【C++】OpenCVで実現する自動化ツールの作り方と開発ステップ
C++とOpenCVで自動化ツールを作るには、まずvcpkgやCMakeでOpenCVを導入し、cv::Matで画像を読み込んで関数を組み合わせ処理フローを関数化します。
ループやイベント駆動でバッチ実行を整え、Python連携やJSON設定で柔軟性を持たせ、最後にCMakeのinstallやGitHub Actionsでビルドも自動化すると保守が楽になります。
ゴールとユースケース
C++とOpenCVを活用した自動化ツールの開発において、最初に明確にしておきたいのが「ゴール」と「ユースケース」です。
これらを整理することで、開発の方向性が定まり、効率的に設計や実装を進められます。
ここでは、想定シナリオの整理、自動化対象タスクの分類、処理スループットと品質の指標設定について詳しく解説します。
想定シナリオの整理
自動化ツールを作る際には、どのような場面で使われるのか、具体的なシナリオを想定することが重要です。
シナリオを明確にすることで、必要な機能や性能要件が見えてきます。
例えば、以下のようなシナリオが考えられます。
- 工場の検査ラインでの不良品検出
カメラで撮影した製品画像をリアルタイムで解析し、不良品を自動的に判別します。
→ 高速処理と高い検出精度が求められます。
- 大量の画像データの一括処理
研究やマーケティングで収集した画像を一括でリサイズや切り抜き、特徴抽出を行います。
→ バッチ処理での安定性と柔軟なパラメータ設定が重要です。
- ユーザーが操作するGUIツール
画像の編集や解析をユーザーが直感的に操作できるようにします。
→ 使いやすいUI設計とリアルタイムプレビューが必要です。
これらのシナリオを整理すると、ツールの設計方針が見えてきます。
例えば、リアルタイム処理が必要な場合はマルチスレッドやGPU活用を検討し、バッチ処理ならば安定性やログ出力に注力します。
自動化対象タスクの分類
自動化ツールで扱う画像処理タスクは多岐にわたります。
ここでは代表的なタスクを分類し、それぞれの特徴を整理します。
| タスク分類 | 内容例 | 特徴・ポイント |
|---|---|---|
| 画像の前処理 | リサイズ、トリミング、色変換 | 処理が軽量で高速化しやすい |
| ノイズ除去 | 平滑化、メディアンフィルタ | 画像品質向上のための重要なステップ |
| 特徴抽出 | エッジ検出、コーナー検出 | 後続の解析に必要な情報を抽出 |
| 物体検出 | Haar Cascade、YOLOなど | 高度なアルゴリズムを用いることが多い |
| 形状解析 | 輪郭抽出、面積・周囲長計測 | 形状の特徴を数値化し判定に利用 |
| 画像合成・出力 | オーバーレイ描画、動画生成 | 結果の可視化や保存に関わる処理 |
たとえば、工場の検査ラインでは「物体検出」と「形状解析」が中心となり、研究用途では「特徴抽出」や「画像の前処理」が多用されます。
ツールの目的に応じて、どのタスクを自動化するかを明確にしましょう。
処理スループットと品質の指標設定
自動化ツールの性能を評価するためには、処理スループット(処理速度)と品質(精度や信頼性)の指標を設定することが欠かせません。
これらの指標は、開発中のチューニングや最終評価に役立ちます。
処理スループットの指標例
- フレームレート(fps)
動画やリアルタイム処理の場合、1秒あたりに処理できるフレーム数を計測します。
例えば、30fps以上を目標にすることが多いです。
- バッチ処理時間
大量の画像を一括処理する場合、1枚あたりの平均処理時間や全体の処理時間を測定します。
- CPU/GPU使用率
リソースの効率的な利用を確認し、ボトルネックを特定します。
品質の指標例
- 検出精度(Accuracy)
物体検出や分類タスクでは、正しく検出・分類できた割合を示します。
- 誤検出率(False Positive Rate)
不良品検出などで誤って良品を不良品と判定する割合を抑えることが重要です。
- 画像品質評価
ノイズ除去や前処理の効果をPSNR(ピーク信号対雑音比)やSSIM(構造類似度指数)で評価します。
これらの指標は、開発初期に目標値を設定し、実装段階で計測・改善を繰り返すことで、最適なバランスを見つけられます。
これらの「ゴールとユースケース」の整理は、C++とOpenCVで自動化ツールを作る際の土台となります。
次の設計や実装フェーズで迷わないためにも、具体的なシナリオやタスク、性能指標をしっかり決めておきましょう。
要件定義
機能要件
入力形式と出力形式
自動化ツールの入力形式は、対象とする画像や動画の種類に応じて決めます。
OpenCVは多様な画像フォーマットに対応しているため、一般的にはJPEG、PNG、BMPなどの静止画ファイルや、AVI、MP4などの動画ファイルを扱います。
入力形式の選定は、処理対象の環境や用途に合わせて行います。
例えば、工場の検査ラインでリアルタイムにカメラ映像を処理する場合は、カメラからのライブストリーム(cv::VideoCaptureを利用)を入力とします。
一方で、研究用途のバッチ処理では、フォルダ内の複数の画像ファイルを順次読み込む形が多いです。
出力形式は、処理結果の用途に応じて決めます。
画像処理結果を保存する場合は、加工後の画像ファイルや動画ファイルとして出力します。
OpenCVのcv::imwriteやcv::VideoWriterを使い、JPEGやPNG、MP4などの形式で保存可能です。
また、解析結果の数値データや検出結果をCSVやJSON形式で出力することもあります。
これにより、他のシステムや分析ツールと連携しやすくなります。
以下は、画像ファイルの読み込みと保存の簡単な例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 画像を読み込む
cv::Mat inputImage = cv::imread("input.jpg");
if (inputImage.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// 画像をグレースケールに変換
cv::Mat grayImage;
cv::cvtColor(inputImage, grayImage, cv::COLOR_BGR2GRAY);
// 画像を保存する
if (!cv::imwrite("output.png", grayImage)) {
std::cerr << "画像の保存に失敗しました。" << std::endl;
return -1;
}
std::cout << "画像処理が完了しました。" << std::endl;
return 0;
}画像処理が完了しました。この例ではJPEG形式の画像を読み込み、グレースケール変換後にPNG形式で保存しています。
用途に応じてフォーマットを選択してください。
バッチ処理とリアルタイム処理
自動化ツールの処理形態は大きく分けてバッチ処理とリアルタイム処理に分類されます。
どちらを採用するかで設計や実装の方針が変わります。
バッチ処理は、複数の画像や動画ファイルをまとめて処理する方式です。
処理時間は多少長くても問題なく、安定性や再現性が重視されます。
例えば、過去に撮影した大量の画像を一括で解析し、結果をレポートとして出力する場合に適しています。
バッチ処理では、ファイルの読み込みや書き込みを効率化するために、ファイル名のパターンマッチングやディレクトリ走査を行うことが多いです。
また、処理途中でのエラー発生時にログを残し、後から原因を追跡しやすくする設計が求められます。
リアルタイム処理は、カメラなどからの映像を逐次処理し、即座に結果を返す方式です。
処理遅延を最小限に抑えることが重要で、フレームレートの維持や低レイテンシが求められます。
工場の検査ラインや監視カメラの映像解析などが典型例です。
リアルタイム処理では、マルチスレッドや非同期処理を活用して、画像の取得、処理、表示を並列化することが多いです。
また、処理負荷が高い場合はGPUアクセラレーションを利用することも検討します。
以下は、リアルタイム処理の簡単な例です。
カメラ映像を取得し、グレースケール変換して表示します。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::VideoCapture cap(0); // カメラデバイス0を開く
if (!cap.isOpened()) {
std::cerr << "カメラを開けませんでした。" << std::endl;
return -1;
}
cv::Mat frame, grayFrame;
while (true) {
cap >> frame;
if (frame.empty()) break;
cv::cvtColor(frame, grayFrame, cv::COLOR_BGR2GRAY);
cv::imshow("Gray Video", grayFrame);
if (cv::waitKey(30) >= 0) break; // 30ms待機、キー入力で終了
}
cap.release();
cv::destroyAllWindows();
return 0;
}(カメラ映像がグレースケールでリアルタイム表示される)このように、バッチ処理とリアルタイム処理は用途に応じて使い分け、要件に合わせて設計してください。
非機能要件
パフォーマンス
パフォーマンスは自動化ツールの使い勝手や実用性に直結します。
処理速度やリソース消費を最適化することが重要です。
OpenCVは内部でSIMD命令やマルチスレッドを活用して高速化されていますが、さらに以下のポイントを意識すると良いでしょう。
- 処理の並列化
複数の画像を同時に処理したり、フレームの取得と解析を別スレッドで行うことでスループットを向上させます。
- 不要なコピーの削減
cv::Matは参照カウント方式ですが、明示的なコピーを避けることでメモリ使用量と処理時間を削減できます。
- GPU活用
OpenCVのCUDAモジュールを利用して、対応する処理をGPUで実行すると大幅な高速化が可能です。
- アルゴリズムの選定
処理内容によっては、軽量なアルゴリズムを選ぶことでリアルタイム性を確保できます。
例えば、Haar Cascadeは高速ですが精度はDNNベースの物体検出より劣る場合があります。
パフォーマンスの評価は、実際の処理時間やCPU/GPU使用率を計測し、ボトルネックを特定して改善を繰り返すことが大切です。
拡張性
拡張性は、将来的に機能追加や仕様変更があった際に、容易に対応できる設計を指します。
自動化ツールは用途の変化や新しい技術の導入に伴い、拡張が必要になることが多いです。
拡張性を高めるためのポイントは以下の通りです。
- モジュール化
画像の読み込み、前処理、解析、出力など機能ごとにクラスや関数を分割し、依存関係を最小限にします。
- インターフェース設計
抽象クラスやインターフェースを用いて、処理アルゴリズムの差し替えを容易にします。
例えば、物体検出のアルゴリズムを複数用意し、実行時に切り替えられるようにします。
- 設定ファイルの活用
処理パラメータや入力・出力形式をコードにハードコーディングせず、外部設定ファイルで管理すると柔軟性が向上します。
- プラグイン構造
将来的に新しい処理モジュールを追加しやすいように、プラグイン形式で拡張できる設計も検討します。
保守性
保守性は、開発後のバグ修正や機能改善をスムーズに行うための設計指針です。
保守性が高いコードは、チームでの開発や長期運用において大きなメリットがあります。
保守性を高めるためのポイントは以下の通りです。
- コードの可読性
変数名や関数名は意味が明確なものを使い、コメントを適切に入れて処理の意図を伝えます。
- 一貫したコーディング規約
チームで統一したスタイルを採用し、コードレビューを通じて品質を保ちます。
- テストコードの充実
ユニットテストや結合テストを用意し、変更による影響を早期に検出します。
- ログ出力の整備
実行時の状態やエラーを詳細にログに残し、問題発生時の原因調査を容易にします。
- ドキュメント整備
設計書や使用方法のドキュメントを整備し、新しいメンバーが理解しやすい環境を作ります。
これらの要件を踏まえて設計・実装を進めることで、安定して使いやすい自動化ツールを開発できます。
データフロー設計
全体パイプラインの概要図
自動化ツールのデータフローは、画像や動画の入力から処理、結果の出力まで一連の流れとして設計します。
全体のパイプラインを視覚的に把握することで、各処理の役割やデータの流れを明確にできます。
以下は典型的な画像処理自動化ツールのパイプライン概要図の例です。
[入力ステージ] → [前処理ステージ] → [解析ステージ] → [出力ステージ]- 入力ステージ
画像や動画の読み込み、カメラからの映像取得を担当します。
- 前処理ステージ
ノイズ除去やリサイズ、色空間変換など、解析に適した状態に画像を整えます。
- 解析ステージ
物体検出や特徴抽出、形状解析など、目的の画像処理アルゴリズムを実行します。
- 出力ステージ
処理結果の保存、レポート生成、画面表示などを行います。
このパイプラインはモジュール化されており、各ステージは独立して開発・テストが可能です。
処理の順序や内容を柔軟に変更できる設計が望まれます。
各ステージの責務分離
入力ステージ
入力ステージは、外部からのデータ取得を担います。
具体的には、以下の役割があります。
- ファイル読み込み
画像ファイル(JPEG、PNGなど)や動画ファイル(MP4、AVIなど)を読み込みます。
OpenCVのcv::imreadやcv::VideoCaptureを利用します。
- カメラ映像取得
リアルタイム処理の場合は、カメラデバイスから映像を取得します。
複数カメラ対応やストリームの切り替えも考慮します。
- 入力データの検証
読み込んだデータが正しい形式か、破損していないかをチェックします。
不正なデータはエラー処理やスキップの対象とします。
- バッファリング
処理速度の差を吸収するために、入力データを一時的にバッファに保持することがあります。
特にリアルタイム処理ではフレームドロップを防ぐために重要です。
以下はファイルから画像を読み込む例です。
#include <opencv2/opencv.hpp>
#include <iostream>
cv::Mat loadImage(const std::string& path) {
cv::Mat img = cv::imread(path);
if (img.empty()) {
std::cerr << "画像の読み込みに失敗しました: " << path << std::endl;
}
return img;
}
int main() {
cv::Mat image = loadImage("sample.jpg");
if (image.empty()) return -1;
// 以降の処理へ渡す
return 0;
}前処理ステージ
前処理ステージは、解析の精度や安定性を高めるために画像を整える役割を持ちます。
主な処理内容は以下の通りです。
- 色空間変換
RGBからグレースケールやHSVなど、解析に適した色空間に変換します。
例:cv::cvtColor(input, output, cv::COLOR_BGR2GRAY);
- リサイズ・トリミング
処理負荷軽減や解析対象の領域抽出のために画像サイズを変更したり、必要な部分だけ切り出します。
例:cv::resize(input, output, cv::Size(width, height));
- ノイズ除去
ガウシアンブラーやメディアンフィルタでノイズを低減し、解析の誤差を減らします。
例:cv::GaussianBlur(input, output, cv::Size(5,5), 0);
- しきい値処理
