPU間のメモリ転送を最適化し、無駄なコピーを減らす。
- データ型の変換を最小限に
convertToやcvtColorなどの変換は必要な時だけ行い、複数回の変換は避けます。
- 関数チェーンの工夫
複数の処理を連続して行う場合、中間結果を保存せずに一気に処理する方法を検討します。
例えば、ROIをコピーせずに参照で扱う例:
cv::Mat img = cv::imread("image.jpg");
cv::Rect roi_rect(50, 50, 100, 100);
cv::Mat roi = img(roi_rect); // 参照のみ、コピーなし
// roiに対する処理は元画像に反映される
cv::GaussianBlur(roi, roi, cv::Size(5,5), 1.5);このようにメモリコピーを減らすことで、特に大きな画像やリアルタイム処理でのパフォーマンスが大幅に向上します。
デバッグと可視化
imshow 以外の表示手段
OpenCVのcv::imshowは画像を簡単に表示できる便利な関数ですが、GUI環境がない場合やより柔軟な表示が必要な場合は他の手段を検討します。
- 画像ファイルへの保存
cv::imwriteで画像をファイルに保存し、外部ビューアで確認する方法です。
GUIが使えない環境やログとして画像を残したい場合に有効です。
cv::imwrite("debug_output.png", img);- OpenCVのQtバックエンドを利用
OpenCVをQtサポート付きでビルドすると、cv::imshowより高機能なウィンドウ操作が可能です。
ズームやスクロール、複数画像の同時表示などができます。
- 外部GUIライブラリとの連携
QtやwxWidgets、Dear ImGuiなどのGUIライブラリを使い、OpenCVの画像をウィジェットに描画して高度なインタラクションを実装可能です。
- コンソールへの数値出力
画像のピクセル値や特徴量の統計情報をstd::coutで出力し、数値的にデバッグする方法もあります。
- PythonやJupyter Notebookとの連携
C++で処理した結果をPythonに渡し、Matplotlibなどで可視化する手法もあります。
ログ出力と例外処理
OpenCVの関数はエラー時に例外を投げることがあります。
C++のtry-catch構文で例外を捕捉し、適切にログを出力して原因解析に役立てます。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
try {
cv::Mat img = cv::imread("nonexistent.jpg");
if (img.empty()) throw std::runtime_error("画像が読み込めませんでした。");
// 画像処理コード
}
catch (const cv::Exception& e) {
std::cerr << "OpenCV例外: " << e.what() << std::endl;
return -1;
}
catch (const std::exception& e) {
std::cerr << "標準例外: " << e.what() << std::endl;
return -1;
}
catch (...) {
std::cerr << "不明な例外が発生しました。" << std::endl;
return -1;
}
return 0;
}また、OpenCVは内部でログレベルを設定でき、詳細な情報を取得可能です。
環境変数OPENCV_LOG_LEVELを設定したり、cv::utils::logging名前空間の関数で制御します。
cv::utils::logging::setLogLevel(cv::utils::logging::LOG_LEVEL_DEBUG);ログ出力は問題の切り分けやパフォーマンス解析に役立ちます。
assert での検証
assertはプログラムの前提条件や不変条件を検証するためのマクロで、デバッグ時に有効活用するとバグの早期発見に繋がります。
OpenCVの関数呼び出し前に入力の妥当性をチェックするのに使います。
#include <opencv2/opencv.hpp>
#include <cassert>
int main() {
cv::Mat img = cv::imread("image.jpg");
assert(!img.empty() && "画像が空です。読み込みに失敗しています。");
// 画像サイズが期待通りか検証
assert(img.cols > 0 && img.rows > 0);
// 画像処理コード
return 0;
}assertは条件が偽の場合にプログラムを停止し、エラーメッセージを表示します。
リリースビルドでは無効化されるため、デバッグ専用の検証に適しています。
OpenCV内部でも多くの関数でCV_Assertマクロが使われており、引数のチェックや前提条件の検証に役立っています。
自作コードでも同様の使い方をすると堅牢なプログラムになります。
便利なユーティリティ関数
タイマー計測 TickMeter
OpenCVのcv::TickMeterは、処理時間の計測を簡単に行えるクラスです。
複数回の計測をまとめて行い、平均時間や合計時間を取得できます。
パフォーマンスのボトルネック解析や処理速度の比較に便利です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::TickMeter tm;