二値化や適応的しきい値処理で対象物の輪郭を明確にします。
例:cv::threshold(input, output, 128, 255, cv::THRESH_BINARY);
前処理は解析の前段階として非常に重要で、適切な処理を選択しパラメータ調整を行うことで、後続の解析精度が大きく向上します。
解析ステージ
解析ステージは、ツールのコア機能であり、画像から目的の情報を抽出・判定します。
代表的な処理例は以下の通りです。
- 物体検出
Haar CascadeやHOG+SVM、DNNベースのYOLOなどを用いて対象物を検出します。
例:cv::CascadeClassifierやcv::dnn::Netを利用。
- 特徴抽出
エッジ検出(Canny)、コーナー検出(Harris)、ORBやSIFTなどの特徴点抽出を行います。
- 輪郭抽出と形状解析
cv::findContoursで輪郭を抽出し、面積や周囲長、形状の近似を計算します。
- テンプレートマッチング
既知のパターンと画像を比較し、類似度を計測します。
解析ステージは複雑なアルゴリズムを含むことが多いため、処理の効率化や結果の信頼性確保が重要です。
以下は輪郭抽出の簡単な例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat src = cv::imread("shapes.png", cv::IMREAD_GRAYSCALE);
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat binary;
cv::threshold(src, binary, 100, 255, cv::THRESH_BINARY);
std::vector<std::vector<cv::Point>> contours;
cv::findContours(binary, contours, cv::RETR_EXTERNAL, cv::CHAIN_APPROX_SIMPLE);
cv::Mat output = cv::Mat::zeros(src.size(), CV_8UC3);
for (size_t i = 0; i < contours.size(); ++i) {
cv::drawContours(output, contours, static_cast<int>(i), cv::Scalar(0, 255, 0), 2);
}
cv::imshow("Contours", output);
cv::waitKey(0);
return 0;
}(輪郭が緑色で描画されたウィンドウが表示される)

出力ステージ
出力ステージは、解析結果をユーザーや他システムに提供する役割を担います。
主な処理は以下の通りです。
- 画像・動画の保存
処理結果を画像ファイルや動画ファイルとして保存します。
OpenCVのcv::imwriteやcv::VideoWriterを利用します。
- 解析結果のレポート出力
検出結果や計測値をCSVやJSON形式でファイルに書き出し、他のツールでの利用を可能にします。
- 画面表示
処理結果をウィンドウに表示し、ユーザーがリアルタイムに確認できるようにします。
cv::imshowを使い、オーバーレイ描画で検出結果を重ねることも多いです。
- ログ出力
処理の進捗やエラー情報をログファイルに記録し、トラブルシューティングに役立てます。
以下は解析結果を画像にオーバーレイ描画して保存する例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat image = cv::imread("input.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// 簡単な矩形を描画
cv::rectangle(image, cv::Point(50, 50), cv::Point(200, 200), cv::Scalar(0, 0, 255), 3);
// 画像を保存
if (!cv::imwrite("output_with_rect.jpg", image)) {
std::cerr << "画像の保存に失敗しました。" << std::endl;
return -1;
}
// 画面表示
cv::imshow("Result", image);
cv::waitKey(0);
return 0;
}(赤い矩形が描画された画像が表示され、output_with_rect.jpgとして保存される)
このように、出力ステージはユーザーへのフィードバックや他システムとの連携を担う重要な役割を持ちます。
OpenCV主要API選定
画像入出力API
OpenCVで画像や動画の読み込み・保存を行う際に使う基本的なAPIはcv::imread、cv::imwrite、cv::VideoCapture、cv::VideoWriterです。
これらは自動化ツールの基盤となるため、用途に応じて適切に選択します。
- cv::imread
画像ファイルを読み込む関数です。
JPEG、PNG、BMPなど多くのフォーマットに対応しています。
読み込み時にカラーやグレースケールの指定が可能です。
cv::Mat image = cv::imread("input.jpg", cv::IMREAD_COLOR);
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
}- cv::imwrite
画像をファイルに保存します。
保存形式は拡張子で自動判別されます。
cv::imwrite("output.png", image);- cv::VideoCapture
動画ファイルやカメラデバイスから映像を取得します。
リアルタイム処理や動画解析に必須です。
cv::VideoCapture cap("video.mp4"); // ファイルから
// または
cv::VideoCapture cap(0); // カメラデバイス0から- cv::VideoWriter
画像フレームを動画ファイルとして保存します。
コーデックやフレームレートの指定が必要です。
cv::VideoWriter writer("output.avi", cv::VideoWriter::fourcc('M','J','P','G'), 30, cv::Size(width, height));
writer.write(frame);これらのAPIを組み合わせることで、画像・動画の入出力を柔軟に扱えます。
画像前処理API
前処理は解析の精度向上やノイズ低減に欠かせません。
OpenCVには多彩な前処理用APIが用意されています。
- 色空間変換:
cv::cvtColor
RGBからグレースケールやHSVなどに変換します。
解析アルゴリズムによって適切な色空間を選択します。
cv::cvtColor(src, dst, cv::COLOR_BGR2GRAY);- リサイズ:
cv::resize
画像サイズを変更し、処理負荷を調整したり解析対象を絞ります。
cv::resize(src, dst, cv::Size(newWidth, newHeight));- 平滑化・ノイズ除去
cv::GaussianBlur:ガウシアンフィルタでノイズをぼかすcv::medianBlur:メディアンフィルタで塩胡椒ノイズを除去
cv::GaussianBlur(src, dst, cv::Size(5,5), 0);
cv::medianBlur(src, dst, 3);- しきい値処理:
cv::threshold、cv::adaptiveThreshold
二値化や適応的なしきい値処理で対象物の輪郭を強調します。
cv::threshold(src, dst, 128, 255, cv::THRESH_BINARY);
cv::adaptiveThreshold(src, dst, 255, cv::ADAPTIVE_THRESH_MEAN_C, cv::THRESH_BINARY, 11, 2);- エッジ検出:
cv::Canny
画像の輪郭を抽出する際に使います。
cv::Canny(src, edges, 100, 200);これらのAPIを組み合わせて、解析に最適な画像を準備します。
特徴抽出・解析API
画像から意味のある情報を抽出するためのAPI群です。
自動化ツールのコア処理にあたります。
- 物体検出
cv::CascadeClassifier:Haar特徴を用いた高速な物体検出。顔検出などに利用cv::dnn::Net:DNN(深層学習)モデルを読み込み、YOLOやSSDなどの高精度検出を実行
cv::CascadeClassifier face_cascade;
face_cascade.load("haarcascade_frontalface_default.xml");
std::vector<cv::Rect> faces;
face_cascade.detectMultiScale(grayImage, faces);- 特徴点検出・記述
ORB、SIFT、SURFなどの特徴点検出器と記述子を使い、画像の特徴を抽出します。
cv::Ptr<cv::ORB> orb = cv::ORB::create();
std::vector<cv::KeyPoint> keypoints;
cv::Mat descriptors;
orb->detectAndCompute(image, cv::noArray(), keypoints, descriptors);- 輪郭抽出
cv::findContoursで輪郭を検出し、形状解析に利用します。
std::vector<std::vector<cv::Point>> contours;
cv::findContours(binaryImage, contours, cv::RETR_EXTERNAL, cv::CHAIN_APPROX_SIMPLE);- テンプレートマッチング
cv::matchTemplateで既知パターンとの類似度を計算します。
cv::matchTemplate(image, templateImage, result, cv::TM_CCOEFF_NORMED);これらのAPIを活用して、対象物の検出や特徴抽出を行い、自動化の判断材料を得ます。
描画・可視化API
解析結果をユーザーにわかりやすく伝えるために、画像上に描画や表示を行います。
- 図形描画
cv::rectangle:矩形を描画cv::circle:円を描画cv::line:線を描画cv::putText:テキストを描画
cv::rectangle(image, cv::Point(50, 50), cv::Point(200, 200), cv::Scalar(0, 255, 0), 2);
cv::putText(image, "Detected", cv::Point(60, 45), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 255, 0), 2);- 画像表示
cv::imshowでウィンドウに画像を表示し、リアルタイムに結果を確認できます。
cv::imshow("Result", image);
cv::waitKey(0);- 動画表示
動画フレームを連続表示し、リアルタイム処理の結果をモニタリングします。
- 色空間の指定
描画色はBGR形式で指定し、色の見やすさを考慮します。
描画APIは解析結果のフィードバックやデバッグに欠かせません。
適切に活用してユーザー体験を向上させましょう。
クラス設計と責務分割
コアクラスの一覧
自動化ツールの設計において、クラスごとに明確な責務を割り当てることは保守性や拡張性を高めるうえで重要です。
ここでは代表的なコアクラスとその役割を示します。
PipelineController
PipelineControllerは処理全体の流れを管理するクラスです。
各ステージのクラスを統括し、データの受け渡しや処理の開始・終了を制御します。
主な責務は以下の通りです。
- 入力から出力までのパイプラインの制御
- 各ステージの初期化と終了処理
- エラーハンドリングの統括
- 処理の進捗管理やログ出力
サンプルコードの一部イメージ:
class PipelineController {
public:
PipelineController();
void run();
private:
FrameReader frameReader;
Preprocessor preprocessor;
Analyzer analyzer;
ResultWriter resultWriter;
};run()メソッド内で、frameReaderからフレームを取得し、preprocessorで前処理、analyzerで解析、resultWriterで結果出力を順に呼び出します。
FrameReader
FrameReaderは画像や動画、カメラ映像などの入力データを取得する役割を担います。
ファイル読み込みやカメラキャプチャの抽象化を行い、上位クラスに統一的なインターフェースを提供します。
主な機能:
- 画像ファイルや動画ファイルの読み込み
- カメラデバイスからのリアルタイム映像取得
- 入力データの検証とエラーチェック
class FrameReader {
public:
bool open(const std::string& source);
bool read(cv::Mat& frame);
void close();
private:
cv::VideoCapture cap;
};open()でファイル名やカメラIDを指定し、read()でフレームを取得します。
Preprocessor
Preprocessorは解析に適した画像に変換する前処理を担当します。
色空間変換、リサイズ、ノイズ除去、しきい値処理などを実装します。
主な機能:
- 色空間変換(例:BGR→グレースケール)
- 画像サイズの調整
- フィルタリングによるノイズ除去
- 二値化やしきい値処理
class Preprocessor {
public:
void process(const cv::Mat& input, cv::Mat& output);
private:
// パラメータや設定を保持
};process()メソッドで入力画像を受け取り、前処理後の画像を返します。
Analyzer
Analyzerは画像解析のコア処理を行うクラスです。
物体検出や特徴抽出、輪郭解析などのアルゴリズムを実装します。
主な機能:
- 物体検出(Haar CascadeやDNNなど)
- 特徴点検出と記述子生成
- 輪郭抽出と形状解析
- 解析結果の判定や分類
class Analyzer {
public:
void analyze(const cv::Mat& input);
const std::vector<cv::Rect>& getDetections() const;
private:
std::vector<cv::Rect> detections;
cv::CascadeClassifier cascade;
};analyze()で画像を解析し、検出結果を内部に保持。
getDetections()で結果を取得します。
ResultWriter
ResultWriterは解析結果の出力を担当します。
画像への描画、ファイル保存、レポート生成などを行います。
主な機能:
- 画像や動画へのオーバーレイ描画
- 画像・動画ファイルの保存
- CSVやJSON形式での解析結果出力
- ログ記録
class ResultWriter {
public:
void writeImage(const cv::Mat& image, const std::string& filename);
void writeReport(const std::vector<cv::Rect>& detections, const std::string& filename);
};描画やファイル出力の処理をまとめて管理します。
インターフェースとポリモーフィズム活用
拡張性を高めるために、共通のインターフェースを定義し、ポリモーフィズムを活用する設計が効果的です。
これにより、異なる実装を切り替えたり、新しいアルゴリズムを追加しやすくなります。
例えば、解析処理を抽象化したIAnalyzerインターフェースを用意します。
class IAnalyzer {
public:
virtual ~IAnalyzer() = default;
virtual void analyze(const cv::Mat& input) = 0;
virtual const std::vector<cv::Rect>& getDetections() const = 0;
};このインターフェースを継承して、Haar Cascade解析やDNN解析のクラスを実装します。
class HaarAnalyzer : public IAnalyzer {
// Haar Cascadeによる解析実装
};
class DnnAnalyzer : public IAnalyzer {
// DNNによる解析実装
};PipelineControllerはIAnalyzerのポインタを保持し、実行時に適切な解析クラスを選択できます。
同様に、FrameReaderやPreprocessor、ResultWriterもインターフェース化し、異なる実装を差し替え可能にすると、メンテナンスや機能追加が容易になります。
この設計により、将来的に新しい解析手法や入出力形式を追加しても、既存コードへの影響を最小限に抑えられます。
ファイル構成と名前空間
ディレクトリレイアウト案
C++とOpenCVを用いた自動化ツールの開発では、ソースコードの整理が重要です。
適切なディレクトリ構成を設計することで、開発効率や保守性が向上します。
以下は一般的かつ実用的なディレクトリレイアウトの例です。
project_root/
├── include/ # ヘッダーファイル
│ ├── pipeline/ # パイプライン関連クラスのヘッダー
│ │ ├── PipelineController.h
│ │ ├── FrameReader.h
│ │ ├── Preprocessor.h
│ │ ├── Analyzer.h
│ │ └── ResultWriter.h
│ └── utils/ # ユーティリティ関数や共通定義
│ └── Logger.h
├── src/ # ソースファイル
│ ├── pipeline/ # パイプライン関連クラスの実装
│ │ ├── PipelineController.cpp
│ │ ├── FrameReader.cpp
│ │ ├── Preprocessor.cpp
│ │ ├── Analyzer.cpp
│ │ └── ResultWriter.cpp
│ └── utils/ # ユーティリティ実装
│ └── Logger.cpp
├── tests/ # テストコード
│ ├── pipeline/
│ └── utils/
├── data/ # 入力画像や動画、設定ファイル
├── build/ # ビルド出力ディレクトリ(CMake等で生成)
├── CMakeLists.txt # ビルド設定ファイル
└── README.md # プロジェクト説明この構成のポイントは以下の通りです。
include/とsrc/の分離
ヘッダーファイルと実装ファイルを分けることで、依存関係の管理がしやすくなります。
- 機能ごとのサブディレクトリ
パイプライン関連のクラスはpipeline/にまとめ、ユーティリティはutils/に分けることで役割が明確になります。
- テストコードの独立
tests/ディレクトリにユニットテストや結合テストを配置し、本体コードと分離します。
- データ管理
入力画像や設定ファイルはdata/にまとめ、ソースコードと分離して管理します。
- ビルド出力の分離
build/ディレクトリをビルド成果物専用にし、ソースコードのクリーンな状態を保ちます。
このように整理することで、チーム開発や将来的な拡張に対応しやすくなります。
モジュール依存関係図
モジュール間の依存関係を明確にすることは、設計の健全性を保つうえで重要です。
以下は先述のコアクラスを中心とした依存関係の例です。
PipelineController
├── FrameReader
├── Preprocessor
├── Analyzer
└── ResultWriterPipelineControllerは全体の制御を担い、他のモジュールに依存しますFrameReaderは外部からのデータ取得に特化し、他のモジュールには依存しませんPreprocessorはFrameReaderから渡された画像を受け取り、Analyzerに渡しますAnalyzerは前処理済み画像を解析し、結果をResultWriterに渡しますResultWriterは解析結果をファイル保存や画面表示に反映します
この依存関係は一方向であり、循環依存を避ける設計です。
これにより、モジュールの独立性が保たれ、テストや修正が容易になります。
また、ユーティリティモジュール(例:Logger)は全モジュールから参照されることが多いですが、依存先としては独立しています。
名前空間の設計も重要です。
例えば、pipeline名前空間を用いてパイプライン関連クラスをまとめると、以下のようになります。
namespace pipeline {
class PipelineController { /* ... */ };
class FrameReader { /* ... */ };
// 他クラスも同様に
}ユーティリティはutils名前空間に分けると、コードの可読性と衝突回避に役立ちます。
このようにディレクトリ構成と名前空間を整えることで、プロジェクトの規模が大きくなっても管理しやすくなります。
画像入力モジュール
静止画読み込み
静止画の読み込みは画像処理自動化ツールの基本機能の一つです。
OpenCVではcv::imread関数を使って簡単に画像ファイルを読み込めます。
対応フォーマットはJPEG、PNG、BMP、TIFFなど多岐にわたり、用途に応じてカラー画像やグレースケール画像として読み込むことが可能です。
以下は静止画をカラーで読み込み、グレースケールに変換して表示するサンプルコードです。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
// 画像ファイルをカラーで読み込む
cv::Mat colorImage = cv::imread("input.jpg", cv::IMREAD_COLOR);
if (colorImage.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// グレースケールに変換
cv::Mat grayImage;
cv::cvtColor(colorImage, grayImage, cv::COLOR_BGR2GRAY);
// 画像を表示
cv::imshow("Color Image", colorImage);
cv::imshow("Gray Image", grayImage);
cv::waitKey(0);
return 0;
}(カラー画像とグレースケール画像の2つのウィンドウが表示される)ポイントとしては、cv::imreadはファイルパスが正しくない場合や対応していないフォーマットの場合に空のcv::Matを返すため、読み込み後にempty()でチェックすることが重要です。
また、複数の画像を一括で処理する場合は、ファイル名のリストやディレクトリ内のファイルを走査して順次読み込む実装が一般的です。
動画ストリーム取り込み
動画やリアルタイム映像の取り込みはcv::VideoCaptureクラスを用いて行います。
動画ファイルの読み込みだけでなく、USBカメラやネットワークカメラからのライブストリームも扱えます。
以下は動画ファイルを読み込み、フレームごとにグレースケール変換して表示する例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::VideoCapture cap("input.mp4");
if (!cap.isOpened()) {
std::cerr << "動画ファイルを開けませんでした。" << std::endl;
return -1;
}
cv::Mat frame, grayFrame;
while (true) {
cap >> frame;
if (frame.empty()) break;
cv::cvtColor(frame, grayFrame, cv::COLOR_BGR2GRAY);
cv::imshow("Gray Video", grayFrame);
if (cv::waitKey(30) >= 0) break; // 30ms待機、キー入力で終了
}
cap.release();
cv::destroyAllWindows();
return 0;
}(動画の各フレームがグレースケールでリアルタイム表示される)USBカメラなどのリアルタイム映像を扱う場合は、cv::VideoCapture cap(0);のようにデバイスIDを指定します。
複数カメラがある場合はIDを変えてアクセス可能です。
動画ストリームの取り込みでは、フレームレートや解像度の設定、フレームドロップの監視も重要です。
cap.set()メソッドで解像度やFPSを指定できます。
cap.set(cv::CAP_PROP_FRAME_WIDTH, 640);
cap.set(cv::CAP_PROP_FRAME_HEIGHT, 480);
cap.set(cv::CAP_PROP_FPS, 30);並列デコードの検討
大量の画像や高解像度動画を高速に処理する場合、単一スレッドでのデコード処理はボトルネックになりやすいです。
そこで、並列デコードを検討することで処理スループットを向上させられます。
並列デコードの基本的な考え方は、複数のスレッドを使って同時に複数の画像や動画フレームをデコードし、後続の処理に渡すことです。
これによりCPUのマルチコアを有効活用できます。
OpenCV自体は内部である程度のマルチスレッド最適化を行っていますが、アプリケーションレベルでの並列化も効果的です。
例えば、以下のような構成が考えられます。
- スレッドプールを用いた画像読み込み
ファイルリストを複数のスレッドに分配し、各スレッドでcv::imreadを実行。
読み込み済み画像はスレッドセーフなキューに格納し、解析スレッドが順次取得。
- 動画フレームのバッファリングとデコードスレッド
動画ストリームからフレームを取得するスレッドと、デコード・前処理を行うスレッドを分けます。
フレームバッファを共有し、処理の遅延を抑制。
以下はC++11のスレッドとキューを使った簡単な並列画像読み込みのイメージコードです。
#include <opencv2/opencv.hpp>
#include <iostream>
#include <thread>
#include <queue>
#include <mutex>
#include <condition_variable>
#include <vector>
std::queue<cv::Mat> imageQueue;
std::mutex queueMutex;
std::condition_variable cvQueue;
bool finished = false;
void imageLoader(const std::vector<std::string>& files) {
for (const auto& file : files) {
cv::Mat img = cv::imread(file);
if (!img.empty()) {
std::unique_lock<std::mutex> lock(queueMutex);
imageQueue.push(img);
cvQueue.notify_one();
}
}
std::unique_lock<std::mutex> lock(queueMutex);
finished = true;
cvQueue.notify_all();
}
void imageProcessor() {
while (true) {
std::unique_lock<std::mutex> lock(queueMutex);
cvQueue.wait(lock, [] { return !imageQueue.empty() || finished; });
if (imageQueue.empty() && finished) break;
cv::Mat img = imageQueue.front();
imageQueue.pop();
lock.unlock();
// ここで画像処理を行う(例:グレースケール変換)
cv::Mat gray;
cv::cvtColor(img, gray, cv::COLOR_BGR2GRAY);
// 処理結果の利用や保存など
std::cout << "Processed an image of size: " << gray.cols << "x" << gray.rows << std::endl;
}
}
int main() {
std::vector<std::string> files = {"img1.jpg", "img2.jpg", "img3.jpg"};
std::thread loader(imageLoader, files);
std::thread processor(imageProcessor);
loader.join();
processor.join();
return 0;
}Processed an image of size: 640x480
Processed an image of size: 800x600
Processed an image of size: 1024x768この例では、画像読み込みと処理を別スレッドで並行して行い、処理待ち時間を減らしています。
実際のツールではスレッド数の調整や例外処理、キューのサイズ制御などを追加して安定性を高めます。
動画の並列デコードでは、OpenCVのVideoCaptureは内部でデコードを行うため、複数の動画ファイルを同時に処理する場合はファイルごとに別スレッドでVideoCaptureを開く方法が一般的です。
リアルタイム映像の並列処理は、フレーム取得と解析を別スレッドに分けることでレイテンシを抑えられます。
GPUを活用したデコード(例:NVIDIAのNVDEC)を組み合わせると、さらに高速化が可能ですが、OpenCVの標準APIだけでは対応が限定的なため、専用ライブラリとの連携が必要です。
このように、画像入力モジュールは静止画・動画の読み込みから並列化まで幅広い設計が求められます。
用途や処理負荷に応じて適切な実装を選択してください。
画像前処理モジュール
色空間変換
色空間変換は画像前処理の基本であり、解析や特徴抽出に適した色空間に変換するために用います。
OpenCVではcv::cvtColor関数を使い、多彩な色空間間の変換が可能です。
代表的な変換例は以下の通りです。
- BGR → グレースケール
多くの解析アルゴリズムはグレースケール画像を前提としているため、カラー画像を単一チャネルに変換します。
cv::cvtColor(src, dst, cv::COLOR_BGR2GRAY);- BGR → HSV