tm.start();
// 計測したい処理(例:画像のガウシアンブラー)
cv::Mat img = cv::imread("sample.jpg");
if (img.empty()) return -1;
cv::Mat blurred;
for (int i = 0; i < 100; i++) {
cv::GaussianBlur(img, blurred, cv::Size(5, 5), 1.5);
}
tm.stop();
std::cout << "処理時間(100回): " << tm.getTimeMilli() << " ms" << std::endl;
std::cout << "平均処理時間: " << tm.getTimeMilli() / 100.0 << " ms" << std::endl;
return 0;
}start()とstop()で計測を開始・停止し、getTimeMilli()でミリ秒単位の経過時間を取得します。
reset()で計測値をリセット可能です。
YAML/JSON入出力 FileStorage
OpenCVのcv::FileStorageは、YAMLやJSON形式でデータの読み書きを行うためのクラスです。
設定ファイルやパラメータの保存、行列やベクトルの永続化に使えます。
書き込み例(YAML形式)
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::FileStorage fs("config.yaml", cv::FileStorage::WRITE);
if (!fs.isOpened()) {
std::cerr << "ファイルを開けませんでした。" << std::endl;
return -1;
}
int threshold = 100;
double scale = 1.5;
cv::Mat cameraMatrix = (cv::Mat_<double>(3,3) << 1000, 0, 320, 0, 1000, 240, 0, 0, 1);
fs << "threshold" << threshold;
fs << "scale" << scale;
fs << "camera_matrix" << cameraMatrix;
fs.release();
std::cout << "設定を書き込みました。" << std::endl;
return 0;
}読み込み例
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::FileStorage fs("config.yaml", cv::FileStorage::READ);
if (!fs.isOpened()) {
std::cerr << "ファイルを開けませんでした。" << std::endl;
return -1;
}
int threshold;
double scale;
cv::Mat cameraMatrix;
fs["threshold"] >> threshold;
fs["scale"] >> scale;
fs["camera_matrix"] >> cameraMatrix;
fs.release();
std::cout << "threshold: " << threshold << std::endl;
std::cout << "scale: " << scale << std::endl;
std::cout << "camera_matrix:\n" << cameraMatrix << std::endl;
return 0;
}YAML/JSONは人間にも読みやすく、設定ファイルや実験データの保存に適しています。
コマンドライン引数 CommandLineParser
OpenCVのcv::CommandLineParserは、コマンドライン引数の解析を簡単に行うためのクラスです。
引数の存在チェックや値の取得、ヘルプメッセージの表示が容易にできます。
#include <opencv2/opencv.hpp>
#include <iostream>
const char* keys =
"{help h usage ? | | ヘルプメッセージを表示}"
"{input i | | 入力画像ファイルのパス}"
"{threshold t |128 | 二値化の閾値}";
int main(int argc, char* argv[]) {
cv::CommandLineParser parser(argc, argv, keys);
parser.about("OpenCV CommandLineParser Example");
if (parser.has("help")) {
parser.printMessage();
return 0;
}
std::string inputFile = parser.get<std::string>("input");
int threshold = parser.get<int>("threshold");
if (!parser.check()) {
parser.printErrors();
return -1;
}
if (inputFile.empty()) {
std::cerr << "入力ファイルを指定してください。" << std::endl;
return -1;
}
cv::Mat img = cv::imread(inputFile, cv::IMREAD_GRAYSCALE);