色相(Hue)、彩度(Saturation)、明度(Value)に分解し、色の特徴を抽出しやすくします。
色検出や物体追跡に有効です。
cv::cvtColor(src, dst, cv::COLOR_BGR2HSV);- BGR → LAB
人間の視覚に近い色空間で、色差計算や色補正に使われます。
cv::cvtColor(src, dst, cv::COLOR_BGR2Lab);色空間変換は解析目的に応じて適切に選択します。
例えば、肌色検出ならHSV空間のHチャネルを利用することが多いです。
リサイズとアスペクト保持
画像のリサイズは処理負荷の軽減や解析対象の統一に役立ちますが、アスペクト比(縦横比)を保持することが重要です。
アスペクト比を崩すと、物体の形状が歪み、解析結果に悪影響を及ぼします。
OpenCVのcv::resize関数でリサイズを行いますが、アスペクト比を保持するには以下のような手順が一般的です。
- 目標の幅または高さを決める。
- 元画像のアスペクト比を計算します。
- 目標サイズに合わせてもう一方の辺のサイズを計算します。
cv::resizeでリサイズ。
#include <opencv2/opencv.hpp>
#include <iostream>
cv::Mat resizeWithAspectRatio(const cv::Mat& src, int targetWidth, int targetHeight) {
int originalWidth = src.cols;
int originalHeight = src.rows;
double aspectRatio = static_cast<double>(originalWidth) / originalHeight;
int newWidth = targetWidth;
int newHeight = targetHeight;
if (targetWidth / static_cast<double>(targetHeight) > aspectRatio) {
newWidth = static_cast<int>(targetHeight * aspectRatio);
} else {
newHeight = static_cast<int>(targetWidth / aspectRatio);
}
cv::Mat dst;
cv::resize(src, dst, cv::Size(newWidth, newHeight));
return dst;
}
int main() {
cv::Mat image = cv::imread("input.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat resized = resizeWithAspectRatio(image, 640, 480);
cv::imshow("Resized Image", resized);
cv::waitKey(0);
return 0;
}(アスペクト比を保持したまま640x480以内にリサイズされた画像が表示される)この方法でリサイズすれば、画像の歪みを防ぎつつ処理負荷を抑えられます。
ノイズリダクション
ノイズリダクション(ノイズ除去)は画像の品質を向上させ、解析の誤検出を減らすために重要です。
OpenCVには複数のノイズ除去フィルタが用意されています。
代表的な手法は以下の通りです。
- ガウシアンブラー(GaussianBlur)
ガウス関数に基づく平滑化で、ノイズをぼかして除去します。
エッジも多少ぼやけるため、パラメータ調整が必要です。
cv::GaussianBlur(src, dst, cv::Size(5, 5), 1.5);- メディアンフィルタ(medianBlur)
各画素を周囲の中央値に置き換え、特に塩胡椒ノイズに強いです。
cv::medianBlur(src, dst, 3);- バイラテラルフィルタ(bilateralFilter)
エッジを保持しつつノイズを除去する高度なフィルタ。
計算コストは高めです。
cv::bilateralFilter(src, dst, 9, 75, 75);ノイズリダクションは解析対象やノイズの種類に応じて使い分けます。
例えば、文字認識前にはメディアンフィルタが有効なことが多いです。
しきい値処理
しきい値処理は画像を二値化し、対象物の輪郭や領域を明確にするために使います。
OpenCVのcv::thresholdやcv::adaptiveThresholdが代表的です。
- 固定しきい値(二値化)
指定した閾値を基準に画素を0か最大値に振り分けます。
cv::threshold(src, dst, 128, 255, cv::THRESH_BINARY);- 反転二値化
白黒を反転させたい場合に使います。
cv::threshold(src, dst, 128, 255, cv::THRESH_BINARY_INV);- 適応的しきい値
画像の局所的な明るさに応じてしきい値を変えるため、照明ムラがある画像に有効です。
cv::adaptiveThreshold(src, dst, 255, cv::ADAPTIVE_THRESH_MEAN_C, cv::THRESH_BINARY, 11, 2);- 大津の二値化(自動しきい値)
画像のヒストグラムを解析し、最適なしきい値を自動で決定します。
double thresh = cv::threshold(src, dst, 0, 255, cv::THRESH_BINARY | cv::THRESH_OTSU);以下は大津の二値化の例です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat gray = cv::imread("input.jpg", cv::IMREAD_GRAYSCALE);
if (gray.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat binary;
double thresh = cv::threshold(gray, binary, 0, 255, cv::THRESH_BINARY | cv::THRESH_OTSU);
std::cout << "自動決定されたしきい値: " << thresh << std::endl;
cv::imshow("Binary Image", binary);
cv::waitKey(0);
return 0;
}自動決定されたしきい値: 127.5
(しきい値処理された二値画像が表示される)しきい値処理は輪郭抽出や物体検出の前段階として必須の処理であり、適切な手法とパラメータ選定が解析精度に大きく影響します。
解析モジュール
物体検出アルゴリズム
物体検出は画像解析の中核であり、対象物の位置や大きさを特定する技術です。
OpenCVでは複数の代表的なアルゴリズムが利用可能で、用途や精度・速度のバランスに応じて選択します。
Haar Cascade
Haar CascadeはOpenCVで古くから使われている物体検出手法で、顔検出などに広く利用されています。
Haar特徴と呼ばれる矩形領域の輝度差を特徴量として、AdaBoostで学習した分類器を用います。
物体検出に用いるカスケード分類器の利用にはカスケードファイルが必要です。
OpenCVをインストールすると、多くの環境ではhaarcascade_frontalface_default.xmlファイルが自動的に含まれています。以下のようなパスに存在することが多いです。
/usr/share/opencv4/haarcascades/haarcascade_frontalface_default.xmlopencv\sources\data\haarcascades\haarcascade_frontalface_default.xmlカスケードファイルをコピーしてカレントディレクトリに配置するなどをして、使える状態にしておきましょう。
特徴:
- 高速でリアルタイム処理に適している
- 学習済みのカスケード分類器が多数公開されている
- 精度は深層学習に比べると劣るが軽量
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::CascadeClassifier faceCascade;
if (!faceCascade.load("haarcascade_frontalface_default.xml")) {
std::cerr << "カスケード分類器の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat image = cv::imread("face.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
std::vector<cv::Rect> faces;
cv::Mat gray;
cv::cvtColor(image, gray, cv::COLOR_BGR2GRAY);
cv::equalizeHist(gray, gray);
faceCascade.detectMultiScale(gray, faces, 1.1, 3, 0, cv::Size(30, 30));
for (const auto& face : faces) {
cv::rectangle(image, face, cv::Scalar(0, 255, 0), 2);
}
cv::imshow("Detected Faces", image);
cv::waitKey(0);
return 0;
}(検出された顔に緑色の矩形が描画された画像が表示される)
HOG + SVM
HOG(Histogram of Oriented Gradients)は画像の局所的な勾配方向の分布を特徴量として抽出し、SVM(Support Vector Machine)で分類を行う手法です。
主に歩行者検出に使われます。
特徴:
- Haar Cascadeよりも高精度で、特に人検出に強い
- 計算コストはやや高いがリアルタイム処理可能
- OpenCVに組み込みの
cv::HOGDescriptorで簡単に利用可能
使用例(歩行者検出):
#include <iostream>
#include <opencv2/opencv.hpp>
int main() {
cv::HOGDescriptor hog;
hog.setSVMDetector(cv::HOGDescriptor::getDefaultPeopleDetector());
cv::Mat image = cv::imread("pedestrian.png");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
std::vector<cv::Rect> detections;
std::vector<double> foundWeights;
// パラメータを指定して検出
hog.detectMultiScale(image, detections, foundWeights,
0.0, // hitThreshold
cv::Size(8, 8), // winStride
cv::Size(32, 32), // padding
1.05, // scale
2, // groupThreshold
false); // useMeanshiftGrouping
// 信頼度が高い検出だけ描画
for (size_t i = 0; i < detections.size(); i++) {
if (foundWeights[i] < 1.0) continue; // 信頼度閾値
cv::rectangle(image, detections[i], cv::Scalar(255, 0, 0), 2);
}
cv::imshow("Pedestrian Detection", image);
cv::waitKey(0);
return 0;
}
(検出された歩行者に青色の矩形が描画された画像が表示される)DNNベースのYOLOv5
YOLOv5は深層学習を用いた物体検出アルゴリズムで、高速かつ高精度な検出が可能です。
OpenCVのDNNモジュールを使ってONNX形式のYOLOv5モデルを読み込み、推論できます。
特徴:
- 多クラス検出に対応し、精度が非常に高い
- GPUを活用すればリアルタイム処理も可能
- モデルのカスタマイズや転移学習が容易
使用例(YOLOv5 ONNXモデルの推論):
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <iostream>
int main() {
// モデルとクラス名のパス
std::string modelPath = "yolov5s.onnx";
std::string classesFile = "coco.names";
// クラス名の読み込み
std::vector<std::string> classNames;
std::ifstream ifs(classesFile.c_str());
std::string line;
while (std::getline(ifs, line)) classNames.push_back(line);
// DNNネットワークの読み込み
cv::dnn::Net net = cv::dnn::readNetFromONNX(modelPath);
if (net.empty()) {
std::cerr << "モデルの読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat image = cv::imread("input.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// 入力前処理
cv::Mat blob = cv::dnn::blobFromImage(image, 1/255.0, cv::Size(640, 640), cv::Scalar(), true, false);
net.setInput(blob);
// 推論実行
std::vector<cv::Mat> outputs;
net.forward(outputs, net.getUnconnectedOutLayersNames());
// 出力解析(省略、NMSなどを実装する必要あり)
// ここでは簡略化のため、描画処理は割愛
std::cout << "YOLOv5推論完了" << std::endl;
return 0;
}YOLOv5の推論結果は複数のバウンディングボックスとクラス確率を含み、非最大抑制(NMS)で重複検出を除去する処理が必要です。
詳細な実装は公式リポジトリやチュートリアルを参照してください。
輪郭抽出と形状解析
輪郭抽出は画像中の物体の境界線を検出し、形状の特徴を解析する手法です。
OpenCVのcv::findContours関数で輪郭を取得し、面積や周囲長、形状の近似、多角形化などを行います。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat src = cv::imread("shapes.png", cv::IMREAD_GRAYSCALE);
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat binary;
cv::threshold(src, binary, 100, 255, cv::THRESH_BINARY);
std::vector<std::vector<cv::Point>> contours;
cv::findContours(binary, contours, cv::RETR_EXTERNAL, cv::CHAIN_APPROX_SIMPLE);
cv::Mat output = cv::Mat::zeros(src.size(), CV_8UC3);
for (size_t i = 0; i < contours.size(); ++i) {
double area = cv::contourArea(contours[i]);
std::vector<cv::Point> approx;
cv::approxPolyDP(contours[i], approx, 5, true);
cv::Scalar color(0, 255, 0);
cv::drawContours(output, contours, static_cast<int>(i), color, 2);
// 面積と頂点数を表示
cv::putText(output, "Area:" + std::to_string(static_cast<int>(area)), approx[0], cv::FONT_HERSHEY_SIMPLEX, 0.5, color, 1);
cv::putText(output, "Verts:" + std::to_string(approx.size()), approx[0] + cv::Point(0,15), cv::FONT_HERSHEY_SIMPLEX, 0.5, color, 1);
}
cv::imshow("Contours and Shape Analysis", output);
cv::waitKey(0);
return 0;
}(輪郭が緑色で描画され、各輪郭の面積と頂点数が表示されるウィンドウが開く)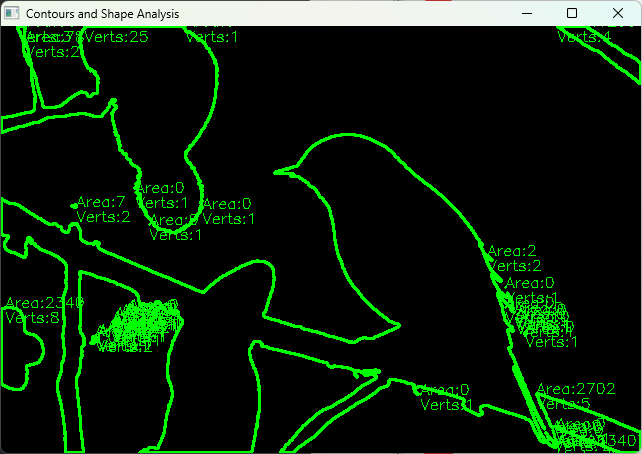
形状解析は物体の種類判別や欠陥検出に役立ちます。
例えば、多角形近似の頂点数で円形や四角形を判別できます。
テンプレートマッチング
テンプレートマッチングは、既知のパターン(テンプレート)を画像内で検索し、類似度の高い位置を検出する手法です。
OpenCVのcv::matchTemplate関数を使います。
特徴:
- シンプルで高速
- 回転やスケール変化に弱い
- 部分一致の検出に適している
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat image = cv::imread("scene.jpg", cv::IMREAD_COLOR);
cv::Mat templateImg = cv::imread("template.jpg", cv::IMREAD_COLOR);
if (image.empty() || templateImg.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::Mat result;
cv::matchTemplate(image, templateImg, result, cv::TM_CCOEFF_NORMED);
double minVal, maxVal;
cv::Point minLoc, maxLoc;
cv::minMaxLoc(result, &minVal, &maxVal, &minLoc, &maxLoc);
cv::rectangle(image, maxLoc, cv::Point(maxLoc.x + templateImg.cols, maxLoc.y + templateImg.rows), cv::Scalar(0, 0, 255), 2);
std::cout << "最高類似度スコア: " << maxVal << std::endl;
cv::imshow("Template Matching Result", image);
cv::waitKey(0);
return 0;
}最高類似度スコア: 0.85
(テンプレートに一致した領域が赤い矩形で囲まれた画像が表示される)テンプレートマッチングは単純なパターン検出に有効ですが、回転やスケールの変化に対応するには複雑な前処理や特徴量ベースの手法を組み合わせる必要があります。
これらの解析モジュールを組み合わせることで、多様な画像解析タスクに対応可能な自動化ツールを構築できます。
用途に応じてアルゴリズムを選択し、パラメータ調整や後処理を行うことが重要です。
結果出力モジュール
画像保存と動画生成
画像処理の結果をファイルとして保存することは、自動化ツールの重要な機能です。
OpenCVではcv::imwriteを使って画像を保存し、cv::VideoWriterを使って動画を生成できます。
画像保存
cv::imwriteは指定したパスに画像を保存します。
対応フォーマットは拡張子により自動判別され、JPEG、PNG、BMP、TIFFなどが利用可能です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
cv::Mat image = cv::imread("input.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
// 画像をPNG形式で保存
if (!cv::imwrite("output.png", image)) {
std::cerr << "画像の保存に失敗しました。" << std::endl;
return -1;
}
std::cout << "画像を保存しました。" << std::endl;
return 0;
}画像を保存しました。保存時にJPEGの圧縮率などパラメータを指定することも可能です。
std::vector<int> params = {cv::IMWRITE_JPEG_QUALITY, 90};
cv::imwrite("output.jpg", image, params);動画生成
cv::VideoWriterを使うと、複数の画像フレームを連結して動画ファイルを作成できます。
コーデックやフレームレート、解像度の指定が必要です。
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
int width = 640;
int height = 480;
int fps = 30;
cv::VideoWriter writer("output.avi", cv::VideoWriter::fourcc('M','J','P','G'), fps, cv::Size(width, height));
if (!writer.isOpened()) {
std::cerr << "動画ファイルの作成に失敗しました。" << std::endl;
return -1;
}
for (int i = 0; i < 100; ++i) {
cv::Mat frame(height, width, CV_8UC3, cv::Scalar(0, 0, 0));
cv::putText(frame, "Frame " + std::to_string(i), cv::Point(50, 240), cv::FONT_HERSHEY_SIMPLEX, 1.0, cv::Scalar(0, 255, 0), 2);
writer.write(frame);
}
writer.release();
std::cout << "動画を生成しました。" << std::endl;
return 0;
}動画を生成しました。動画生成時は、コーデックの互換性やファイルサイズに注意してください。
fourccコードは環境によって異なるため、適切なものを選びます。
CSV・JSONレポート出力
解析結果を数値データとして保存し、他システムや分析ツールで利用できるようにするために、CSVやJSON形式でレポートを出力します。
C++標準ライブラリや外部ライブラリを使って実装可能です。
CSV出力例
以下は検出した物体の位置情報をCSVファイルに書き出す例です。
#include <opencv2/opencv.hpp>
#include <iostream>
#include <fstream>
#include <vector>
struct Detection {
int x, y, width, height;
};
int main() {
std::vector<Detection> detections = {
{100, 150, 50, 60},
{200, 80, 40, 70}
};
std::ofstream ofs("detections.csv");
if (!ofs) {
std::cerr << "ファイルを開けませんでした。" << std::endl;
return -1;
}
ofs << "x,y,width,height\n";
for (const auto& d : detections) {
ofs << d.x << "," << d.y << "," << d.width << "," << d.height << "\n";
}
ofs.close();
std::cout << "CSVファイルを出力しました。" << std::endl;
return 0;
}CSVファイルを出力しました。JSON出力例
JSONは階層構造を持つデータを扱いやすく、C++ではnlohmann/jsonなどのライブラリがよく使われます。
#include <opencv2/opencv.hpp>
#include <iostream>
#include <fstream>
#include <vector>
#include <nlohmann/json.hpp>
struct Detection {
int x, y, width, height;
};
int main() {
std::vector<Detection> detections = {
{100, 150, 50, 60},
{200, 80, 40, 70}
};
nlohmann::json j;
for (const auto& d : detections) {
j["detections"].push_back({
{"x", d.x},
{"y", d.y},
{"width", d.width},
{"height", d.height}
});
}
std::ofstream ofs("detections.json");
if (!ofs) {
std::cerr << "ファイルを開けませんでした。" << std::endl;
return -1;
}
ofs << j.dump(4); // インデント4スペースで整形出力
ofs.close();
std::cout << "JSONファイルを出力しました。" << std::endl;
return 0;
}JSONファイルを出力しました。JSONファイル例:
{
"detections": [
{
"x": 100,
"y": 150,
"width": 50,
"height": 60
},
{
"x": 200,
"y": 80,
"width": 40,
"height": 70
}
]
}オーバーレイ描画
解析結果を画像上に重ねて表示することで、ユーザーに視覚的にわかりやすくフィードバックできます。
OpenCVの描画関数を使い、矩形やテキスト、線などを描画します。
代表的な描画関数:
cv::rectangle:矩形描画cv::circle:円描画cv::line:線描画cv::putText:テキスト描画
以下は検出結果の矩形とラベルを画像にオーバーレイ描画する例です。
#include <opencv2/opencv.hpp>
#include <iostream>
#include <vector>
struct Detection {
cv::Rect bbox;
std::string label;
};
int main() {
cv::Mat image = cv::imread("input.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
std::vector<Detection> detections = {
{cv::Rect(100, 150, 50, 60), "Object A"},
{cv::Rect(200, 80, 40, 70), "Object B"}
};
for (const auto& det : detections) {
cv::rectangle(image, det.bbox, cv::Scalar(0, 255, 0), 2);
cv::putText(image, det.label, det.bbox.tl() - cv::Point(0, 5),
cv::FONT_HERSHEY_SIMPLEX, 0.6, cv::Scalar(0, 255, 0), 2);
}
cv::imshow("Overlay Result", image);
cv::waitKey(0);
return 0;
}(検出領域に緑色の矩形とラベルが描画された画像が表示される)オーバーレイ描画はリアルタイム処理の結果表示や、解析結果の検証に欠かせません。
色やフォントサイズ、線の太さは見やすさに配慮して調整してください。
エラーハンドリングとログ
例外設計方針
C++で自動化ツールを開発する際、堅牢なエラーハンドリングは品質を保つために不可欠です。
例外設計方針を明確にすることで、予期しない障害発生時の挙動を統一し、保守性を高められます。
- 例外の使用範囲を限定する
例外は重大なエラーや回復不能な状態を通知するために使い、通常の制御フローには使わないようにします。
例えば、ファイル読み込み失敗やメモリ不足などが該当します。
- 例外クラスの階層化
独自の例外クラスを作成し、標準例外std::exceptionを継承して階層構造を設計します。
これにより、特定の例外を捕捉したり、共通の基底クラスでまとめて処理できます。
class ImageProcessingException : public std::runtime_error {
public:
explicit ImageProcessingException(const std::string& message)
: std::runtime_error(message) {}
};
class FileNotFoundException : public ImageProcessingException {
public:
explicit FileNotFoundException(const std::string& message)
: ImageProcessingException(message) {}
};- 例外の伝播とキャッチ
低レベルの関数では例外をスローし、上位レイヤーで適切にキャッチして処理やログ出力を行います。
例外をキャッチしたら、可能な限り復旧処理やユーザーへの通知を行います。
- 例外安全性の確保
リソースリークを防ぐためにRAII(Resource Acquisition Is Initialization)を活用し、例外発生時もリソースが確実に解放される設計にします。
- 例外を使わないエラーハンドリングとの併用
パフォーマンスが重要な箇所では戻り値によるエラーコードを使い、例外は重大エラーに限定することも検討します。
ログレベルと出力先
ログは実行時の状態やエラー情報を記録し、問題解析や運用監視に役立ちます。
ログレベルを設けて重要度に応じた出力制御を行い、適切な出力先を選択します。
- ログレベルの例
| レベル | 説明 |
|---|---|
| DEBUG | 詳細なデバッグ情報。開発時に有効化。 |
| INFO | 通常の動作状況。運用時の基本ログ。 |
| WARNING | 軽微な問題や注意すべき状態。 |
| ERROR | 処理失敗や重大な問題。 |