if (img.empty()) {
std::cerr << "画像が読み込めませんでした。" << std::endl;
return -1;
}
cv::Mat binary;
cv::threshold(img, binary, threshold, 255, cv::THRESH_BINARY);
cv::imshow("Binary Image", binary);
cv::waitKey(0);
return 0;
}この例では、--inputまたは-iで入力画像ファイルを指定し、--thresholdまたは-tで二値化の閾値を指定できます。
--helpでヘルプメッセージを表示します。
CommandLineParserを使うと、複雑なコマンドライン引数の処理を簡潔に実装でき、ユーザーフレンドリーなアプリケーション開発に役立ちます。
よくあるエラーと対処法
画像読み込み失敗
OpenCVで画像を読み込む際にcv::imreadが空のcv::Matを返すことがあります。
これは主に以下の原因によります。
- ファイルパスの誤り
ファイル名やパスが間違っている、またはファイルが存在しない場合。
相対パスを使う場合は実行ディレクトリに注意が必要です。
- 対応していない画像形式
OpenCVがサポートしていない形式や破損したファイルの場合。
- 権限不足
ファイルにアクセス権限がない場合。
対処法としては、読み込み直後にempty()でチェックし、失敗時はエラーメッセージを表示して処理を中断します。
cv::Mat img = cv::imread("image.jpg");
if (img.empty()) {
std::cerr << "画像の読み込みに失敗しました。ファイルパスを確認してください。" << std::endl;
return -1;
}また、絶対パスを使うか、実行環境のカレントディレクトリを確認すると良いでしょう。
サイズ不一致
画像処理で複数の画像を扱う際、サイズが異なるとエラーや意図しない結果が発生します。
例えば、画像の加算やブレンド、マスク処理でサイズが合っていないと例外が投げられます。
対処法は以下の通りです。
- サイズを揃える
cv::resizeで画像サイズを統一します。
if (img1.size() != img2.size()) {
cv::resize(img2, img2, img1.size());
}- ROIの範囲チェック
ROI(領域選択)を使う場合は、範囲が画像サイズ内に収まっているか確認します。
- マスクのサイズ確認
マスク画像は対象画像と同じサイズ・チャンネル数である必要があります。
サイズ不一致は処理の前に必ずチェックし、必要に応じてリサイズやクロップを行うことが重要です。
データ型ミスマッチ
OpenCVのcv::Matは様々なデータ型(CV_8UC3、CV_32FC1など)を扱いますが、異なる型同士で演算や関数呼び出しを行うとエラーや不正な結果になります。
よくある例:
- 8ビット符号なし整数画像と浮動小数点画像の混在
- 1チャンネル画像と3チャンネル画像の混同
- 関数の引数に期待される型と異なる型を渡す
対処法:
- 型を統一する
convertToで型変換を行います。
cv::Mat img8u, img32f;
img8u.convertTo(img32f, CV_32F, 1.0 / 255.0);- チャンネル数を確認する
channels()でチャンネル数をチェックし、必要に応じてcvtColorで変換。
- 関数の仕様を確認する
OpenCVのドキュメントで関数の入力型を確認し、適切な型を渡します。
型ミスマッチはバグの原因になりやすいので、デバッグ時に型情報をログ出力するのも有効です。
共有メモリの落とし穴
OpenCVのcv::Matは参照カウント方式でメモリを共有します。
これによりコピー時のコストが低減されますが、意図せずデータが共有されてしまい、元画像が変更されることがあります。
例えば、以下のようなコードはimg2の変更がimg1に影響します。
cv::Mat img1 = cv::imread("image.jpg");
cv::Mat img2 = img1; // 参照を共有
img2(cv::Rect(0, 0, 100, 100)).setTo(cv::Scalar(0, 0, 255)); // img1も変わる対処法:
- 明示的にコピーを作る
clone()やcopyTo()を使い、独立したメモリ領域を確保します。
cv::Mat img2 = img1.clone();- 共有の影響を理解する
参照共有は高速化に有効なので、必要に応じて使い分けます。
- 関数の戻り値や引数の扱いに注意
関数がMatを返す場合、内部で共有されていることが多いので、変更前にコピーが必要か検討します。
共有メモリの仕組みを理解しないと、バグの原因や予期せぬ動作につながるため、特に複雑な処理や並列処理時は注意が必要です。
まとめ
本記事では、C++とOpenCVを使った画像処理の基本から応用まで幅広く解説しました。
画像の読み込み・表示、色空間変換、フィルタリング、エッジ検出、輪郭解析、幾何変換、動画処理、深層学習推論、特徴量抽出、パフォーマンス最適化、デバッグ手法、便利なユーティリティ関数、よくあるエラー対処法、さらには学習リソースやOSS貢献の方法まで網羅しています。
これらを活用することで、OpenCVの基礎を効率的に習得し、実践的な画像処理アプリケーション開発に役立てられます。