| CRITICAL | システム停止や復旧不能な致命的エラー。 |
- ログ出力先
- コンソール
開発中やデバッグ時にリアルタイムで確認可能です。
- ファイル
運用時の履歴保存に適し、ローテーションやサイズ制限を設けることが多い。
- リモートサーバ
大規模システムではSyslogやログ収集サーバに送信し、一元管理する場合もあります。
- ログライブラリの活用
spdlogやglogなどの高機能ログライブラリを使うと、スレッドセーフや非同期出力、フォーマット指定が容易です。
- ログのフォーマット例
[2024-06-01 12:34:56][ERROR][PipelineController] ファイル読み込みに失敗しました: input.jpgデバッグビルトインツール
開発や運用時のトラブルシューティングを効率化するために、デバッグ用のビルトインツールを組み込むことが有効です。
- 状態表示機能
現在の処理ステージやパラメータ値、処理時間などをリアルタイムに表示する機能。
GUIやコンソール出力で実装可能です。
- 内部データのダンプ
画像処理途中の中間データ(画像や特徴量)をファイルに保存し、解析や比較に利用。
- 統計情報の収集
処理時間、エラー発生回数、検出件数などの統計を収集し、パフォーマンスチューニングや品質管理に役立てる。
- トレースログ
関数の呼び出し履歴や重要な変数の変化を詳細に記録し、問題発生箇所の特定を容易にします。
- ホットキーやコマンドによる制御
実行中にログレベルの変更や処理の一時停止・再開を可能にし、柔軟なデバッグを支援。
- 例:簡単なログマクロ
#define LOG_DEBUG(msg) if (logLevel <= DEBUG) std::cout << "[DEBUG] " << msg << std::endl;
#define LOG_ERROR(msg) std::cerr << "[ERROR] " << msg << std::endl;これらのツールを組み込むことで、開発効率が向上し、運用中の問題対応も迅速になります。
ログと例外処理と連携させて、安定したシステム運用を目指しましょう。
設定ファイルとコマンドライン引数
YAML/JSON設定の取り込み
自動化ツールの柔軟性を高めるために、設定ファイルからパラメータを読み込む仕組みは欠かせません。
YAMLやJSONは人間に読みやすく、構造化された設定を記述できるため広く使われています。
C++では外部ライブラリを利用してこれらのフォーマットをパースし、設定値をプログラムに反映します。
YAML設定の取り込み
YAMLは階層的でコメントも書けるため、複雑な設定に適しています。
C++での代表的なライブラリはyaml-cppです。
例:yaml-cppを使った設定読み込み
#include <yaml-cpp/yaml.h>
#include <iostream>
#include <string>
struct Config {
int threshold;
double scaleFactor;
std::string inputPath;
};
Config loadConfig(const std::string& filename) {
Config config;
YAML::Node node = YAML::LoadFile(filename);
config.threshold = node["threshold"].as<int>();
config.scaleFactor = node["scale_factor"].as<double>();
config.inputPath = node["input_path"].as<std::string>();
return config;
}
int main() {
Config config = loadConfig("config.yaml");
std::cout << "Threshold: " << config.threshold << std::endl;
std::cout << "Scale Factor: " << config.scaleFactor << std::endl;
std::cout << "Input Path: " << config.inputPath << std::endl;
return 0;
}config.yamlの例
threshold: 128
scale_factor: 1.1
input_path: "images/input.jpg"このように、YAMLファイルから設定値を簡単に読み込み、プログラム内で利用できます。
JSON設定の取り込み
JSONは軽量で多くの環境でサポートされており、C++ではnlohmann/jsonライブラリが人気です。
例:nlohmann/jsonを使った設定読み込み
#include <nlohmann/json.hpp>
#include <fstream>
#include <iostream>
#include <string>
struct Config {
int threshold;
double scaleFactor;
std::string inputPath;
};
Config loadConfig(const std::string& filename) {
Config config;
std::ifstream ifs(filename);
nlohmann::json j;
ifs >> j;
config.threshold = j["threshold"];
config.scaleFactor = j["scale_factor"];
config.inputPath = j["input_path"];
return config;
}
int main() {
Config config = loadConfig("config.json");
std::cout << "Threshold: " << config.threshold << std::endl;
std::cout << "Scale Factor: " << config.scaleFactor << std::endl;
std::cout << "Input Path: " << config.inputPath << std::endl;
return 0;
}config.jsonの例
{
"threshold": 128,
"scale_factor": 1.1,
"input_path": "images/input.jpg"
}JSONもYAML同様に階層的な設定が可能で、用途に応じて使い分けます。
動的パラメータ変更フロー
実行中に設定パラメータを動的に変更できる仕組みは、開発効率や運用の柔軟性を高めます。
例えば、リアルタイムにしきい値や検出感度を調整したい場合に有効です。
動的変更の実装例
- 設定の監視
設定ファイルの変更を監視し、変更があったら再読み込みする方法があります。
Linuxならinotify、WindowsならReadDirectoryChangesWなどのAPIを使います。
- コマンドラインやGUIからの入力
実行中にコマンドライン引数やGUIのスライダー、テキストボックスでパラメータを変更し、即座に反映します。
- 共有データ構造の利用
設定値を格納する構造体やクラスをスレッドセーフに管理し、変更時にロックやアトミック操作で安全に更新します。
簡単な動的変更例(コマンドライン入力)
#include <iostream>
#include <atomic>
#include <thread>
#include <chrono>
std::atomic<int> threshold(128);
void parameterUpdater() {
while (true) {
std::cout << "新しいしきい値を入力してください(現在値: " << threshold.load() << "): ";
int newVal;
std::cin >> newVal;
if (newVal > 0 && newVal < 255) {
threshold.store(newVal);
std::cout << "しきい値を " << newVal << " に更新しました。\n";
} else {
std::cout << "無効な値です。\n";
}
}
}
int main() {
std::thread updater(parameterUpdater);
// メイン処理の例
for (int i = 0; i < 10; ++i) {
int currentThreshold = threshold.load();
std::cout << "現在のしきい値で処理中: " << currentThreshold << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(2));
}
updater.detach();
return 0;
}新しいしきい値を入力してください(現在値: 128): 150
しきい値を 150 に更新しました。
現在のしきい値で処理中: 150この例では別スレッドでユーザーからの入力を受け付け、メインスレッドの処理にリアルタイムで反映しています。
設定変更の反映タイミング
- 即時反映
パラメータ変更後すぐに処理に反映。
リアルタイム性が高いが同期処理が必要でしょう。
- バッチ反映
一定時間ごとや処理単位でまとめて反映。
安定性が高いが遅延が発生。
- トリガー制御
ユーザー操作や特定イベントで反映。
柔軟だが実装が複雑。
設定ファイルとコマンドライン引数を組み合わせ、動的にパラメータを変更できる設計にすることで、開発・運用の効率化とユーザーの利便性向上を実現できます。
テスト戦略
ユニットテスト
ユニットテストは、ソフトウェアの最小単位である関数やクラスの動作を個別に検証するテストです。
C++でOpenCVを使った自動化ツール開発においても、各モジュールの正確な動作を保証するために不可欠です。
- 目的
各関数やクラスが仕様通りに動作するかを確認し、バグの早期発見と修正を促進します。
- テスト対象例
- 画像前処理関数(色空間変換、リサイズ、ノイズ除去など)
- 解析モジュールのアルゴリズム(物体検出、輪郭抽出など)
- 入出力処理(画像読み込み、保存、設定ファイル読み込み)
- テストフレームワーク
Google Test(gtest)やCatch2などのC++向けテストフレームワークを利用すると、テストの記述や実行が効率的です。
- サンプルコード(Google Test)
#include <gtest/gtest.h>
#include <opencv2/opencv.hpp>
// 色空間変換関数のテスト例
cv::Mat convertToGray(const cv::Mat& src) {
cv::Mat gray;
cv::cvtColor(src, gray, cv::COLOR_BGR2GRAY);
return gray;
}
TEST(ImageProcessingTest, ConvertToGray) {
cv::Mat color = cv::imread("test_color.jpg");
ASSERT_FALSE(color.empty());
cv::Mat gray = convertToGray(color);
EXPECT_EQ(gray.channels(), 1);
EXPECT_EQ(gray.size(), color.size());
}
int main(int argc, char **argv) {
::testing::InitGoogleTest(&argc, argv);
return RUN_ALL_TESTS();
}- ポイント
- 入力画像はテスト用に固定し、結果のチャネル数やサイズ、ピクセル値の一部を検証します
- 境界値や異常入力(空画像、異常サイズ)もテストケースに含める
結合テスト
結合テストは、複数のモジュールやクラスを組み合わせて連携動作を検証するテストです。
ユニットテストで個別に動作確認した部品が、実際のパイプラインで正しく連携するかを確認します。
- 目的
モジュール間のインターフェースやデータの受け渡しに問題がないかを検証し、システム全体の動作を保証します。
- テスト対象例
- 入力モジュールから前処理、解析、出力までの一連の処理フロー
- 設定ファイル読み込みからパラメータ反映、処理実行までの流れ
- エラーハンドリングやログ出力の連携
- テスト方法
- 実際の画像や動画を使い、期待される解析結果や出力ファイルの有無を確認します
- モックやスタブを使って外部依存(ファイルシステム、カメラ)を切り離すこともあります
- サンプルシナリオ
- テスト用画像を入力としてパイプラインを実行。
- 出力画像に解析結果のオーバーレイが正しく描画されているか確認。
- CSVやJSONのレポートファイルが生成され、内容が期待通りか検証。
- 自動化
CI環境で結合テストを自動実行し、ビルドの品質を継続的に監視することが望ましい。
パフォーマンステスト
パフォーマンステストは、処理速度やリソース消費を測定し、要求される性能を満たしているかを評価するテストです。
特にリアルタイム処理や大量データ処理を行う自動化ツールでは重要です。
- 目的
- 処理時間(レイテンシ、スループット)の測定
- CPU・メモリ・GPU使用率の監視
- ボトルネックの特定と最適化指針の提供
- テスト項目例
- 1フレームあたりの処理時間(平均・最大)
- バッチ処理全体の所要時間
- マルチスレッド化やGPU活用の効果測定
- 測定方法
- C++標準の
std::chronoやOpenCVのcv::TickMeterで時間計測 - OSのプロファイラやタスクマネージャでリソース監視
- ログに処理時間を記録し、後から解析
- C++標準の
- サンプルコード(処理時間計測)
#include <opencv2/opencv.hpp>
#include <iostream>
#include <chrono>
int main() {
cv::Mat image = cv::imread("input.jpg");
if (image.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
auto start = std::chrono::high_resolution_clock::now();
cv::Mat gray;
cv::cvtColor(image, gray, cv::COLOR_BGR2GRAY);
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> elapsed = end - start;
std::cout << "グレースケール変換にかかった時間: " << elapsed.count() << " ms" << std::endl;
return 0;
}- パフォーマンス改善のポイント
- アルゴリズムの選定とパラメータ調整
- OpenCVの最適化フラグやSIMD命令の活用
- マルチスレッド化やGPUアクセラレーションの導入
これらのテスト戦略を組み合わせて実施することで、品質の高い自動化ツールを安定的に開発・運用できます。
CI/CDと自動ビルド
GitHub Actionsワークフロー例
GitHub ActionsはGitHubリポジトリに統合されたCI/CDツールで、コードのビルドやテスト、デプロイを自動化できます。
C++とOpenCVを使った自動化ツールの開発においても、プッシュやプルリクエスト時に自動ビルドとテストを実行することで品質を保てます。
以下は、CMakeを使ったC++プロジェクトのビルドとGoogle Testによるテスト実行を行うGitHub Actionsのワークフロー例です。
name: C++ CI
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
build-and-test:
runs-on: ubuntu-latest
steps:
- name: ソースコードのチェックアウト
uses: actions/checkout@v3
- name: CMakeのセットアップ
uses: jwlawson/actions-setup-cmake@v1
- name: OpenCVのインストール
run: |
sudo apt-get update
sudo apt-get install -y libopencv-dev
- name: ビルドディレクトリ作成
run: mkdir build
- name: CMakeでビルド設定
run: cmake -S . -B build
- name: ビルド実行
run: cmake --build build --config Release
- name: テスト実行
run: ctest --test-dir build --output-on-failureこのワークフローは以下の流れで動作します。
mainブランチへのプッシュやプルリクエストをトリガーに起動- ソースコードをチェックアウト
- CMakeをセットアップ
- Ubuntu環境にOpenCVをインストール
- ビルド用ディレクトリを作成し、CMakeでビルド設定
- ビルドを実行
- Google Testなどのテストを実行し、失敗時はログを表示
WindowsやmacOSでのビルドも必要な場合は、runs-onを変更し、複数のジョブを定義してクロスプラットフォーム対応が可能です。
テスト自動実行とバッジ表示
CI環境でテストを自動実行することで、コードの品質を継続的に監視できます。
GitHub Actionsのワークフローにテスト実行を組み込むと、プルリクエスト時に自動でテストが走り、問題があれば早期に検知可能です。
テスト自動実行のポイント
- テスト失敗時の通知
GitHubのプルリクエスト画面でテスト結果が表示され、失敗した場合はマークが付くため、レビュアーや開発者がすぐに気づけます。
- 詳細ログの確認
テスト失敗時はGitHub Actionsのログから原因を特定しやすく、修正が迅速に行えます。
- 並列テスト実行
複数のテストを並列で実行し、CIの待ち時間を短縮可能です。
バッジ表示
GitHubリポジトリのREADMEなどにビルド・テストの状態を示すバッジを表示すると、プロジェクトの健康状態を一目で把握できます。
バッジの例
ci.ymlはワークフローのファイル名に合わせて変更してください- バッジはGitHub Actionsのワークフロー画面からURLを取得できます
表示例
![]()
このバッジはビルドとテストが成功している場合は緑色、失敗している場合は赤色で表示されます。
CI/CDと自動ビルドを導入することで、コードの品質維持と開発効率の向上が期待できます。
GitHub Actionsは設定が比較的簡単で、無料枠も充実しているため、積極的に活用しましょう。
パフォーマンス最適化
SIMDとOpenCV最適化フラグ
SIMD(Single Instruction Multiple Data)は、CPUが複数のデータを同時に処理する命令セットの総称で、画像処理の高速化に非常に効果的です。
OpenCVは内部でSIMD命令を活用しており、開発者は適切なコンパイルオプションを設定することで最適化を最大限に引き出せます。
- 代表的なSIMD命令セット
- SSE(Streaming SIMD Extensions)
- AVX(Advanced Vector Extensions)
- NEON(ARMアーキテクチャ向け)
- OpenCVの最適化フラグ
OpenCVはビルド時にCPUのSIMD命令を検出し、自動的に最適化コードを有効化します。
CMakeでビルドする際に以下のオプションを指定すると良いでしょう。
cmake -D CMAKE_BUILD_TYPE=Release -D ENABLE_SSE=ON -D ENABLE_AVX=ON ..- コンパイラ最適化フラグ
コンパイラ側でも最適化フラグを有効にします。
例えばGCCやClangでは以下のように指定します。
-O3 -march=native -mtune=nativeこれにより、CPUの命令セットに合わせた最適化が行われます。
- 効果の確認
OpenCVのgetBuildInformation()関数でビルド時の最適化状況を確認できます。
std::cout << cv::getBuildInformation() << std::endl;- 注意点
SIMD最適化はCPU依存のため、異なる環境での互換性を考慮しつつ設定してください。
マルチスレッド実装
マルチスレッド化は、複数のCPUコアを活用して処理を並列化し、スループットを向上させる手法です。
OpenCV自体も内部でマルチスレッドを利用していますが、アプリケーションレベルでの並列処理設計も重要です。
- OpenCVの並列化サポート
OpenCVはTBB(Intel Threading Building Blocks)やOpenMP、C++17の並列アルゴリズムを利用可能です。
ビルド時に有効化すると内部処理が高速化されます。
- アプリケーションでのマルチスレッド例
画像の読み込み、前処理、解析、出力を別スレッドで処理するパイプラインを構築し、各処理を並列化します。
- C++標準スレッドの利用例
#include <thread>
#include <vector>
#include <opencv2/opencv.hpp>
void processImage(const cv::Mat& img, int id) {
cv::Mat gray;
cv::cvtColor(img, gray, cv::COLOR_BGR2GRAY);
std::cout << "Thread " << id << " processed image size: " << gray.size() << std::endl;
}
int main() {
std::vector<cv::Mat> images = {
cv::imread("img1.jpg"),
cv::imread("img2.jpg"),
cv::imread("img3.jpg")
};
std::vector<std::thread> threads;
for (int i = 0; i < images.size(); ++i) {
if (!images[i].empty()) {
threads.emplace_back(processImage, images[i], i);
}
}
for (auto& t : threads) {
t.join();
}
return 0;
}- 注意点
- 共有リソースの排他制御(ミューテックスなど)を適切に行います
- スレッド数はCPUコア数に合わせて調整します
- スレッドの生成・破棄コストを考慮し、スレッドプールの利用も検討します
GPU活用とcv::cuda
GPUは大量の並列演算に優れており、画像処理の高速化に非常に効果的です。
OpenCVはCUDA対応モジュール(cv::cuda名前空間)を提供しており、対応GPUがあれば簡単にGPUアクセラレーションを利用できます。
- CUDAモジュールの特徴
- 画像のアップロード・ダウンロードは
cv::cuda::GpuMatを使います - 多くの画像処理関数がCUDA対応版として用意されている(例:
cv::cuda::cvtColor、cv::cuda::GaussianBlur) - DNN推論もCUDA対応で高速化可能です
- 画像のアップロード・ダウンロードは
- 簡単なGPU処理例
#include <opencv2/opencv.hpp>
#include <opencv2/cudaimgproc.hpp>
#include <iostream>
int main() {
cv::Mat src = cv::imread("input.jpg");
if (src.empty()) {
std::cerr << "画像の読み込みに失敗しました。" << std::endl;
return -1;
}
cv::cuda::GpuMat gpuSrc, gpuGray;
gpuSrc.upload(src);
cv::cuda::cvtColor(gpuSrc, gpuGray, cv::COLOR_BGR2GRAY);
cv::Mat gray;
gpuGray.download(gray);
cv::imshow("GPU Grayscale", gray);
cv::waitKey(0);
return 0;
}- CUDA対応ビルド
OpenCVをCUDA対応でビルドする必要があります。
CMakeでWITH_CUDA=ONを指定し、CUDA SDKがインストールされている環境でビルドします。
- パフォーマンスのポイント
- GPUとCPU間のデータ転送はコストが高いため、できるだけGPU上で処理を完結させます
- 複数のGPUを使う場合はデバイス管理を適切に行います
- CUDAカーネルの最適化やストリームを活用した非同期処理も検討
- 注意点
- CUDA対応はGPU環境に依存するため、環境がない場合はフォールバック処理を用意します
- OpenCVのCUDAモジュールはすべての関数が対応しているわけではないため、必要な処理が対応しているか確認します
これらのパフォーマンス最適化手法を組み合わせることで、C++とOpenCVを用いた自動化ツールの処理速度を大幅に向上させることが可能です。
開発環境や用途に応じて適切な手法を選択し、効果的に活用してください。
クロスプラットフォーム対応
WindowsとLinuxの差異吸収
C++とOpenCVを用いた自動化ツールをWindowsとLinuxの両環境で動作させる場合、OS固有の差異を吸収し、共通コードで動作させることが重要です。
以下に主な差異とその吸収方法を解説します。
ファイルパスの扱い
- 差異
Windowsはパス区切り文字にバックスラッシュ\を使い、Linuxはスラッシュ/を使います。
また、Windowsはドライブレター(例:C:\)があり、Linuxはルートディレクトリ/から始まります。
- 対策
- C++17以降の
std::filesystemを使うと、OSに依存しないパス操作が可能です - 文字列でパスを扱う場合は、スラッシュ
/を使うとWindowsでも問題なく動作します - パス結合は
std::filesystem::pathのoperator/を使うと安全です
- C++17以降の
#include <filesystem>
namespace fs = std::filesystem;
fs::path inputDir = "data";
fs::path fileName = "image.jpg";
fs::path fullPath = inputDir / fileName; // OSに応じて適切に結合される改行コード
- 差異
WindowsはCR+LF\r\n、LinuxはLF\nを改行コードとして使います。
テキストファイルの読み書きで問題になることがあります。
- 対策
- テキストファイルはバイナリモードでなく標準のテキストモードで開きます
- ファイルフォーマットを統一し、必要に応じて改行コード変換ツールを使います
コンパイラとビルド環境
- 差異
WindowsはVisual Studio(MSVC)、LinuxはGCCやClangが主流で、コンパイラ固有の拡張や警告が異なります。
- 対策
- CMakeなどのクロスプラットフォームビルドシステムを使い、ビルド設定を共通化
- コンパイラ固有のコードはプリプロセッサディレクティブ(
#ifdef _WIN32など)で分岐 - 標準C++に準拠したコードを書くことを心がける
OS固有APIの利用
- 差異
ファイル監視、スレッド管理、GUIなどでOS固有APIを使う場合、実装が異なります。
- 対策
- BoostやQtなどのクロスプラットフォームライブラリを利用
- OSごとに抽象化レイヤーを設け、インターフェースを共通化
- 可能な限り標準C++やOpenCVのAPIで代替
ライブラリの依存関係
- 差異
ライブラリのインストール方法やパスが異なります。
例:WindowsはDLL、Linuxは.soファイル。
- 対策
- CMakeの
find_packageやpkg-configを活用し、環境に応じて適切にリンク - 動的ライブラリのパス設定を環境変数で管理
- CMakeの
macOSへの展開ポイント
macOSはUnix系OSでLinuxに近い部分も多いですが、独自の特徴や注意点があります。
C++とOpenCVの自動化ツールをmacOSに展開する際のポイントをまとめます。
OpenCVのインストール
- Homebrewを使うのが一般的です
brew install opencv- インストール後、CMakeで
find_package(OpenCV REQUIRED)が正常に動作するように環境変数PKG_CONFIG_PATHを設定する場合があります
フレームワークとライブラリの扱い
- macOSは
.dylibや.framework形式のライブラリを使います - OpenCVはフレームワークとしてインストールされることもあり、リンク設定に注意が必要です
GUI表示の注意点
- OpenCVの
cv::imshowはmacOSのネイティブウィンドウを使いますが、XQuartzなどのX11環境が必要な場合もあります - macOSのセキュリティ設定でカメラアクセス許可が必要な場合があります
ファイルシステムの特徴
- macOSは大文字・小文字を区別しないファイルシステムがデフォルトですが、区別する設定も可能です
- パスの扱いはLinuxと同様に
/区切り
ビルド環境
- XcodeやClangが標準コンパイラ
- CMakeで
-G Xcodeを指定してXcodeプロジェクトを生成可能です - macOS固有のフラグやライブラリ(例:
-framework Cocoa)をリンクに追加する場合があります
デバッグとパフォーマンス
- InstrumentsやActivity Monitorでリソース使用状況を監視可能です
- MetalやOpenCLを使ったGPUアクセラレーションも検討できるが、OpenCVのCUDA対応はmacOSでは限定的
これらのポイントを踏まえ、Windows、Linux、macOSの差異を吸収しつつ、共通コードベースで開発・展開することで、クロスプラットフォーム対応の自動化ツールを効率的に構築できます。
UI統合オプション
CLIツール化
CLI(Command Line Interface)ツールは、コマンドラインから操作できるシンプルかつ軽量なインターフェースです。
C++とOpenCVで自動化ツールを開発する際、まずはCLI化することでスクリプトやバッチ処理との連携が容易になります。
- 特徴
- GUI不要でリモート環境やサーバー上でも動作可能
- バッチ処理や自動化スクリプトに組み込みやすい
- 入力パラメータはコマンドライン引数や設定ファイルで指定
- コマンドライン引数の解析
C++標準ではargc、argvを使いますが、Boost.Program_optionsやcxxoptsなどのライブラリを使うと便利です。
- サンプルコード(cxxopts使用例)
#include <cxxopts.hpp>
#include <iostream>
int main(int argc, char* argv[]) {
cxxopts::Options options("ImageTool", "画像処理自動化ツール");
options.add_options()
("i,input", "入力画像ファイル", cxxopts::value<std::string>())
("o,output", "出力画像ファイル", cxxopts::value<std::string>()->default_value("output.jpg"))
("h,help", "ヘルプ表示");
auto result = options.parse(argc, argv);
if (result.count("help") || !result.count("input")) {
std::cout << options.help() << std::endl;
return 0;
}
std::string inputFile = result["input"].as<std::string>();
std::string outputFile = result["output"].as<std::string>();
std::cout << "入力ファイル: " << inputFile << std::endl;
std::cout << "出力ファイル: " << outputFile << std::endl;
// ここに画像処理コードを実装
return 0;
}- 利点
- 簡単に自動化パイプラインに組み込める
- リソース消費が少なく高速起動可能
QtによるGUI
Qtはクロスプラットフォーム対応のC++ GUIフレームワークで、リッチなユーザーインターフェースを構築できます。
OpenCVと組み合わせて画像処理ツールのGUI化に最適です。
- 特徴
- ボタン、スライダー、テキスト入力など多彩なウィジェットを利用可能
- 画像表示は
QLabelやQGraphicsViewにOpenCVのcv::MatをQImageに変換して表示 - シグナル・スロット機構でイベント駆動型プログラミングが容易
- OpenCV画像をQtで表示する例
#include <QApplication>
#include <QLabel>
#include <QImage>
#include <opencv2/opencv.hpp>
QImage cvMatToQImage(const cv::Mat& mat) {
if (mat.type() == CV_8UC3) {
cv::Mat rgb;
cv::cvtColor(mat, rgb, cv::COLOR_BGR2RGB);
return QImage((const unsigned char*)rgb.data, rgb.cols, rgb.rows, rgb.step, QImage::Format_RGB888).copy();
} else if (mat.type() == CV_8UC1) {
return QImage((const unsigned char*)mat.data, mat.cols, mat.rows, mat.step, QImage::Format_Grayscale8).copy();
}
return QImage();
}
int main(int argc, char *argv[]) {
QApplication app(argc, argv);
cv::Mat image = cv::imread("input.jpg");
if (image.empty()) return -1;
QImage qimg = cvMatToQImage(image);
QLabel label;
label.setPixmap(QPixmap::fromImage(qimg));
label.show();
return app.exec();
}- GUIの利点
- ユーザーが直感的に操作可能
- パラメータ調整や結果確認がリアルタイムでできる
- 複雑な処理の可視化に適している
- 開発ポイント
- メインスレッドでGUIを動かし、画像処理は別スレッドで実行してUIの応答性を保つ
- 設定保存やロード機能を実装し、ユーザーの操作履歴を管理
Webフロント連携
Webフロントエンドと連携することで、ブラウザから操作可能な画像処理ツールを構築できます。
C++のバックエンドとWeb UIを分離し、REST APIやWebSocketで通信する形が一般的です。
- 構成例
- バックエンド:C++でOpenCV処理を実装し、HTTPサーバー(例:Crow、Pistache、cpp-httplib)を立てる
- フロントエンド:HTML/CSS/JavaScriptでUIを作成し、API経由で画像アップロードや処理指示を送信
- メリット
- OSや環境に依存せず、どこからでもアクセス可能
- 複数ユーザーで共有しやすい
- UIの更新や拡張が容易
- 簡単なバックエンド例(cpp-httplib)
#include <httplib.h>
#include <opencv2/opencv.hpp>
#include <iostream>
int main() {
httplib::Server svr;
svr.Post("/process", [](const httplib::Request& req, httplib::Response& res) {
// 画像データを受け取りOpenCVで処理(省略)
// 処理結果を返す
res.set_content("処理完了", "text/plain");
});
std::cout << "サーバー起動: http://localhost:8080" << std::endl;
svr.listen("0.0.0.0", 8080);
return 0;
}- フロントエンド例
JavaScriptのfetch APIで画像を送信し、結果を受け取ります。
- 注意点
- 画像のアップロード・ダウンロードに伴う帯域や遅延を考慮
- セキュリティ(認証・認可、入力検証)を適切に実装
- スケーラビリティや負荷分散を検討
これらのUI統合オプションを用途やユーザー層に応じて選択し、C++とOpenCVの自動化ツールに最適な操作環境を提供しましょう。
配布とバージョニング
バイナリ配布形式
C++とOpenCVを用いた自動化ツールの配布において、ユーザーが手軽に利用できるバイナリ形式を選択することは重要です。
配布形式はターゲット環境やユーザー層に応じて最適なものを選びます。
代表的なバイナリ配布形式
- スタンドアロン実行ファイル
- 単一の実行ファイル(.exeやELFなど)として配布
- 依存ライブラリを静的リンクするか、同梱する必要があります
- ユーザーは追加インストール不要で簡単に実行可能です
- インストーラ形式
- WindowsならMSIやInno Setup、LinuxならDEBやRPMパッケージ
- 依存関係の解決やショートカット作成などを自動化できます
- ユーザーにとって導入が容易
- アーカイブ形式(ZIP、tar.gzなど)
- 実行ファイルや必要なDLL/soファイルをまとめて圧縮
- ユーザーが解凍して使う形式
- 簡単だが依存関係の管理はユーザー任せになります
- コンテナイメージ(Dockerなど)
- 実行環境を含めて配布可能です
- 環境差異を吸収し、動作保証が高いでしょう
- サーバーやクラウド環境向け
配布時の注意点
- 依存ライブラリの同梱
OpenCVや他の外部ライブラリが動作環境にない場合、同梱や静的リンクで対応。
WindowsではDLLの配置場所に注意。
- プラットフォーム別ビルド
Windows、Linux、macOSそれぞれに対応したバイナリを用意。
クロスコンパイルやCIで自動ビルドを活用。
- ドキュメントの同梱
インストール手順や使い方をREADMEやマニュアルとして同梱。
- 署名とセキュリティ
Windowsのコード署名やLinuxのパッケージ署名で信頼性を向上。
セマンティックバージョニング方針
バージョニングはソフトウェアのリリース管理に不可欠で、ユーザーや開発者が変更内容や互換性を理解しやすくなります。
セマンティックバージョニング(SemVer)は広く採用されている標準的な方式です。
セマンティックバージョニングの基本構成
MAJOR.MINOR.PATCH- MAJOR(メジャー)
後方互換性のない大きな変更を加えた場合に増加。
例:APIの破壊的変更、新機能の大幅な仕様変更。
- MINOR(マイナー)
後方互換性を保った機能追加や改善を行った場合に増加。
例:新しい解析アルゴリズムの追加、UIの拡張。
- PATCH(パッチ)
バグ修正や小さな改善を行った場合に増加。
例:不具合の修正、パフォーマンスの微調整。
バージョニング運用のポイント
- 初期リリースは0.x.x
開発段階では0.x.xを使い、安定版リリース時に1.0.0に設定。
- プレリリース・ビルドメタデータ
1.0.0-beta.1や1.0.0+build.123のように、ベータ版やビルド番号を付加可能です。
- バージョン番号の管理
GitタグやCI/CDパイプラインで自動付与すると管理が楽。
- ドキュメントと連携
リリースノートにバージョンごとの変更点を明記し、ユーザーに周知。
| バージョン | 内容例 |
|---|---|
| 1.0.0 | 初の安定版リリース |
| 1.1.0 | 新しい物体検出アルゴリズムを追加 |
| 1.1.1 | バグ修正とパフォーマンス改善 |
| 2.0.0 | APIの大幅変更により後方互換性を破壊 |
バイナリ配布形式とセマンティックバージョニングを適切に運用することで、ユーザーにとって使いやすく、開発チームにとって管理しやすい自動化ツールのリリース体制を構築できます。
今後の拡張アイデア
AIモデルの自動更新
自動化ツールに組み込まれたAIモデルは、時間の経過とともに環境変化や新しいデータに対応するため、定期的な更新が必要です。
AIモデルの自動更新機能を実装することで、常に最新の性能を維持し、メンテナンス負荷を軽減できます。
- モデルのバージョン管理
モデルファイルにバージョン情報を付与し、更新履歴を管理します。
これにより、どのバージョンのモデルが使われているかを明確にできます。
- リモートサーバからのダウンロード
新しいモデルが公開された際に、ツールが自動的にリモートサーバ(HTTP/HTTPS、FTPなど)から最新モデルをダウンロードし、ローカルに保存します。
- 更新の検知と適用
起動時や定期的なタイミングでモデルのバージョンをチェックし、差分があれば更新を実行。
更新後は新モデルを即座に読み込んで推論に利用します。
- 安全性の確保
ダウンロードしたモデルの整合性チェック(ハッシュ検証や署名検証)を行い、不正なファイルの適用を防止します。
- ユーザー通知とロールバック
更新内容をユーザーに通知し、問題があった場合は前バージョンにロールバックできる仕組みを用意します。
- 実装例のイメージ
bool checkForUpdate(const std::string& currentVersion);
bool downloadModel(const std::string& url, const std::string& savePath);
bool verifyModel(const std::string& filePath);
void loadModel(const std::string& filePath);この自動更新機能により、AIモデルの性能劣化を防ぎ、常に最適な解析結果を提供できます。
クラウド連携
クラウド連携は、自動化ツールの機能拡張や運用効率化に大きな可能性をもたらします。
クラウドサービスを活用することで、計算リソースの拡張、データの一元管理、遠隔監視などが実現可能です。
- クラウドストレージ連携
解析対象の画像や動画、解析結果をAWS S3やGoogle Cloud Storageなどにアップロード・ダウンロードし、データ共有やバックアップを自動化します。
- クラウド上での解析
処理負荷の高いAI推論や大規模バッチ処理をクラウドのGPUインスタンスで実行し、ローカル環境の負荷を軽減します。
- API連携
REST APIやgRPCを通じてクラウドサービスと通信し、解析結果の送信やジョブ管理を行います。
- リアルタイム監視と通知
クラウドの監視ツール(CloudWatch、Stackdriverなど)と連携し、異常検知や処理状況をリアルタイムで把握。
メールやチャットツールへの通知も可能です。
- セキュリティ対策
通信の暗号化、認証・認可の実装、アクセス制御を徹底し、データの安全性を確保します。
- スケーラビリティ
クラウドのオートスケーリング機能を活用し、負荷に応じて処理リソースを動的に増減可能です。
- 実装例のイメージ
void uploadToCloud(const std::string& localPath, const std::string& cloudPath);
void downloadFromCloud(const std::string& cloudPath, const std::string& localPath);
std::string invokeCloudInference(const std::string& inputData);クラウド連携により、分散処理や大規模データの管理が容易になり、運用の柔軟性が大幅に向上します。
エッジデバイス最適化
エッジデバイス(IoT機器や組み込みシステム)での自動化ツール運用は、低消費電力・低遅延・ネットワーク負荷軽減の観点から注目されています。
エッジデバイス向けに最適化することで、現場でのリアルタイム処理やオフライン動作が可能になります。
- 軽量モデルの利用
モバイル向けや組み込み向けに設計された軽量なAIモデル(例:TensorFlow Lite、ONNX Runtime Mobile)を採用し、推論速度とメモリ使用量を削減します。
- ハードウェアアクセラレーション
エッジデバイスのGPU、NPU、DSPなど専用ハードウェアを活用し、処理効率を向上。
OpenCVのcv::cudaや各種ベンダーのSDKを利用します。
- リソース制約への対応
CPU性能やメモリ容量が限られる環境に合わせて、画像解像度の調整や処理アルゴリズムの軽量化を行います。
- 省電力設計
処理のバッチ化やスリープモードの活用で消費電力を抑制し、長時間稼働を実現。
- ネットワーク負荷の軽減
必要なデータのみをクラウドに送信し、帯域幅を節約。
ローカルでの前処理や解析を優先。
- OTA(Over-The-Air)アップデート
エッジデバイスのソフトウェアやモデルを遠隔で更新し、メンテナンス性を向上。
- 実装例のイメージ
void runInferenceOnEdge(const cv::Mat& input);
void optimizeModelForEdge(const std::string& modelPath);
void managePowerConsumption(bool enableLowPowerMode);エッジデバイス最適化により、現場での即時性と安定性を確保しつつ、クラウドとの連携も柔軟に行えるシステム構築が可能です。
まとめ
本記事では、C++とOpenCVを用いた自動化ツール開発の全体像を詳しく解説しました。
ゴール設定から要件定義、データフロー設計、主要API選定、クラス設計、ファイル構成、画像入出力、前処理、解析、結果出力、エラーハンドリング、設定管理、テスト戦略、CI/CD、パフォーマンス最適化、クロスプラットフォーム対応、UI統合、配布・バージョニング、そして今後の拡張アイデアまで幅広くカバーしています。
これにより、実践的かつ拡張性の高い自動化ツールの設計・開発手法が理解でき、効率的な開発を進めるための指針が得られます。